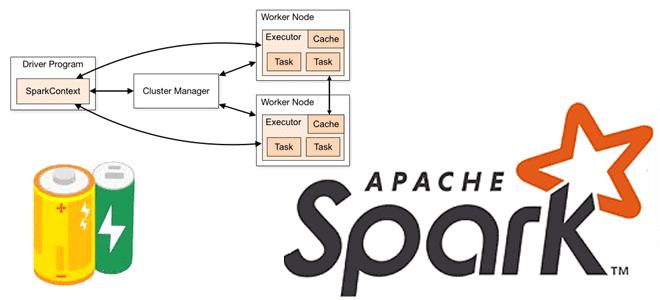
Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере. Широковещательные переменные vs аккумуляторы В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например,...

Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника. Прямой поток и подход на основе приемника Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме...

Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok. Проброска туннеля в Google Colab с ngrok для Spark-приложения Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики...
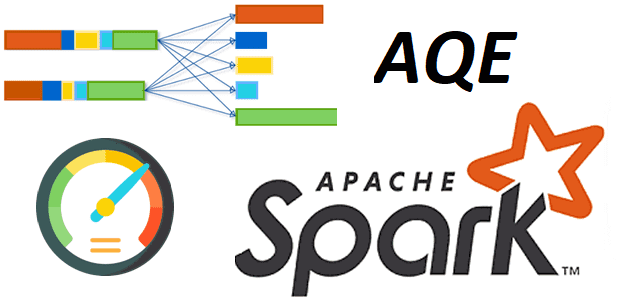
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions. Разделы и оптимизация распределенных вычислений в Spark-приложениях Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, какие механизмы обеспечения информационной безопасности поддерживает Apache Spark и как организовать безопасное взаимодействие Spark-приложения с хранилищами данных в экосистеме Hadoop. Безопасная работа Spark-приложений с сервисами Hadoop Многие технологии Big Data изначально оптимизированы для хранения и аналитики больших объемов данных с...
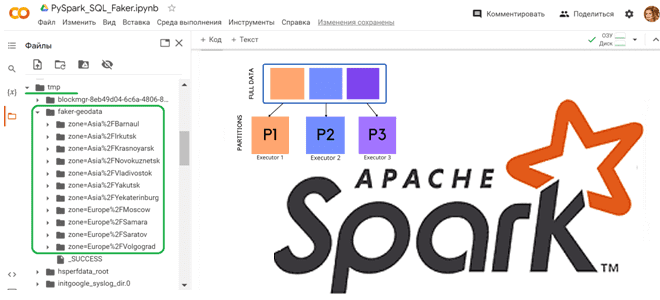
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab. Как работает partitionBy() в Apache Spark Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache...

12 апреля 2023 года вышел очередной релиз Apache Spark. Разбираемся с самыми главными новинками этого выпуска, которые порадуют аналитиков, разработчиков, инженеров данных и специалистов по Data Science. Расширенная поддержка Python, улучшения Spark SQL и Structured Streaming. Обновления Spark SQL и новинки для пользователей Python Apache Spark 3.4.0 — это пятый...
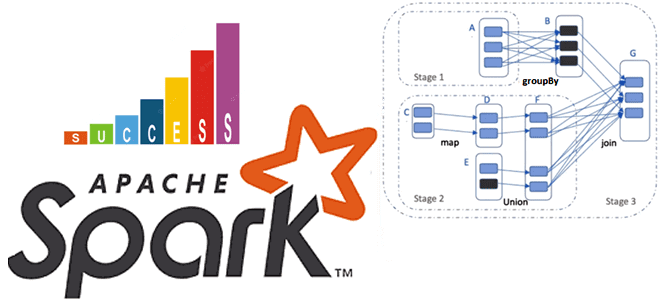
Почему на самом деле нельзя избежать shuffle-операций в Spark SQL, в чем разница перетасовки RDD и датафреймов, а также как сократить негативное влияние перемешивания данных по узлам кластера, настроив конфигурации распределенного приложения. Что такое shuffle-операции в Apache Spark SQL и зачем они нужны Распределенный характер вычислительного движка Apache Spark позволяет...

Сегодня познакомимся с сервером истории Apache Spark: зачем он нужен, как работает и при чем здесь слушатели событий. Отладка и мониторинг распределенных приложений для дата-инженера в веб-GUI. Что такое сервер истории Apache Spark Каждый раз при запуске Spark-приложения его контекст SparkContext запускает веб-интерфейс по умолчанию на порту 4040. Если несколько...
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...

Как разработчику выбрать подходящий режим развертывания для своего Spark-приложения, достоинства и недостатки клиентского и кластерного режимов, а также особенности запуска под управлением YARN. Архитектура и режимы развертывания Spark-приложения Будучи фреймворком для создания приложений быстрой обработки Big Data, Apache Spark имеет несколько режимов развертывания, которые зависят от варианта запуска Spark-приложения: на...
В Apache Spark есть 3 структуры данных, каждая из которых имеет собственный API со своими достоинствами и недостатками. Сегодня разберем плюсы и минусы Dataset API, а также рассмотрим особенности JOIN-операций в нем. Почему Dataset API в Apache Spark работает только со Scala и Java Напомним, структура данных Dataset впервые появилась...
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...
Что такое backfill-операции в конвейерах заданий Apache Spark, чем они отличаются от исторического заполнения датасетов, зачем их автоматизировать и как это сделать. Что такое backfilling для заданий Apache Spark Мы уже писали про понятие backfill на примере модификации DAG при добавлении новых заданий в конвейер Apache AirFlow. Эта функция полезна,...

Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...

Чтобы сделать наши курсы для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня мы расскажем про новый бесплатный сервис от маркетплейса Joom для поиска проблем с производительностью Spark-заданий. Разбираемся, как он работает и чем полезен дата-инженеру. 4 главных проблемы Spark-приложений, их последствия и трудности обнаружения Если количество Spark-приложений невелико,...

Как MLOps-инженеры платформы онлайн-курсов Udemy ускорили цикл разработки и внедрения проектов машинного обучения, используя возможности Amazon SageMaker для создания и отладки Spark-приложений в удаленном облачном кластере. MLOps на AWS Чтобы воспользоваться преимуществами бесшовной интеграции процессов разработки и развертывания машинного обучения согласно концепции MLOps, совсем не обязательно выстраивать собственную платформу из...

Как использовать преимущества графических процессоров для Spark-приложений аналитики больших данных и машинного обучения с помощью библиотек RAPIDS. Знакомимся с ускорителем Spark RAPIDS и его возможностями сделать популярный вычислительный движок еще быстрее. Что такое RAPIDS Accelerator для Apache Spark и как он работает Системы Machine Learning, особенно проекты глубокого обучения, уже...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...

Как повысить скорость выполнение SQL-запросов в Spark-приложениях, используя Gluten – новый вычислительный движок, объединяющий несколько векторизированных механизмов выполнения с поддержкой аппаратных ускорителей. Что такое Gluten и как он появился в Apache Spark Когда данных много, их обработка может длиться долго. Чтобы ускорить вычисления с Big Data, разработчики распределенных приложений и...