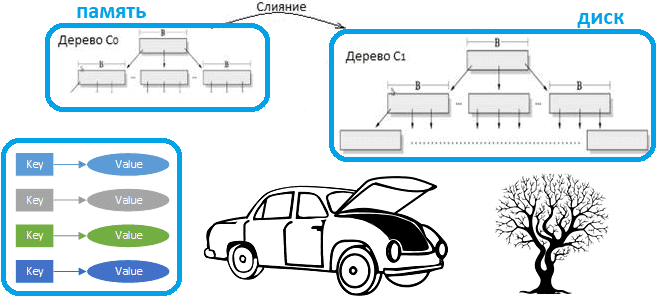
Что такое LSM-дерево и как эта структура данных, лежащая в основе многих NoSQL-баз с распределенным типом ключ-значение, позволяет им обеспечивать высокую скорость записи и чтения. Смотрим на примере Apache HBase. Зачем нужны LSM-деревья Типичная СУБД состоит из нескольких компонентов, каждый из которых отвечает за обработку различных аспектов хранения, поиска и...
Сегодня рассмотрим, чем отличаются подходы к представлению данных в глубоком машинном обучении и реляционной логике, как это связано с декларативной парадигмой логического программирования и при чем здесь графы. А в качестве примера реализации этих идей рассмотрим комбинацию принципов Deep Learning с реляционной логикой и GNN-нейросетями в Python-библиотеке PyNeuraLogic. Машинное обучение...

Продолжая разбираться с новинками Greenplum версии 7, выпущенной в середине декабря 2022 года, сегодня рассмотрим, как теперь работает SQL-команда с DML-запросов изменения таблиц ALTER TABLE. Как динамически менять структуру и характеристики таблицы даже тех, что предназначены только для добавления с новыми методами доступа. Модели таблиц в Greenplum: Append Only и...

Хотя Apache Pig сегодня не самый актуальный инструмент для аналитики больших данных в экосистеме Hadoop, дата-инженеру полезно знать его основные принципы работы и ключевые отличия от Hive. Также рассмотрим, чем Hive отличается от Pig в качестве средства SQL-on-Hadoop. Что такое Apache Pig Apache Pig – это высокоуровневый процедурный язык для...

Как оптимизатор Calcite в Apache Flink переводит SQL-команды в задания потоковой и пакетной обработки и какие приемы могут ускорить их выполнение. Разбираемся, чем полезны интерфейсы пользовательских коннекторов источника и подсказки запросов. Flink SQL в пакетной и потоковой обработке данных Apache Flink позволяет разрабатывать распределенные приложения потоковой обработки больших данных, предоставляя...

В рамках продвижения нашего нового курса по графовой аналитики больших данных, сегодня рассмотрим, как создать граф социальных связей в веб-консоли Neo4j и сделать запросы к нему на Cypher - внутреннем SQL-подобном языке этой NoSQL-СУБД. Как построить граф социальных связей в Neo4j Возьмем в качестве примера набор деловых и личных взаимоотношений...
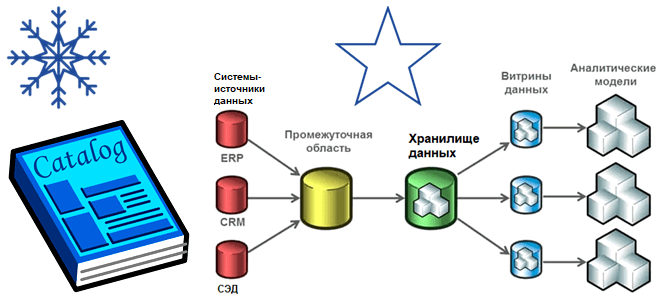
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...
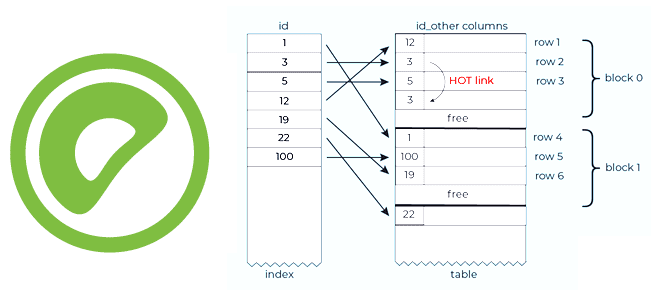
Чтобы сделать наши курсы по Greenplum еще более полезными, сегодня разберем особенности индексов и накладываемых ими ограничений на SQL-запросы к таблицам этой MPP-СУБД. Что такое уникальные индексы и как они поддерживаются в таблицах, оптимизированных для добавления, в Greenplum версии 7, выпущенной в середине декабря 2022 года. Еще раз о пользе...
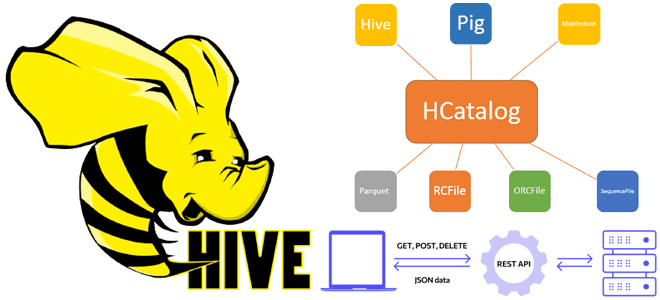
Сегодня рассмотрим, что такое WebHCat в Apache Hive и как этот REST API позволяет взаимодействовать с HCatalog, используя стандартные HTTP-методы. Еще разберем, какие DDL-команды Hive и HiveQL не поддерживает HCatalog, а также что полезного может быть в лог-файлах Templeton. Принципы работы компонента WebHCat как REST-сервиса Apache Hive Будучи NoSQL-хранилищем класса...
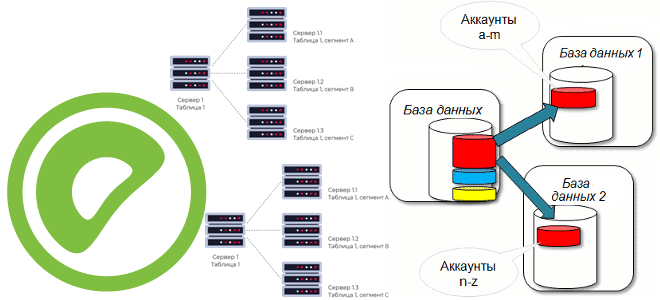
В этой статье для дата-инженеров и ИТ-архитекторов поговорим про шардирование баз данных и разберем, как этот способ горизонтального масштабирования системы реализуется в MPP-СУБД Greenplum, при чем здесь ключ дистрибуции и как его задать. Что такое шардирование БД и как оно работает Чтобы повысить производительность приложения через увеличение пропускной способности СУБД...

