
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим особенности обработки пакетных транзакций в популярной графовой СУБД Neo4j . Когда вместо простых запросов встроенного SQL-подобного языка Cypher лучше использовать процедуры библиотеки APOC, чтобы избежать проблем с памятью или остановки обновлений. OOM, большие графы и пакетные транзакции в Neo4j...

Как писать UDF-функции Greenplum на Python: краткий обзор расширения PL/Python для дата-инженера и разработчика распределенных приложений. Как его установить, настроить и использовать: сопоставления типов данных, SQL-запросы, модули и функции. Поддержка Python в MPP-СУБД Поскольку освоить Python намного проще других языков программирования, например, Java или C#, неудивительно, что он сегодня очень...

Что такое архитектура данных, какие модели чаще всего используются в современных Big Data системах, почему традиционные BI-системы не справляются со всем разнообразием текущих бизнес-сценариев, чем Лямбда отличается от Каппа, а Data Fabric от Data Mesh и зачем внедрять MLOps-инструменты в аналитическую платформу. Немного истории: почему архитектуры данных до сих пор...

Что такое Tungsten, зачем он нужен в Apache Spark и как этот проект устраняет узкие места вычислительного движка, чтобы повысить его производительность и эффективность утилизации ресурсов за счет приближения JVM к bare metal. Рассматриваем самые важные для разработчика распределенных приложений особенности и разбираемся, при чем здесь вольфрам и почему с...
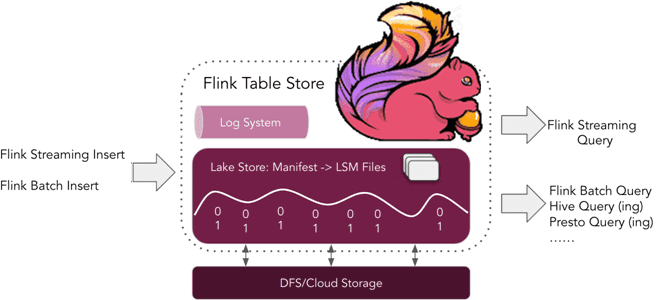
Что такое табличное хранилище Apache Flink, зачем это нужно и почему оно пока не рекомендуется для применения в реальных проектах. Краткий обзор Apache Flink Table Store 0.1.0 для дата-инженеров и разработчиков распределенных приложений. Что такое Flink Table Store и зачем это нужно Уже более полугода, с релиза 1.14, выпущенного в...

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...

Весна богата на новые релизы: в начале мая 2022 года вышел Apache Flink 1.15. Рассказываем, что нового в свежем выпуске: краткий обзор самых полезных фич для разработчика распределенных приложений, а также интересные изменения, исправления ошибок и улучшения для дата-инженера. Scala под капотом и спецификация REST API по стандарту OpenAPI Apache...

Специально для обучения начинающих аналитиков данных и дата-инженеров сегодня рассмотрим примеры выполнения простых SQL-запросов и оконных функций в Apache Spark на Google Colab. Как быстро проанализировать датафрейм из CSV-файлов с помощью нескольких строк на PySpark. Запуск и использование PySpark в Google Colab Предположим, необходимо определить потенциальный доход от проведения обучающих...

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi. Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт)....
Мы уже рассматривали, как загрузить в Greenplum большие объемы данных. В продолжение этой важной для обучения дата-инженеров темы, сегодня разберем еще несколько инструментов, решающих задачу организации ETL-процессов с этой MPP-СУБД. ETL-инструменты PostgreSQL Хотя Greenplum может хранить и обрабатывать огромные наборы данных на уровне петабайт, эта СУБД не генерирует их самостоятельно,...
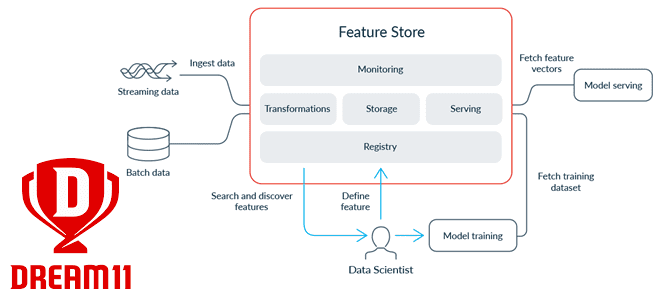
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...

