Вчера мы рассказывали, почему важна наблюдаемость данных какие платформы помогают комплексно обеспечить все ее аспекты. В продолжение этой темы сегодня заглянем под капот происхождения данных в Apache Spark с помощью агента Spline и других способов. Трудности data lineage в Apache Spark Когда конвейер данных выходит из строя, дата-инженеру нужно скорее...

Сегодня рассмотрим 2 основные категории технологий обработки данных: пакетную и потоковую. Что общего между batch и stream processing, где они применяются, какими технологиями поддерживаются, можно ли их использовать вместе и как это сделать: ликбез по архитектуре больших данных. Потоковая и пакетная обработка: краткий обзор с примерами Обработки данных в режиме...

Что такое SparkListener, какие встроенные слушатели бывают в Apache Spark, как написать собственный перехватчик событий и зачем это нужно разработчику распределенного приложения. Также рассмотрим, как реализовать свой слушатель для приложения на PySpark и зачем включать уровень логирования INFO для SparkContext. Что такое слушатель Spark Apache Spark позволяет быстро обрабатывать большие...

Сколько ядер ЦП выделить на каждый исполнитель и каково оптимальное количество памяти для Spark-приложения при статическом и динамическом выделении ресурсов. Важные вопросы эффективной утилизации кластера, с которыми сталкивается каждый дата-инженер и разработчик распределенных программ. Запуск распределенного приложения через spark-submit Повысить эффективность работы приложения Apache Spark можно не только через оптимизацию...

Что такое архитектура данных, какие модели чаще всего используются в современных Big Data системах, почему традиционные BI-системы не справляются со всем разнообразием текущих бизнес-сценариев, чем Лямбда отличается от Каппа, а Data Fabric от Data Mesh и зачем внедрять MLOps-инструменты в аналитическую платформу. Немного истории: почему архитектуры данных до сих пор...

Что такое Tungsten, зачем он нужен в Apache Spark и как этот проект устраняет узкие места вычислительного движка, чтобы повысить его производительность и эффективность утилизации ресурсов за счет приближения JVM к bare metal. Рассматриваем самые важные для разработчика распределенных приложений особенности и разбираемся, при чем здесь вольфрам и почему с...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...

Специально для обучения начинающих аналитиков данных и дата-инженеров сегодня рассмотрим примеры выполнения простых SQL-запросов и оконных функций в Apache Spark на Google Colab. Как быстро проанализировать датафрейм из CSV-файлов с помощью нескольких строк на PySpark. Запуск и использование PySpark в Google Colab Предположим, необходимо определить потенциальный доход от проведения обучающих...

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi. Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт)....
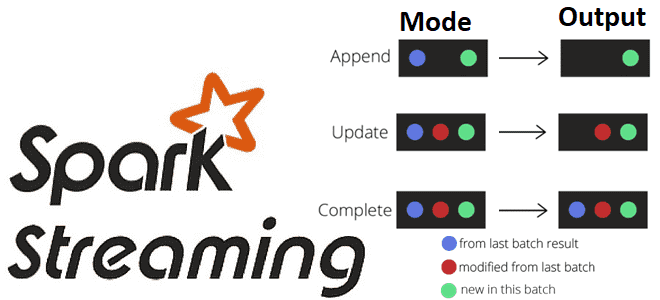
Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений. Что такое режимы вывода в Apache Spark Structured Streaming Apache Spark...
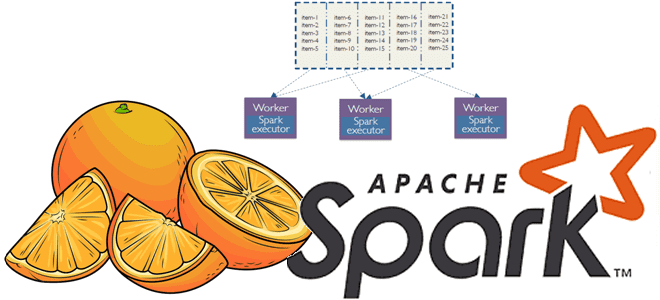
Мы уже рассказывали про функции перераспределения данных по разделам coalesce() и repartition(). Сегодня сравним их работу с еще одним методом управления разделами в Apache Spark и разберем, как все они могут помочь дата-инженеру и разработчику распределенных приложений повысить эффективность этого популярного фреймворка аналитики больших данных. Отобрать и поделить: лучшие практики партиционирования данных...

