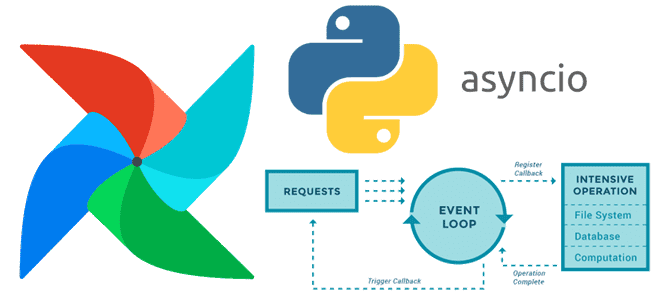
Почему триггеры отсроченных операторов Apache AirFlow не могут быть блокирующими и как сделать их асинхронными с помощью Python-библиотеки asyncio. Создание своего отсроченного оператора в Apache AirFlow О том, что такое отсроченные операторы, как они связаны с триггерами и асинхронными Python-вызовами в Apache AirFlow, мы недавно говорили здесь. Помимо использования существующих...
Почему производительность confluent-kafka выше, чем у kafka-python, чем еще отличаются эти Python-библиотеки для разработки клиентов Apache Kafka, и что выбирать. Сравнение Python-библиотек для разработки клиентов Kafka Хотя Java считается более подходящей для создания высоконагруженных приложений, многие разработчики используют Python, который намного проще. Этот язык программирования подходит даже для написания продюсеров...
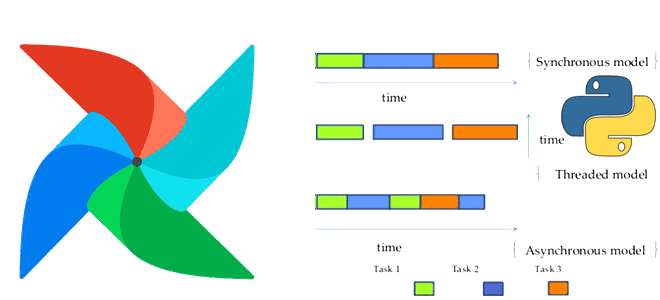
Что общего между триггерами, отсроченными операторами и асинхронными Python-вызовами в Apache AirFlow, чем они отличаются от стандартных операторов и сенсоров, для чего их использовать и как это сделать. Асинхронные вызовы и отсроченные операторы в Apache AirFlow В синхронном коде задачи выполняются последовательно, одна за другой. Причем каждая задача должна завершиться...
Почему параллельное выполнение заданий в Apache Spark зависит от языка программирования и как можно обойти однопоточную природу Python в PySpark. Что не так с параллельным выполнением заданий PySpark и как это исправить? Apache Spark позволяет писать распределенные приложения благодаря инструментам для распределения ресурсов между вычислительными процессами. В режиме кластера каждое...

Чем уязвимость устаревшего метода аутентификации OpenID в Flask-AppBuilder опасна для Apache AirFlow и как это исправить? Обзор уязвимости CVE-2024-25128. Уязвимости OpenID для FAB в Apache AirFlow В конце февраля 2024 выяснилось, что в прошлом релизе Apache AirFlow 2.8, вышедшем 14 декабря прошлого года, обнаружилась критическая уязвимость, набравшая более 9 баллов...

3 июня 2024 года вышел предварительный релиз Apache Spark 4.0. Эта версия еще не считается стабильной и предназначена только для ознакомления. Поэтому даже полноценные release notes по ней пока отсутствуют. Тем не менее, сегодня познакомимся с наиболее интересными фичами этого выпуска: новый тип данных VARIANT, API источника данных Python и...

Для чего смотреть планы выполнения запросов при работе с API pandas в Spark и как это сделать: примеры использования метода spark.explain() и его аргументов для вывода логических и физических планов. Разбираем на примере PySpark-скрипта. API pandas и физический план выполнения запроса в Apache Spark Мы уже писали, что PySpark, API-интерфейс...
Практическая демонстрация потокового SQL-конвейера, который преобразует данные, потребленные из Apache Kafka, и записывает результаты в Elasticsearch, используя Debezium-коннекторы и задания Apache Flink в облачной платформе Decodable. Потребление сообщений из Apache Kafka Я уже показывала пример интеграции Apache Kafka и Elasticsearch с помощью sink-коннектора, а также конвейер с ClickHouse Cloud. Сегодня...