В рамках практического обучения аналитиков данных и специалистов по Data Science реальным задачам современных бизнес-приложений, сегодня разберем актуальную и острую для многих стран тему по промышленному использованию природных ресурсов в современных непростых условиях. Строим граф европейской газотранспортной системы в Neo4j. Создание графа европейской газотранспортной системы в Neo4j Российский природный газ...
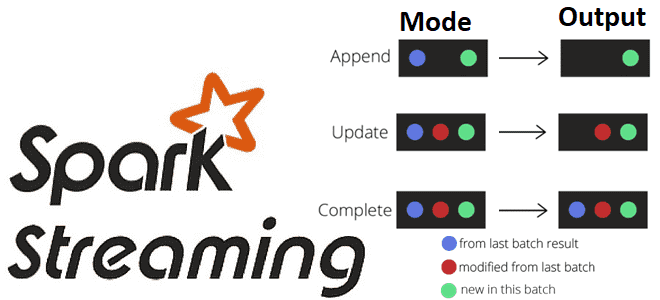
Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений. Что такое режимы вывода в Apache Spark Structured Streaming Apache Spark...
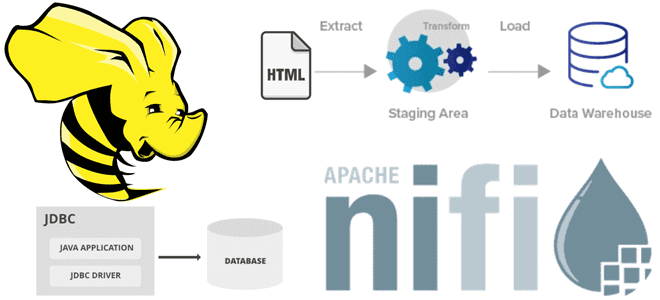
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени. Постановка задачи: ETL-процесс веб-скрейпинга В реальной жизни задача считать данные с веб-сайта для последующей...
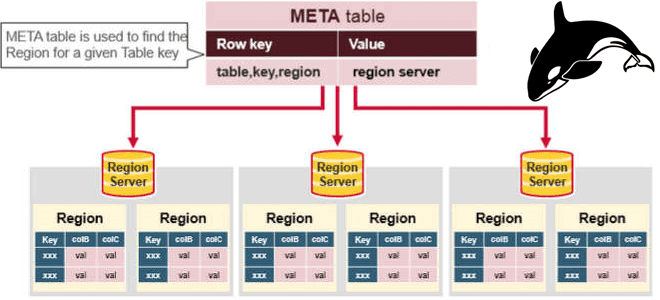
Сегодня затронем тему администрирования кластеров Apache HBase и рассмотрим, приносит ли реальную пользу совместное размещение нескольких региональных серверов (RegionServer) на одном узле кластера. Сравнительный анализ по тестам YCSB-бенчмарка. Регионы и сервера Apache HBase Напомним, Apache HBase является популярной колоночной NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности...
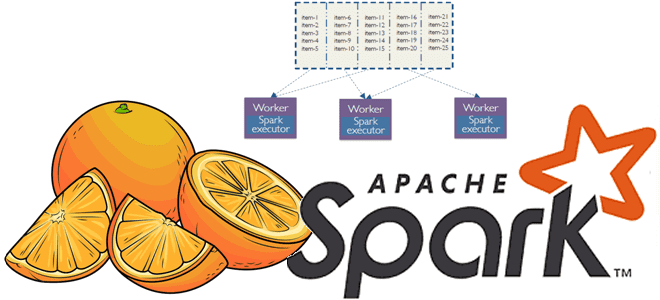
Мы уже рассказывали про функции перераспределения данных по разделам coalesce() и repartition(). Сегодня сравним их работу с еще одним методом управления разделами в Apache Spark и разберем, как все они могут помочь дата-инженеру и разработчику распределенных приложений повысить эффективность этого популярного фреймворка аналитики больших данных. Отобрать и поделить: лучшие практики партиционирования данных...

Как быстро и эффективно с помощью Neo4j выявить преступников, незаконно ввозящих в страну контрафактные товары. Почему графовая СУБД Neo4j обошла документо-ориентированную MongoDB, из чего состоит алгоритм поиска рецидивистов средствами технологий аналитики больших данных и как это может пригодиться в других бизнес-приложениях. Постановка задачи: сложности отслеживания контрафакта Каждый день практически в...

Как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0: тонкости установки и конфигурирования для обучения администраторов кластера и инженеров с примерами команд и кода распределенных приложений. Запуск Spark-приложения на Hadoop-кластере Прежде всего, для настройки кластера Apache Spark нужен работающий кластер Hadoop. Сама установка и настройка выполняется в 2...
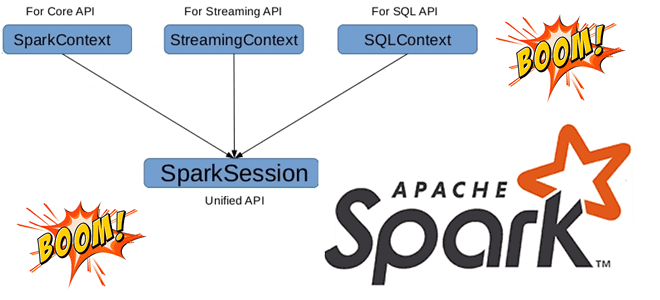
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого...