
Как изменять правила фильтрации данных без перезапуска потокового Flink-приложения: практический пример для разработчиков и дата-инженеров. Чем подход с ключами состояний отличается от широковещательных соединений, каковы достоинства и недостатки этих альтернатив. Фильтрация данных в статике и динамике Практически каждая платформа потоковой передачи событий позволяет использовать фильтрацию операторов для отбора данных согласно...

В этой статье для дата-инженеров и администраторов кластера рассмотрим, как считать данные из распределенной файловой системы Apache Hadoop в MPP-СУБД Greenplum. Архитектура и принцип работы PXF-коннектора к HDFS с примерами команд. Интеграция Greenplum и Hadoop через PXF-коннекторы Мы уже писали, что представляет собой интеграционный фреймворк PXF (Platform Extension Framework), который...

Сегодня заглянем под капот Apache Spark и разберем, для чего этому популярному вычислительному движку база метаданных, как ее назначить и что не так с хранилищем данных по умолчанию. Зачем уходить от Apache Derby к Hive и как это сделать: краткий ликбез с примерами для обучения дата-инженеров и разработчиков распределенных приложений....

Продолжая разговор про импортозамещение, сегодня рассмотрим новый продукт от «Аренадата Софтвер» - разработчика широкой линейки российских решений для хранения и аналитики больших данных. Компания адаптирует открытые дистрибутивы Big Data фреймворков к специфике корпоративного использования и предоставляет русскоязычную поддержку 24/7. Что такое Arenadata Postgres, кому и зачем нужен этот продукт, и...
Чтобы на наглядном примере показать, чем Apache NiFi полезен для дата-инженера, сегодня рассмотрим практический кейс построения простого ETL-конвейера. Как собрать данные из разных API, записать их в СУБД и отправить уведомление о результатах с готовыми процессорами NiFi. Постановка задачи: ETL-конвейер тревел-приложения В качестве примера рассмотрим корпоративное приложение для путешественников, которое...
В этой статье для дата-инженеров и аналитиков данных, рассмотрим, что такое широковещательные соединение в Apache Spark SQL, чем оно полезно и как работает на практических примерах. BROADCAST JOIN в SELECT-запросах Spark SQL, а также краткий ликбез по подсказкам или хинтам. Что такое широковещательное соединение в Apache Spark SQL Распределенная природа...

Сегодня разберем опыт австралийской ИТ-компании hipages по построению самообслуживаемого ETL-конвейера с Apache Airflow и Amazon Athena, призванного обеспечить высокое качество данных и облегчить дата-инженерам управление информационными активами. Изящное решение сложных проблем управления данными с примерами SQL-запросов к корпоративному Data Lake на AWS S3. Что не так с монолитной архитектурой платформы данных...

15 марта 2022 года вышло очередное обновление MPP-СУБД VMware Tanzu Greenplum, в основе которой лежит одноименный open-source проект. Читайте далее, какие новые фичи добавлены в выпуск 6.20 и что за проблемы устранены в этом минорном релизе. Самое главное: краткий обзор новых фич Greenplum 6.20 Greenplum 6.20.0 включает следующие новые и...
Что такое MSCK REPAIR TABLE в Apache Hive, зачем нужна эта команда, ее достоинства и недостатки, а также альтернативные варианты для задач пакетной дата-инженерии. Разбираем на примере конвейера обработки данных в ML-приложениях при работе с Data Lake. Команда MSCK REPAIR TABLE в Apache Hive В ML-приложениях особенно важно, как озеро данных (Data...

Сегодня заглянем под капот Tanzu Greenplum Text: архитектура и принципы работы этого средства поиска и анализа текстов, интегрированного с популярной MPP-СУБД. Как движок наподобие Elasticsearch связывает кластер Apache Solr с базой данных Greenplum и зачем здесь нужен Zookeeper. Что такое Tanzu Greenplum Text Мы уже рассказывали про основные функциональные возможности...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop рассмотрим, что такое Cloudera Data Platform Operational Database, как это связано с Apache HBase и Phoenix. Также разберем, каким образом перенести данные из кластера HBase в Cloudera Operational Database, избежав их потери и других подводных камней. Что такое Cloudera Operational Database: назначение...

