
PySpark позволяет работать не только с большими данными (Big data), но и создавать модели машинного обучения (Machine Learning). Сегодня мы расскажем вам о модуле ML и покажем, как обучить модель Machine Learning для решения задачи классификации. Читайте у нас: подготовка данных, применение логистической регрессии, а также использование метрик качеств в...

При всех своих достоинствах Delta Lake, включая коммерческую реализацию этой Big Data технологии от Databricks, оно обладает рядом особенностей, которые могут расцениваться как недостатки. Сегодня мы рассмотрим, чего не стоит ожидать от этого быстрого облачного хранилище для больших данных на Apache Spark и как можно обойти эти ограничения. Читайте далее,...

Продолжая разговор про Delta Lake, сегодня мы рассмотрим, чем это быстрое облачное хранилище для больших данных в реализации компании Databricks отличается от классического озера данных (Data Lake) на Apache Hadoop HDFS. Читайте далее, как коммерческое Cloud-решение на Apache Spark облегчает профессиональную деятельность аналитиков, разработчиков и администраторов Big Data. Больше, чем...

Озеро данных (Data Lake) на Apache Hadoop HDFS в мире Big Data стало фактически стандартом де-факто для хранения полуструктурированной и неструктурированной информации с целью последующего использования в задачах Data Science. Однако, недостатком этой архитектуры является низкая скорость вычислительных операций в HDFS: классический Hadoop MapReduce работает медленнее, чем аналоги на Apache...

В прошлый раз мы говорили о том, как установить PySpark в Google Colab, а также скачали датасет с помощью Kaggle API. Сегодня на примере этого датасета покажем, как применять операции SQL в PySpark в рамках анализа Big Data. Читайте далее про вывод статистической информации, фильтрацию, группировку и агрегирование больших данных...

Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...
Недавно мы рассказывали, что такое PySpark. Сегодня рассмотрим, как подключить PySpark в Google Colab, а также как скачать датасет из Kaggle прямо в Google Colab, без непосредственной загрузки программ и датасетов на локальный компьютер. Google Colab Google Colab — выполняемый документ, который позволяет писать, запускать и делиться своим Python-кодом через...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
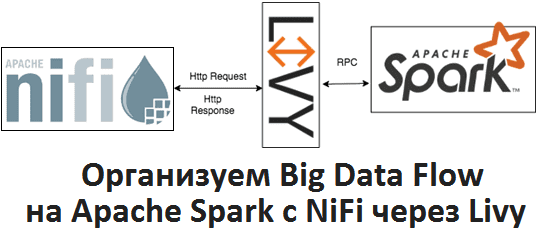
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...

Python считается из основных языков программирования в областях Data Science и Big Data, поэтому не удивительно, что Apache Spark предлагает интерфейс и для него. Data Scientist’ы, которые знают Python, могут запросто производить параллельные вычисления с PySpark. Читайте в нашей статье об инициализации Spark-приложения в Python, различии между Pandas и PySpark,...

Продолжая разговор про обучение Spark на реальных примерах, сегодня мы рассмотрим, как работает этот Big Data фреймворк на Kubernetes, популярной DevOps-платформе автоматизированного управления контейнеризированными приложениями. Читайте в нашей статье, как запустить приложение Apache Spark в кластере Kubernetes (K8s) с помощью submit-скрипта и оператора, а также при чем здесь Docker-образ. Запуск...

Вчера мы рассказывали об основных сценариях запуска Apache Spark на Kubernetes и преимуществах этого варианта развертывания популярного Big Data фреймворка на DevOps-платформе автоматизированного управления контейнеризированными приложениями. Сегодня поговорим про обратную сторону всех этих преимуществ: читайте в нашей статье, каковы основные ограничения и главные недостатки запуска Apache Spark на Kubernetes (K8s)....
Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...

Недавно мы разбирали особенности интеграции Apache Kudu и Spark. В продолжение этой темы, сегодня поговорим про некоторые особенности выполнения SQL-операций с данными при интеграции этих Big Data фреймворков, а также рассмотрим пример записи данных в мульти-мастерный кластер Куду через Impala с помощью API Data Frame на PySpark. Что приносит Kudu...
Продолжая разбирать production-кейсы реального использования этих технологий Big Data, сегодня поговорим подробнее, каковы плюсы совместного применения Kudu, Spark Streaming, Kafka и Cloudera Impala на примере аналитической платформы для мониторинга событий информационной безопасности банка «Открытие». Также читайте в нашей статье про возможности этих технологий в контексте машинного обучения (Machine Learning), в...

Сегодня мы рассмотрим практический кейс использования Apache Kudu с Kafka, Storm и Cloudera Impala в крупной китайской корпорации, которая производит смартфоны. На базе этих Big Data технологий компания Xiaomi построила собственную платформу для BI-аналитики больших данных и генерации отчетности в реальном времени. История Kudu-проекта в Xiaomi Корпорация Xiaomi начала использовать...