Пример выявления финансового мошенничества при скимминге банковских карт в банкоматах с помощью технологий Big Data. Как Apache Kafka, Flink и HBase помогут обнаружить злоумышленников в режиме реального времени. Что такое скимминг, как это работает и чем опасно Скимминг является одним из частых видов мошенничества с банковскими картами, представляющий собой считывание...

Как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0: тонкости установки и конфигурирования для обучения администраторов кластера и инженеров с примерами команд и кода распределенных приложений. Запуск Spark-приложения на Hadoop-кластере Прежде всего, для настройки кластера Apache Spark нужен работающий кластер Hadoop. Сама установка и настройка выполняется в 2...
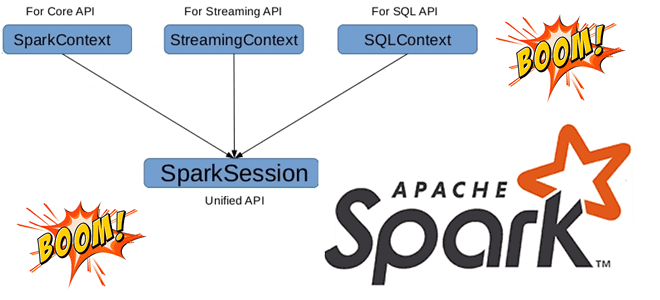
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого...

Как изменять правила фильтрации данных без перезапуска потокового Flink-приложения: практический пример для разработчиков и дата-инженеров. Чем подход с ключами состояний отличается от широковещательных соединений, каковы достоинства и недостатки этих альтернатив. Фильтрация данных в статике и динамике Практически каждая платформа потоковой передачи событий позволяет использовать фильтрацию операторов для отбора данных согласно...
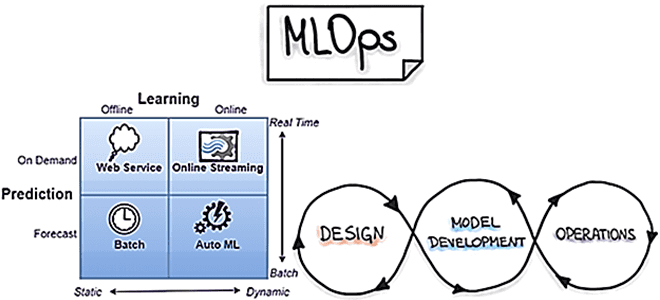
Сегодня рассмотрим наиболее распространенные в MLOps стратегии развертывания, т.е. подходы к внедрению моделей машинного обучения в производство. Выбор стратегии зависит от бизнес-требований и от контекста применения результатов ML-моделирования. Какие бывают стратегии и как они реализуются: краткий ликбез с примерами для ML-инженеров и MLOps-специалистов. Пакетное прогнозирование и веб-сервисы для MLOps Это...

Сегодня заглянем под капот Apache Spark и разберем, для чего этому популярному вычислительному движку база метаданных, как ее назначить и что не так с хранилищем данных по умолчанию. Зачем уходить от Apache Derby к Hive и как это сделать: краткий ликбез с примерами для обучения дата-инженеров и разработчиков распределенных приложений....

Недавно в Google Dataproc появился бессерверный Apache Spark. Разбираемся, что это такое и зачем нужно дата-инженерам. Как работает serverless Spark в облачной платформе Google и почему выбирать между Dataflow и Dataproc стало еще сложнее. Блеск и нищета Google Dataproc Напомним, Google Dataproc – это облачный Hadoop, который работает аналогично другим...
В этой статье для дата-инженеров и аналитиков данных, рассмотрим, что такое широковещательные соединение в Apache Spark SQL, чем оно полезно и как работает на практических примерах. BROADCAST JOIN в SELECT-запросах Spark SQL, а также краткий ликбез по подсказкам или хинтам. Что такое широковещательное соединение в Apache Spark SQL Распределенная природа...