
Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...
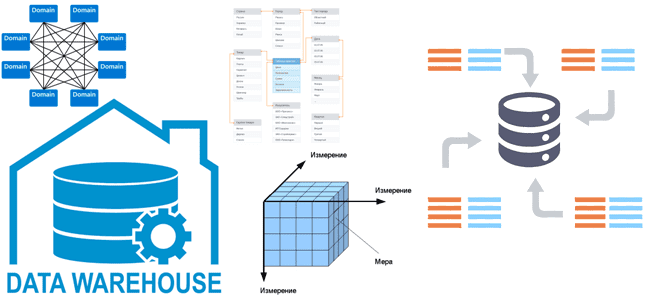
Все архитекторы DWH и многие дата-инженеры знакомы с идеями Ральфа Кимбалла, согласно которым хранилище данных — это сочетание множества различных витрин данных, облегчающих отчетность и анализ важных бизнес-показателей. Читайте далее, как реализовать этот подход при проектировании корпоративного хранилища данных и при чем здесь Data Mesh. КХД по Кимбаллу: доменные витрины...
В этой статье продолжим говорить про лучшие практики работы с Greenplum и рассмотрим тонкости проектирования схем данных в этой MPP-СУБД, которая часто применяется для хранения и аналитики больших данных. Почему надо задавать одинаковые типы данных для столбцов, используемых в SQL-запросах c оператором JOIN, чем хранилище кучи отличается от Append Only,...
Сегодня рассмотрим, как реализовать MLOps-идеи при разработке приложений Apache Flink с использованием MLeap, библиотеки сериализации для моделей машинного обучения. Зачем инженеры GetInData разрабатывали для этого свой коннектор и как его использовать на практике. Что такое MLeap и при чем здесь MLOps Будучи популярным вычислительным движком для потоковой аналитики больших данных,...

Каждый разработчик и дата-аналитик с закрытыми глазами напишет SQL-запрос с регулярными выражениями для поиска данных по шаблону в реляционной базе. А вот в NoSQL-СУБД такая простая задача реализуется довольно сложно. Как написать регулярное выражение в Apache HBase и запустить его на исполнение в CLI-интерфейсе shell-оболочки этого хранилища данных. Что такое...

Сегодня разберем, как автоматизировать наполнение озера данных на HDFS через загрузку таблиц из реляционной базы MySQL в Hive с помощью Apache NiFi. Какие процессоры NiFi следует использовать и зачем предварительно разделять таблицу Apache Hive. Пример ETL-конвейера на процессорах Apache NiFi Apache NiFi часто используется дата-инженерами в качестве средства автоматизации и...
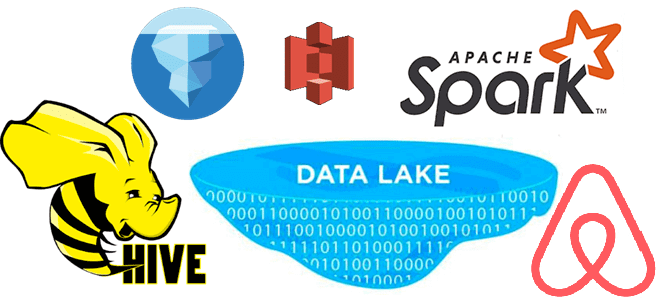
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло. Предыстория: Data Lake на HDFS и Apache Hive Будучи крупнейшей онлайн-площадкой для размещения...
Сегодня разберем тему, важную для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Почему чтение данных из реляционных баз в Apache Spark может быть медленным и как его ускорить, изменив SQL-запрос или структуру таблицы. JDBC-источники данных для Apache Spark Apache Spark является средством обработки, а не хранения больших данных. Поэтому, чтобы использовать...
Мы уже писали про поиск сложных событий при их потоковой обработке средствами Apache Flink. Продолжая эту важную для обучения дата-инженеров тему, сегодня рассмотрим, как CDC-коннектор от GetIndata упрощает запуск распознавание шаблонов на потоках данных из многих источников. Проблемы захвата измененных данных из реляционной базы с помощью JDBC-драйвера и способы их...
Недавно мы писали про устранение серьезной уязвимости PostgreSQL в свежем выпуске Greenplum 6.21.1. Продолжая тему cybersecurity, сегодня разберем другие значимые угрозы, которые были устранены в этой MPP-СУБД в 2022 и 2021 годах. Угрозы безопасности Greenplum и PostgreSQL Будучи основанной на объектно-реляционной СУБД PostgreSQL, что мы разбирали здесь, Greenplum подвержен многим...

