
Что такое Python-декораторы в Airflow, зачем они нужны, какие они бывают и чем полезны: ликбез по TaskFlow API на практическом примере DAG. Что такое Python-декораторы в Airflow и какие они бывают Будучи написанным на Python, Apache Airflow использует именно этот язык в качестве средства разработки дата-конвейеров. После определения функции в...

Чем обмен данными через XCom отличается от использования Dataset и какой из механизмов выбирать для обмена данными между задачами Apache Airflow: разбираем на практическом примере. Обмен данными через XCom В Apache Airflow есть несколько механизмов для обмена данными между задачами: XCom и набор данных (Dataset). При общей цели они предназначены...
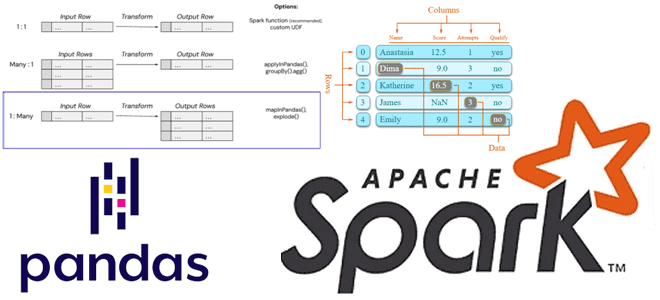
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах. Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в...

Как разработать свой плагин Apache AirFlow: пошаговое руководство с наглядной демонстрацией. Добавляем свои пункты меню в веб-интерфейс фреймворка и встраиваем пользовательскую HTML-страницу с новым эскизом Flask. Разработка своего плагина для AirFlow Вчера я рассказывала, как расширить функциональные возможности Apache AirFlow с помощью плагинов. Сегодня рассмотрим, как это сделать на практике....
Зачем нужны плагины в Apache AirFlow, как их создать и встроить в пакетный оркестратор для внедрения пользовательских операторов, хуков, датчиков или интерфейсов взаимодействия с внешними системами. Плагины AirFlow Продолжая недавний разговор про добавление пользовательского кода в Apache AirFlow, сегодня разберемся, как расширить функциональные возможности этого ETL-оркестратора с помощью встраиваемых модулей...

Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...
Как добавить пользовательский код в Apache AirFlow и где его хранить: лучшие практики и рекомендации для дата-инженера с примером создания и импорта своего пакета. Как хранить общий код в AirFlow Недавно мы писали про сложности управления DAG в многопользовательской среде Apache AirFlow. Однако, даже когда речь идет про однопользовательскую работу...
Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Как и зачем работать с ClickHouse без сервера СУБД ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно...

Что не так с работой Apache AirFlow в многопользовательской среде, зачем предоставлять каждой команде свое развертывание ETL-фреймворка, каковы недостатки этого решения и как организовать мультитенантный кластер. Почему Apache Airflow не предназначен для многопользовательского использования В современной дата-инженерии Apache AirFlow стал наиболее популярным инструментом для пакетных ETL-процессов. Чтобы использовать его наиболее...
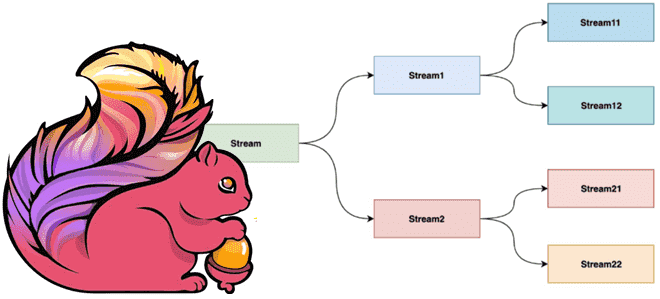
Что такое дополнительный выходной поток DataStream в Apache Flink, зачем это нужно, чем механизм SideOutput лучше операторов filter и split, а также как его использовать: примеры на Python. Что такое дополнительный выходной поток DataStream в Apache Flink и зачем это нужно Хотя выходные результаты большинства операторов API DataStream в Apache...
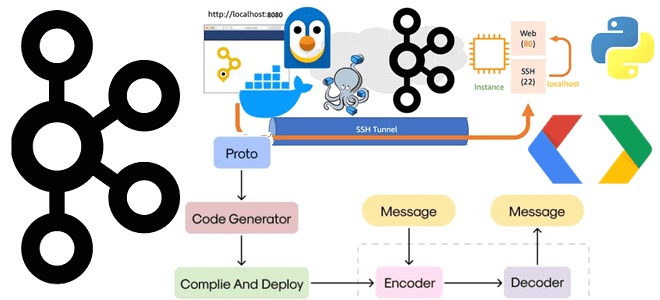
Как публиковать в топик Kafka сообщения в формате Protobuf, используя реестр схем и библиотеку confluent-kafka. Пример Python-продюсера, конфигурационного YAML-файла для Docker-развертывания Kafka Confluent и тунелирование портов локального компьютера. Подготовка инфраструктуры и определение схемы данных Чтобы публиковать в свое Docker-развертывание Kafka Confluent данные, используя реестр схем, нужно сперва внести изменения в...

