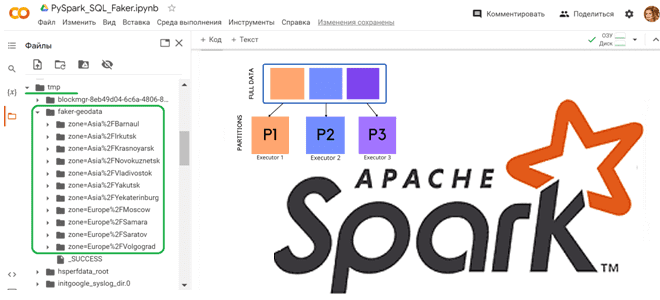
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab. Как работает partitionBy() в Apache Spark Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache...

12 апреля 2023 года вышел очередной релиз Apache Spark. Разбираемся с самыми главными новинками этого выпуска, которые порадуют аналитиков, разработчиков, инженеров данных и специалистов по Data Science. Расширенная поддержка Python, улучшения Spark SQL и Structured Streaming. Обновления Spark SQL и новинки для пользователей Python Apache Spark 3.4.0 — это пятый...
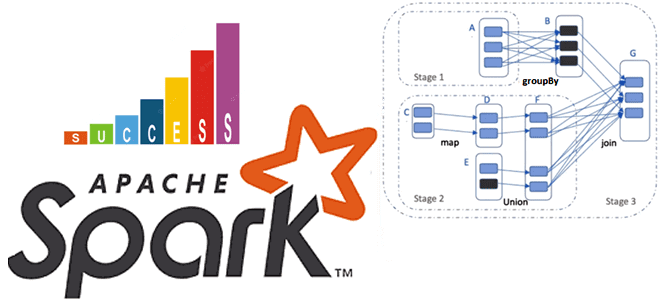
Почему на самом деле нельзя избежать shuffle-операций в Spark SQL, в чем разница перетасовки RDD и датафреймов, а также как сократить негативное влияние перемешивания данных по узлам кластера, настроив конфигурации распределенного приложения. Что такое shuffle-операции в Apache Spark SQL и зачем они нужны Распределенный характер вычислительного движка Apache Spark позволяет...

Сегодня познакомимся с сервером истории Apache Spark: зачем он нужен, как работает и при чем здесь слушатели событий. Отладка и мониторинг распределенных приложений для дата-инженера в веб-GUI. Что такое сервер истории Apache Spark Каждый раз при запуске Spark-приложения его контекст SparkContext запускает веб-интерфейс по умолчанию на порту 4040. Если несколько...
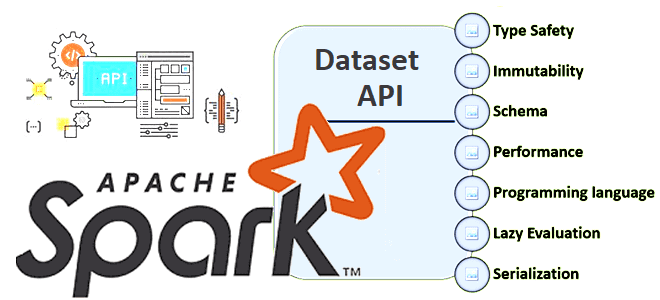
В Apache Spark есть 3 структуры данных, каждая из которых имеет собственный API со своими достоинствами и недостатками. Сегодня разберем плюсы и минусы Dataset API, а также рассмотрим особенности JOIN-операций в нем. Почему Dataset API в Apache Spark работает только со Scala и Java Напомним, структура данных Dataset впервые появилась...

Чтобы сделать наши курсы для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня мы расскажем про новый бесплатный сервис от маркетплейса Joom для поиска проблем с производительностью Spark-заданий. Разбираемся, как он работает и чем полезен дата-инженеру. 4 главных проблемы Spark-приложений, их последствия и трудности обнаружения Если количество Spark-приложений невелико,...

Как использовать преимущества графических процессоров для Spark-приложений аналитики больших данных и машинного обучения с помощью библиотек RAPIDS. Знакомимся с ускорителем Spark RAPIDS и его возможностями сделать популярный вычислительный движок еще быстрее. Что такое RAPIDS Accelerator для Apache Spark и как он работает Системы Machine Learning, особенно проекты глубокого обучения, уже...

Как повысить скорость выполнение SQL-запросов в Spark-приложениях, используя Gluten – новый вычислительный движок, объединяющий несколько векторизированных механизмов выполнения с поддержкой аппаратных ускорителей. Что такое Gluten и как он появился в Apache Spark Когда данных много, их обработка может длиться долго. Чтобы ускорить вычисления с Big Data, разработчики распределенных приложений и...

Специально для обучения дата-инженеров и разработчиков распределенных программ, сегодня рассмотрим подходы к организации модульного тестирования Spark-приложений через классы тестовых данных. Зачем и как генерировать эти классы, где их хранить и при чем здесь система автоматической сборки приложений Gradle. Сборка и тестирование Spark-приложений Модульное тестирование лежит в основе проверки работоспособности программного...

Как Apache Spark организует параллельные вычисления, зачем нужны аккумуляторы и каким образом они помогают организовать мониторинг качества данных в аналитических конвейерах их обработки. Смотрим с точки зрения дата-инженера и разработчика распределенных приложений. Как Apache Spark распараллеливает обработку данных Параллельная обработка — это метод вычислений, при котором работает более одного ЦП...

В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных. Постановка задачи и ограничения POC для...

Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...

Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...

Разработка высоконагруженных систем потоковой аналитики больших данных включает не только написание кода, но и его оптимизацию. Поэтому разработчикам приложений Apache Spark Structured Streaming и дата-инженерам полезно знать, как можно повысить эффективность своих Big Data систем. В этой статье мы рассмотрим конфигурации и приемы, которые могут ускорить пакетные и потоковые вычисления....
Сегодня разберем тему, важную для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Почему чтение данных из реляционных баз в Apache Spark может быть медленным и как его ускорить, изменив SQL-запрос или структуру таблицы. JDBC-источники данных для Apache Spark Apache Spark является средством обработки, а не хранения больших данных. Поэтому, чтобы использовать...

Сегодня рассмотрим важную тему для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Как устроена потоковая обработка данных в Apache Spark Structured Streaming, зачем нужны водяные знаки и с какими сложностями при этом можно столкнуться. Как работают водяные знаки в потоковой передача событий Apache Spark Библиотека потоковой обработки событий Structured Streaming основана...

Мы регулярно добавляем в наши курсы по Apache Flink и Spark для дата-инженеров полезные материалы и инструменты, которые помогают повысить эффективность разработки и эксплуатации приложений аналитики больших данных. Читайте далее, что такое SeaTunnel и как эта высокопроизводительная платформа интеграции распределенных данных упрощает их потоковую синхронизацию средствами SQL-заданий Apache Flink и...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, что такое динамическое партиционирование таблиц в Apache Spark, зачем это нужно и как реализовать такие вставки разделов. Разбираем на практическом примере. Что такое динамическое партиционирование в Apache Spark Партиционирование – это разделение данных на основе значения столбца и их сохранение...