
Чтобы сделать наши курсы по Apache Spark еще более полезными, сегодня разберем 2 варианта решения типовой задачи инженерии данных. Как быстро и эффективно считать данные из множества CSV-файлов с одинаковой схемой за несколько строк кода на PySpark. Постановка задачи: рутинная работа с CSV-файлами Наряду с JSON-файлами, про которые мы писали...

Недавно мы писали про сложности обработки вложенных структур данных в JSON-файлах при работе с Apache Hive и Spark. В продолжении этой темы про парсинг, сегодня поговорим, как быстро преобразовать данные формата JSON в простой читаемый файл CSV или плоскую таблицу, чтобы анализировать их с помощью типовых методов DataFrame API или...

Чем хороши JSON-файлы и как с ними работать в Apache Spark и Hive: проблемы обработки вложенных структур данных и способы их решения на практических примерах. Как автоматизировать переименование некорректных названий полей во вложенных структурах данных JSON-файлов на любом количестве таблиц со множеством полей, чтобы создать таблицу в Hive Metastore и...
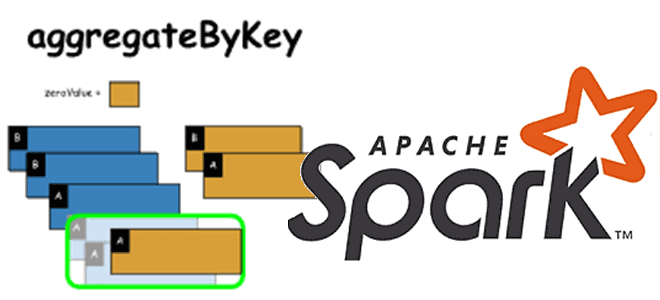
В рамках обучения дата-аналитиков и разработчиков Spark-приложений, сегодня рассмотрим одну из агрегатных функций обработки данных в этом распределенном вычислительном фреймворке. Чем aggregateByKey() отличается от reduceByKey() и groupByKey(), и когда стоит ее использовать. Как устроена функция aggregateByKey(): назначение и синтаксис Функция aggregateByKey() - одна из агрегатных функций, наряду с reduceByKey() и...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, что такое локальность данных и как это влияет на производительность заданий. А также разберем, где в UI Apache Spark посмотреть нахождение данных для распределенных вычислений и какие параметры конфигурации следует настроить, чтобы повысить скорость их выполнения. Что такое локальность данных в...

В этой статье для разработчиков распределенных приложений разберем проблему с производительностью Apache Spark из-за неоптимальной стратегии переброса данных между оперативной и постоянной памятью. Что такое spill-эффект, почему он случается, как его идентифицировать и устранить. Что такое spill и почему он случается: под капотом Spark-приложений При том, что spill можно рассматривать...
В этой статье для дата-аналитиков и разработчиков распределенных приложений рассмотрим несколько распространенных ошибок, которые можно сделать в PySpark-коде. Когда PySpark-код на DataFrame DSL лучше запросов Spark SQL, как изящно решить проблему длинных строк, почему пользоваться функцией cache() надо осторожно, а также откуда появляются NULL-значения при внешних соединениях потоковых таблиц. Spark...

Сегодня разберем типовые ошибки, которые часто возникают в системах аналитики больших данных на базе Apache Hadoop YARN, Spark и RESTful-интерфейсу Livy, а также каким образом их избежать. В качестве практического примера используем ранее рассмотренный кейс интерактивной аналитики о пользовательском поведении в фотохостинге Pinterest. Интерактивная аналитика больших данных в Pinterest Недавно...

В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое DataStax Enterprise Graph. Читайте далее, как немецкая ИТ-компания Traversals с помощью этой распределенной графовой СУБД построила масштабное аналитическое решение для кибербезопасности, обнаружения мошенничества, анализа конкурентов и оповещения клиентов в реальном времени. Также разберем, при...

Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано. Зачем...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

В рамках обучения разработчиков Spark-приложений, аналитиков данных и дата-инженеров, сегодня рассмотрим, как улучшить и визуализировать понимание обработки данных в этом Big Data фреймворке. Читайте далее про API встроенных механизмов наблюдения за качеством данных в Apache Spark и открытые библиотеки профилирования на примере Deequ. 2 уровня абстракции мониторинга Spark-приложений для дата-инженера...

Анализ данных в рамках пользовательский сеансов (сессий) – довольно востребованный кейс в Apache Spark, который не так просто реализовать из-за особенностей потоковой и пакетной обработки, а также эксплуатационных расходов. Сегодня рассмотрим, как работают сеансовые окна Spark Structured Streaming и каковы ограничения этого фреймворка. Что такое сеансовые окна: краткий ликбез по...

В этой статье для дата-инженеров рассмотрим кейс компании PayPal, которая переводит свои аналитические рабочие нагрузки из локального кластера Apache Spark в Google Cloud Processing. Читайте далее, чем это решение оказалось лучше выполнения Spark-заданий в кластере DataProc с использованием данных BigQuery и облачного хранилища Google (GCS, Google Cloud Storage) для потоковой...

Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга....

Продвигая наш новый курс по графовым алгоритмам на больших данных, сегодня рассмотрим, почему концепция графов сегодня так востребована в Big Data и Machine Learning. Вас ждет краткий ликбез по модулю GraphX в Apache Spark и его отличия от API GraphFrames, а также особенности кластерной обработки и сохранения данных графа свойств....
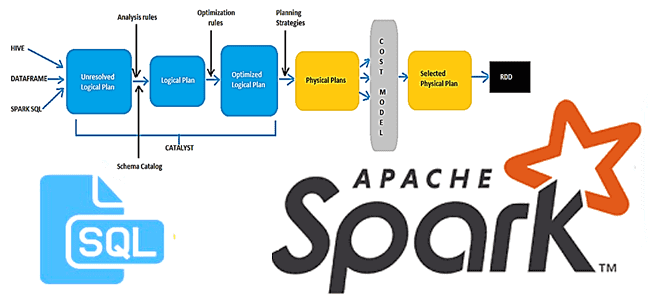
В этой статье для разработчиков Spark-приложений и дата-аналитиков рассмотрим новый оптимизатор этого фреймворка, Radiant. Он основан на SQL-оптимизаторе Catalyst и представляет собой open-source проект от энтузиастов сообщества Apache Spark. Читайте далее, чем хорош Spark-Radiant и как использовать его для оптимизации SQL-запросов при аналитике больших данных. Что такое SQL-оптимизатор Spark-Radiant и...

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...
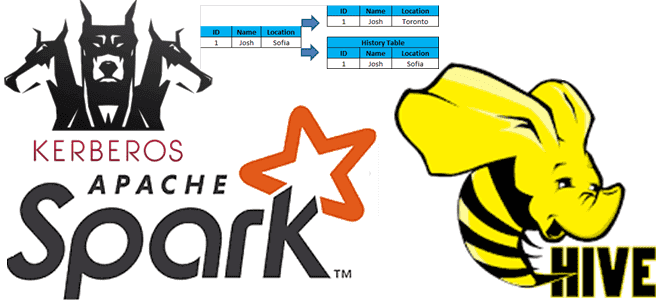
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...