Как устроен планировщик заданий Apache AirFlow, от чего зависит его производительность и какие конфигурации помогут ее улучшить: настройки, приемы, рекомендуемые значения и лучшие практики. Как работает планировщик Apache AirFlow Apache AirFlow как фреймворк оркестрации пакетных процессов включает несколько компонентов. Одним из них является планировщик (scheduler), который отслеживает все задачи и...
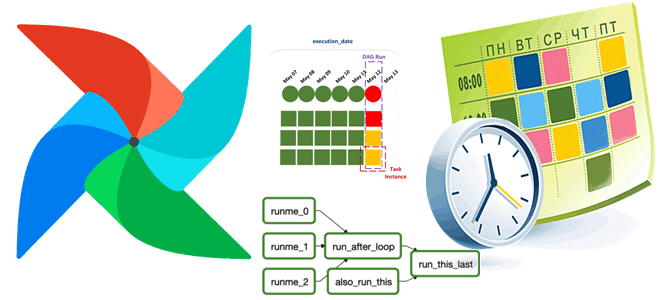
Чем планирование запуска DAG в Apache AirFlow с объектом timedelta отличается от использования cron-выражений, в чем разница CronTriggerTimetable и CronDataIntervalTimetable, а также как создать собственный класс расписания. Объект timedelta vs cron-выражение: задание расписания запуска DAG в Apache AirFlow Apache AirFlow идеально подходит для классических пакетных ETL-сценариев, например, когда надо извлечь...
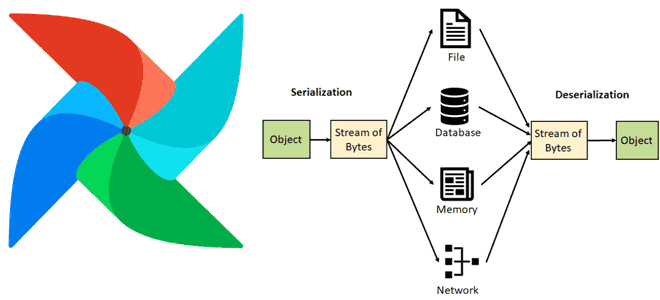
Как Apache AirFlow сериализует и десериализует данные, зачем с версии 2 включена обязательная сериализация DAG в JSON, почему для пользовательской сериализации рекомендуются словари или примитивы и что поможет сократить нагрузку на базу данных метаданных через настройку параметров сериализации в конфигурационном файле фреймворка. Сериализация данных в Apache AirFlow Чтобы сохранить данные...

24 августа вышел новый релиз Apache AirFlow. Знакомимся с новинками версии 2.10: гибкая настройка исполнителей для всей среды, конкретного DAG и отдельных задач, а также динамическое планирование набора данных и улучшения GUI. Гибкая настройка исполнителей Одной из самых главных новинок Apache AirFlow 2.10 стала конфигурация гибридного исполнения, позволяющая использовать несколько...