Что такое Hive Transform, зачем это нужно дата-инженеру и разработчику распределенных приложений, где и как использовать эту функцию популярного средства SQL-on-Hadoop. Краткий обзор альтернативного способа операций с данными в Apache Hive, его возможности и ограничения, а также связь с HiveQL. Преобразования в Apache Hive Apache Hive – это популярная экосистема...
Сегодня рассмотрим, как использовать статистический язык R для анализа данных в Greenplum. Что такое GreenplumR, как работает этот интерактивный клиент, чем он полезен специалисту по Data Science и каковы недостатки этого инструмента аналитики больших данных. Что такое GreenplumR Хотя основным языком в области Data Science сегодня считается Python, иногда специалисты...
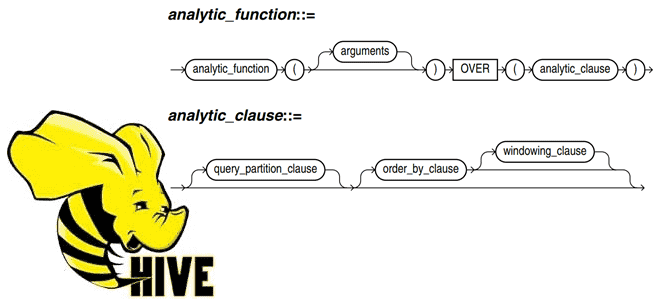
Постоянно добавляя в наши курсы по SQL-on-Hadoop для дата-инженеров и разработчиков распределенных приложений интересные примеры, сегодня рассмотрим пару практических техник по работе с Apache Hive. Читайте далее, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank(). Генерация порядкового номера строки...

Недавно на примере ИТ-компании Salesforce мы рассказывали про вторичную индексацию таблиц Apache HBase с помощью Phoenix – средства обращения к NoSQL-хранилищу через SQL-запросы. В продолжение этого кейса, сегодня рассмотрим, как были перепроектированы глобальные вторичные индексы для обеспечения более высокого уровня согласованности, чем предлагает Apache Phoenix. Реализация вторичных индексов в таблицах...

Добавляя в наши курсы для дата-инженеров интересные кейсы, сегодня рассмотрим, как реализовать Лямбда-архитектуру для комплексной аналитики больших данных с помощью Apache Flink, Kafka и Cassandra на примере системы интернета вещей. Объединение пакетной и потоковой обработки данных средствами Flink API и библиотек этого фреймворка. Постановка задачи на примере IoT-системы Несмотря на...

В Apache HBase индексация таблиц возможна только по одному полю. Обойти это ограничение позволяет Apache Phoenix - инструмент обращения к NoSQL-хранилищу средствами SQL-запросов. В этой статье для дата-инженеров, архитекторов ИТ-решений и аналитиков данных рассмотрим типы вторичной индексации таблиц HBase в Phoenix и проблемы согласованности вторичных индексов, с которыми столкнулись специалисты...

Мы уже рассказывали про связь Greenplum с другими источниками и приемниками данных с помощью PXF-фреймворка, а также отдельных коннекторов к некоторым системам. Сегодня рассмотрим, какие вообще есть коннекторы данных в этой MPP-СУБД и что такое Tanzu Greenplum Text. Коннекторы и фреймворки для интеграции GP и Arenadata DB с внешними системами...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop, рассмотрим, что такое Trino и как это работает с Apache Hive. А также при чем здесь Presto и зачем коннектор со своей средой выполнения использует Hive Metastore. Что такое Trino и при чем здесь Presto SQL Trino – это механизм запросов для...

Для дата-инженеров и аналитиков про манипулирование данными в Apache Hadoop HDFS средствами SQL-запросов с помощью удобных инструментов. Apache Phoenix для обращения к таблицам NoSQL-хранилища HBase через SQL-запросы из графического интерфейса Hue. Как обратиться к таблицам HBase через SQL-запросы с Phoenix Apache HBase как хранилище данных над Hadoop HDFS предоставляет множество...