
В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
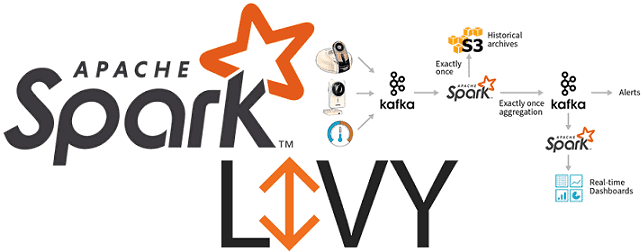
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Мы уже писали о преимуществах DaaS-похода, когда облачные провайдеры предоставляют данные как услугу, включая сложную предиктивную аналитику с использованием алгоритмов машинного обучения. Это позволяет быстро и удобно воспользоваться технологиями Big Data без существенных инвестиций в ИТ-инфраструктуру и дорогих специалистов, таких как Data Scientist, инженер и аналитик больших данных. Однако все...

Аутентификация – далеко не единственная возможность обеспечения информационной безопасности в Apache Kafka. Сегодня мы продолжим разговор про Big Data cybersecurity и рассмотрим особенности авторизации в Apache Kafka в формате самообслуживания (self-service), как это было сделано в travel-компании Booking.com. В качестве примера продолжим разбирать доклад Александра Миронова, который был представлен 23...

Продолжая разбирать доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим, с какими проблемами столкнулись администраторы Big Data при обеспечении информационной безопасности своих Кафка-кластеров. Читайте в нашей статье про возможные методы аутентификации в Apache Kafka и их практическое использование в...

Сегодня мы разберем доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech [1]. Читайте в нашей статье, как одна из ведущих travel-компаний использует Apache Kafka, с какими проблемами столкнулись администраторы ее Big Data инфраструктуры и DevOps-инженеры, а также почему были выбраны именно такие...

Вчера мы говорили о том, какие организационные барьеры мешают реализации запланированных проектов национальной программы «Цифровая экономика РФ». Сегодня рассмотрим основные этические риски, которые сдерживают развитие цифровой трансформации в России и разберем некоторые возможности их обхода. Чем страшна цифровизация: 7 ключевых проблем с точки зрения этики 16 января 2020 года Центр...
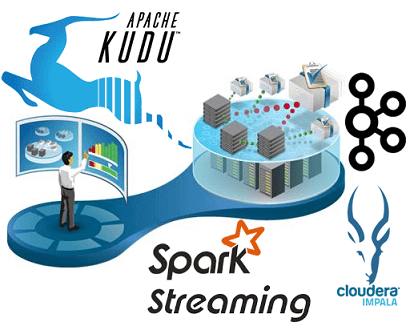
Продолжая разбирать production-кейсы реального использования этих технологий Big Data, сегодня поговорим подробнее, каковы плюсы совместного применения Kudu, Spark Streaming, Kafka и Cloudera Impala на примере аналитической платформы для мониторинга событий информационной безопасности банка «Открытие». Также читайте в нашей статье про возможности этих технологий в контексте машинного обучения (Machine Learning), в...

В этой статье рассмотрим несколько примеров по аналитике больших данных в Elasticsearch (ES), а также разберем возможности алгоритмов машинного обучения в ELK Stack. Читайте, как использовать NoSQL-СУБД ES в качестве озера данных для проверки различных бизнес-гипотез с помощью Machine Learning, показывая результаты моделирования в интерфейсе Kibana: практическая аналитика Big Data....

Вчера мы рассказывали про самые известные утечки Big Data с открытых серверов Elasticsearch (ES). Сегодня рассмотрим, как предупредить подобные инциденты и надежно защитить свои большие данные. Читайте в нашей статье про основные security-функции ELK-стека: какую безопасность они обеспечивают и в чем здесь подвох. Несколько cybersecurity-решений для ES под разными лицензиями...

Продолжая разговор про Elastic Stack, сегодня мы рассмотрим проблемы cybersecurity в Elasticsearch: разберем самые известные утечки данных за последнюю пару лет и поговорим, кто и как обнаруживает подобные инциденты. Читайте в нашей статье, какие средства используют «белые хакеры» для поиска уязвимостей в Big Data системах и что общего между Росгвардией...