Недавно мы писали про Apache NiFi 1.18. А 28 ноября опубликован новый выпуск - 1.19.0 и спустя немного времени первый баг-фикс к нему. Разбираемся с новинками свежего релиза самого популярного потокового ETL-маршрутизатора: новые процессоры, исправления ошибок и улучшения, о которых следует знать дата-инженеру и администратору кластера. Главные новости Apache NiFi...

В этой статье для обучения ИТ-архитекторов и дата-инженеров сравним 2 подхода к аналитике больших данных, чтобы решить, когда потоковые вычисления, например, средствами ksqlDB в рамках Apache Kafka лучше аналитических баз данных реального времени, таких как Rockset, и наоборот. 2 способа выполнения аналитики больших данных в реальном времени Современный бизнес и...

16 ноября 2022 года вышел 2-ой альфа-релиз Apache Hive 4.0.0. Какие ошибки в нем исправлены и что за новые функции, важные для дата-инженера и администратора кластера Hadoop, появились. А перед этим вспомним основные принципы работы Apache Hive. Принципы работы Apache Hive Apache Hive является популярным инструментом стека SQL-on-Hadoop, позволяя обращаться...

Недавно мы писали про новинки сентябрьского и октябрьского релизов Greenplum 6.22, а 18 ноября 2022 года вышла новая отладочная версия, которая решает некоторые проблемы с сервером СУБД, обработкой запросов и потоком данных. Разбираемся, что стало лучше в VMware Tanzu Greenplum 6.22.2 с точки зрения администратора кластера и дата-инженера. Новинки и...
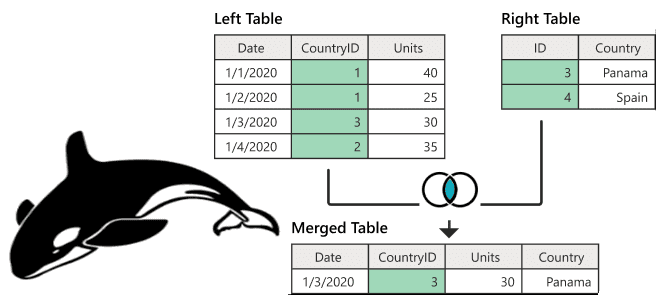
Поиск данных по нескольким таблицам в реляционных базах данных реализуется через SQL-запрос с оператором JOIN. В NoSQL-хранилищах такая возможность может отсутствовать. Разбираем, как соединить таблицы в Apache HBase и причем здесь MapReduce. Варианты реализации JOIN в Apache HBase Будучи популярной NoSQL-базой, которая реализует возможности Google BigTable для Apache Hadoop, HBase...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...
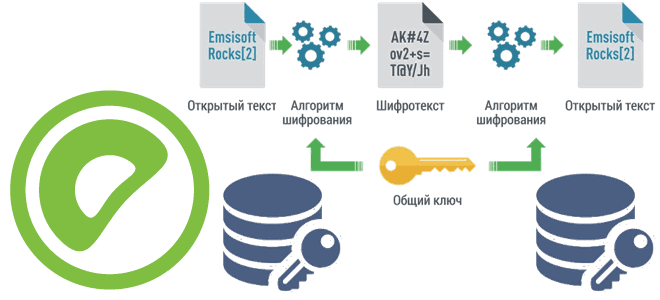
Чтобы сделать наши курсы по Greenplum еще более полезными для дата-инженеров и администраторов, сегодня познакомимся с pgcrypto – важным расширением этой MPP-СУБД, которое предоставляет криптографические функции, чтобы хранить некоторые столбцы данных в зашифрованном виде. Как установить расширение pgcrypto и использовать его для улучшения безопасности Greenplum. Шифрование данных в Greenplum База...

9 сентября 2022 года VMware Tanzu выпустили Greenplum 6.22. А спустя месяц, 7 октября вышел апгрейд этого релиза с исправлением ошибок. Разбираем, что нового в этих выпусках: полезные функции, улучшения и исправления ошибок, особенно важные для администратора кластера и дата-инженера. Greenplum 6.22.0 Сентябрьское обновление Greenplum 6.22.0 включает следующие функциональные возможности...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

Недавно мы рассматривали тонкости проектирования схем данных в Greenplum. Продолжая разбирать важные для обучения дата-инженеров и архитекторов DWH темы, сегодня поговорим о том, как разделение и распределение данных влияют на скорость выполнения SQL-запросов в этой MPP-СУБД. Распределение данных Напомним, MPP-СУБД Greenplum широко используется в качестве OLAP-системы и корпоративного хранилища данных....