Как оповестить дата-инженера о задержке и результате выполнения задачи или всего DAG пакетного конвейера обработки данных: варианты отправки уведомлений в Apache AirFlow и особенности их применения. Варианты отправки уведомлений в Apache AirFlow Даже когда конвейер обработки данных разработан и успешно протестирован, в ходе его эксплуатации в рабочей среде неизбежно возникают...
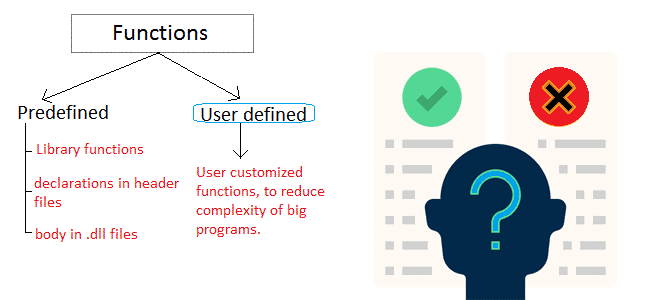
Почему пользовательские функции лучше применять как можно реже, каковы их возможности и ограничения: краткий обзор особенностей разработки и эксплуатации UDF в Apache Spark SQL, ksqlDB, Flink SQL, Greenplum и ClickHouse. Чем полезны и опасны пользовательские функции в обработке больших данных? Пользовательские функции (User-Defined Functions, UDF) позволяют разработчику расширить возможности фреймворка,...
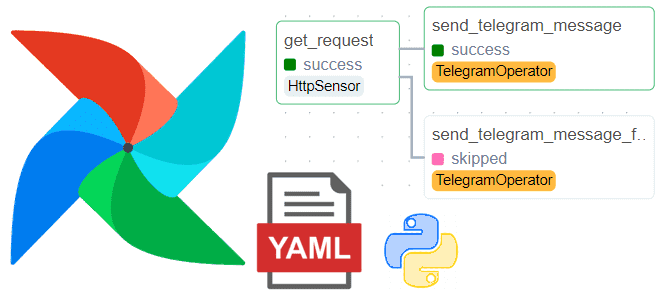
Как написать DAG в Apache AirFlow без программирования, определив его конфигурацию в YAML-файле, и автоматически получить пакетный конвейер обработки данных с помощью Python-библиотеки DAG Factory. Демократизация разработки ETL-конвейеров или что такое DAG Factory в Apache AirFlow Хотя Apache AirFlow и так считается довольно простым фреймворком для оркестрации пакетных процессов и...
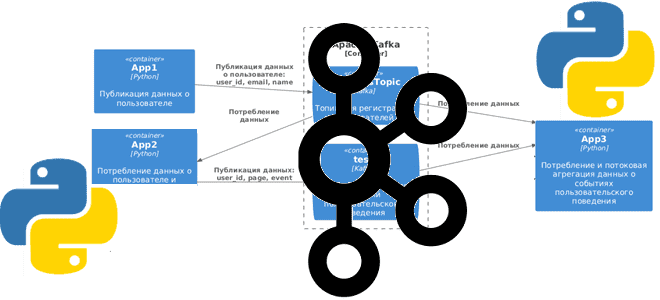
Сегодня я покажу простую демонстрацию потоковой агрегации данных из разных топиков Apache Kafka на примере Python-приложений для соединения событий пользовательского поведения с информацией о самом пользователе. Постановка задачи Рассмотрим примере кликстрима, т.е. потокового поступления данных о событиях пользовательского поведения на страницах сайта. Предположим, данные о самом пользователе: его идентификаторе, электронном...
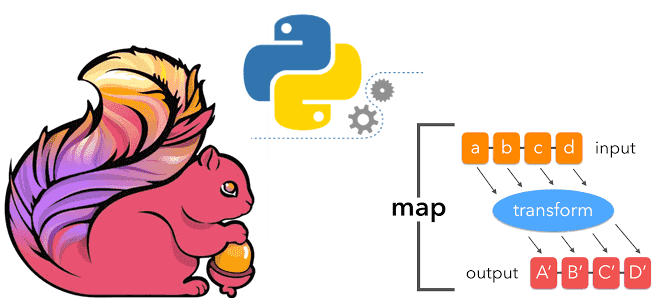
Что такое rich-функции в Apache Flink, зачем они нужны, чем отличаются от обыкновенных UDF и как с ними работать: простой пример на PyFlink с запуском в Google Colab. Rich-функции в Apache Flink Будучи очень мощным фреймворком для разработки распределенных потоковых приложений, Apache Flink не только предоставляет широкий набор stateful-функций, но...