Жесткий режим карантина и самоизоляции из-за нового коронавируса кардинально изменил мировую экономику, сократив доходы большинства работающего населения. Однако, в некоторых отраслях наблюдается беспрецедентный рост продаж. Сегодня мы расскажем, какие компании продолжают успешно развиваться, несмотря на COVID-19 и вызванные им ограничительные меры. Спойлер: все они связаны с большими данными (Big Data)...

Цифровизация не всегда приносит только положительные результаты: увеличение прибыли, сокращение расходов и прочие бонусы оптимизации бизнеса. Большие данные – это большая ответственность, с которой справится не каждый. В этой статье мы собрали 5 самых ярких событий ИТ-мира за последнюю пару лет, связанных с большими данными (Big Data) и машинным обучением...

Вчера мы писали, что cybersecurity биометрии пока не слишком надежна: обмануть можно как дактилоскопический сканер на смартфоне, так и крупную систему больших данных (Big Data). Сегодня поговорим о мерах обеспечения информационной безопасности биометрических данных: многофакторной аутентификации, защите цифровых шаблонов и кратной верификации. А также расскажем, когда государственная цифровизация в России...

Сравнив между собой наиболее популярные методы биометрии, сегодня мы подробнее рассмотрим, насколько они устойчивы к фальсификациям. Читайте в этой статье, как хакеры обманывают сканер отпечатков пальцев, путают Big Data системы уличной видеоаналитики и выдают себя за другое лицо с помощью модной технологии машинного обучения (Machine Learning) под названием Deep Fake....
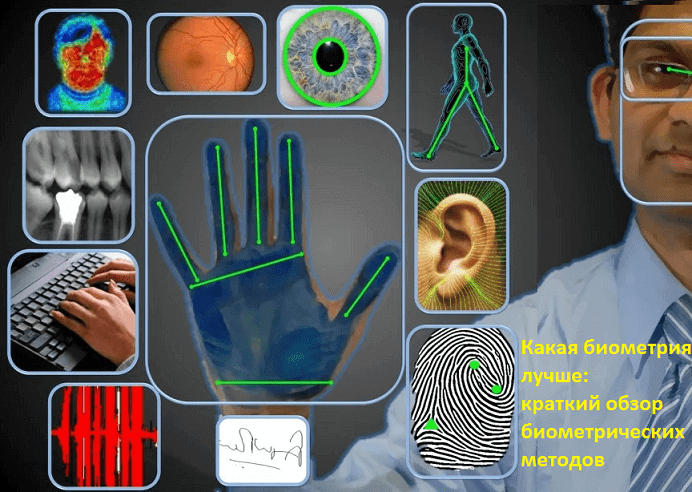
Продолжая рассматривать уязвимости биометрических систем, сегодня мы поговорим про отличия разных методов биометрии. Проанализируем быстроту их работы и устойчивость к фальсификации, а также используемые технологии Big Data и Machine Learning. Кроме того, сравним ставшие привычными способы идентификации личности по фотографии лица, снимкам глаз, отпечаткам пальцев и ладоней с более «экзотическими»...

В прошлой статье мы рассказывали о самых крупных утечках данных из биометрических Big Data систем в России и за рубежом. Сегодня рассмотрим характерные уязвимости биометрии: естественные ограничения методов идентификации личности с помощью машинного обучения (Machine Learning, ML) и целенаправленные атаки. 2 главные уязвимости биометрических Big Data систем на базе Machine...

В то время, как нацпрограма «Цифровая экономика» активно продвигает использование биометрических персональных данных россиян в качестве основных идентификаторов для государственных Big Data систем и коммерческих сервисов, информация продолжает утекать. В этой статье мы собрали наиболее крупные инциденты с утечками данных из биометрических систем в России и за рубежом. Как утекают...

Продолжая тему Cybersecurity, сегодня мы поговорим про биометрические системы: что это такое, как они работают и чем нарушают требования GDPR и № 152-ФЗ. Также в этом материале мы собрали для вас примеры таких наиболее известных проектов на базе технологий Big Data и Machine Learning. Что такое биометрические персональные данные и...

Сегодня мы коснемся процесса управления требованиями и рассмотрим, как техника SQUARE (Security Quality Requirements Engineering) помогает снизить риски в проектах по цифровизации бизнеса и разработке Big Data систем. Читайте в нашем материале, что такое информационная безопасность, BABOK и Gherkin, а также когда и как формулировать требования к cybersecurity на ранних...