В этой статье для обучения дата-инженеров и администраторов SQL-on-Hadoop рассмотрим способы обеспечения информационной безопасности и защиты данных от несанкционированного доступа в Apache Hive. Классический security-набор: аутентификация, авторизация и шифрование. Авторизация и аутентификация в Apache Hive Будучи популярным инструментом стека SQL-on-Hadoop, Apache Hive поддерживает все механизмы обеспечения информационной безопасности, поддерживаемый базовой...
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем особенности работы оператора MERGE во встроенном SQL-подобном языке запросов Cypher популярной NoSQL-СУБД Neo4j. Чем он отличается от запросов CREATE и MATCH, а также когда этот оператор более всего полезен. Как работает MERGE-запрос в Neo4j Data Scientist’ы и аналитики данных знают,...
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark. Что такое...
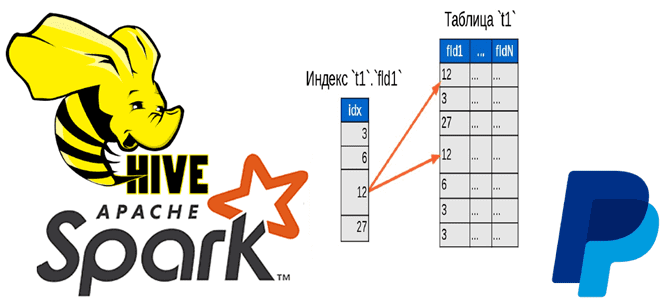
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...

Совсем недавно, в самом конце августа 2022 года вышел очередной минорный выпуск Greenplum. Специально для обучения дата-инженеров, ИТ-архитекторов и разработчиков распределенных OLAP-приложений мы подготовили краткий обзор самых важных обновлений и изменений версии 6.21.1. 15 исправлений на сервере Greenplum В отличие от июньского релиза, новинок в этом выпуске немного: добавлено новое...

Хотя Apache HBase обладает массой достоинств, такими как строгая согласованность на уровне строк при больших объемах запросов, гибкая схема, доступ к данным с малой задержкой и интеграция с Hadoop, эта NoSQL-СУБД имеет ряд недостатков: чрезмерная сложность и дороговизна эксплуатации, отсутствие вторичных индексов и ACID-транзакций. Поэтому инженеры фотохостинга Pinterest приняли решение...

Мы регулярно добавляем в наши курсы по Apache Flink и Spark для дата-инженеров полезные материалы и инструменты, которые помогают повысить эффективность разработки и эксплуатации приложений аналитики больших данных. Читайте далее, что такое SeaTunnel и как эта высокопроизводительная платформа интеграции распределенных данных упрощает их потоковую синхронизацию средствами SQL-заданий Apache Flink и...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, что такое динамическое партиционирование таблиц в Apache Spark, зачем это нужно и как реализовать такие вставки разделов. Разбираем на практическом примере. Что такое динамическое партиционирование в Apache Spark Партиционирование – это разделение данных на основе значения столбца и их сохранение...
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем сложности рефакторинга графовых моделей в Neo4j и способы их обхода с помощью библиотеки APOC и плагина Liquibase. Что такое Liquibase и как Data Scientist и аналитик данных могут использовать его совместно с Neo4j. Гибкость модели данных и трудности...

Сегодня рассмотрим особенности использования оператора LIMIT в Spark SQL: как он выполняется и почему вместо него лучше использовать оператор TABLESAMPLE. Для этого в рамках обучения дата-инженеров, разработчиков распределенных приложений и аналитиков данных заглянем под капот оптимизатора Catalyst в Apache Spark и сравним физические планы выполнения SQL-запросов. Недостатки оператора LIMIT в...