Чем полезна интеграция ClickHouse с Apache Airflow и как ее реализовать: операторы в пакете провайдера и плагине на основе Python-драйвера. Принципы работы и примеры использования. 2 способа интеграции ClickHouse с AirFlow Продолжая разговор про интеграцию ClickHouse с другими системами, сегодня рассмотрим, как связать эту колоночную СУБД с мощным ETL-движком Apache...
Чем API TaskFlow отличается от традиционных операторов Apache Airflow, можно ли их использовать вместе и как это сделать для более эффективной передачи данных между задачами DAG с помощью механизма XCom: несколько примеров. Что такое API TaskFlow в Apache Airflow Чтобы реализовать конвейер обработки данных в Apache AirFlow, можно использовать традиционные...

Что такое assert, зачем это нужно в тестировании и отладке, как эта конструкция применяется для сравнения датафреймов в PySpark: примеры работы функций assertDataFrameEqual() и assertSchemaEqual() в Apache Spark. Что такое assert: конструкция тестирования При разработке PySpark-приложения дата-инженер чаще всего оперирует такими структурами данных, как датафрейм. Датафрейм (DataFrame) – это распределенная...
Версионирование схемы сообщений в формате AVRO с использованием реестра схем Apache Kafka и библиотеки confluent_kafka: практический пример на Python в Google Colab. Публикация сообщений в Kafka с использованием реестра схем Недавно я показывала пример использования реестра схем (Schema Registry) Apache Kafka при публикации сообщений. Сегодня рассмотрим версионирование схемы данных в...
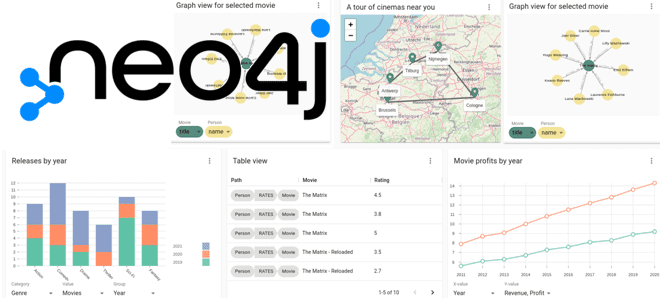
Создаем визуализации Cypher-запросов к своему графу в графовой базе данных Neo4j с помощью дэшборда NeoDash на примере анализа финансовых транзакций в банке. Python-генерация графа в Neo4j с фейковыми данными Поскольку NoSQL-СУБД Neo4j отлично подходит для задач графовой аналитики больших данных благодаря своей нативно графовой модели хранения данных, ее можно использовать...
Сегодня я покажу, как проверить доступность веб-сайта с помощью http-хука в Apache AirFlow и отправить результаты проверки в Телеграм-бот. Еще раз про хуки и соединения Apache AirFlow Доступность системы является ключевым свойством информационной безопасности. Проверить, что веб-сервис доступен, можно по статусу HTTP-ответа на GET-запрос. Чтобы делать такую проверку периодически, т.е....
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...
Сегодня я покажу пример использования реестра схем для Apache Kafka на платформе Upstash, API которого полностью совместим со Schema Registry от Confluent. Пишем продюсер на Python, используя библиотеку confluent_kafka. Еще раз о том, что такое реестр схем Kafka и чем он полезен Реестр схем (Schema Registry) – это модуль Confluent...
Зачем Databricks выпустил Arc, чем это отличается от Splink, и как эти инструменты позволяют решать проблему связывания данных с помощью алгоритмов машинного обучения. Как работает связывание данных Продолжая разговор про качество данных и разрешение сущностей (entity resolution) , сегодня подробно рассмотрим этап связывания записей с использованием логики на основе правил...

Зачем ограничивать доступ к папке с DAG и как это сделать: категории и роли пользователей в Apache AirFlow, способы входа в систему и конфигурации для настройки прав. Категории и роли пользователей Apache AirFlow Поскольку основным источником угрозы почти для любой информационной системы являются люди, при разработке методов обеспечения безопасности надо,...

Как спроектировать DAG и выбрать способ обмена данными между задачами, где определить подключения и запросы к БД и что поможет избежать ада Python-зависимостей при использовании Apache AirFlow. Сегодня я расскажу своем личном опыте наступания на грабли при работе с этим оркестратором batch-процессов и уроках, которые из этого вынесла. 5 советов...

Что необходимо реализовать в собственном процессоре, написанном на Python, чтобы запускать его в Apache NiFi. Классы и методы для настройки свойств, а также отношения и состояния жизненного цикла. Классы и методы для настройки свойств Предустановленные обработчики данных или процессоры (processor) Apache NiFi, написанные на Java, можно настроить прямо в GUI,...