Сегодня поговорим про особенности построения конвейеров машинного обучения в Apache Spark. Читайте далее, как Spark MLLib реализует идеи MLOps, что такое трансформеры и оценщики, из чего еще состоит Machine Learning pipeline, как он работает с кодом на Scala, Java, Python и R, а также каковы условия практического использования методов fit(),...
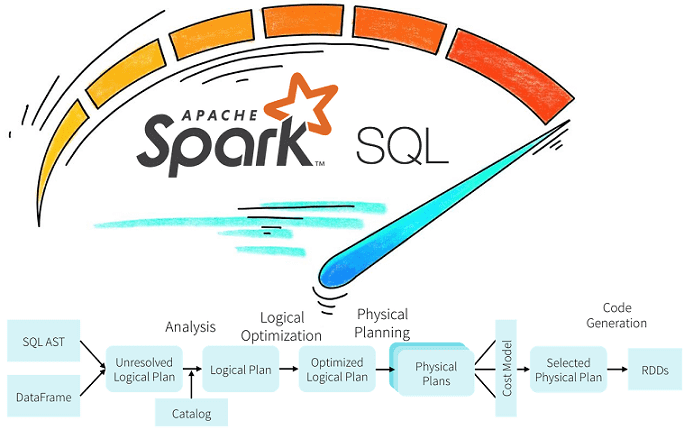
Продолжая разбирать практические особенности аналитики больших данных с Apache Spark, сегодня рассмотрим возможности оптимизации SQL-запросов в этом Big Data фреймворке с помощью механизмов предикатного и проекционного сжатия. Читайте далее про реализацию Predicate Pushdown и Projection Pushdown в Apache Spark 3, а также их связь с форматами Parquet и AVRO. Механизмы...

Говоря про обучение Apache Spark для разработчиков, сегодня мы рассмотрим, как быстро конвертировать Python-скрипты в задания PySpark и какие конфигурационные параметры при этом нужно настроить, чтобы эффективно использовать все возможности распределенных вычислений над большими данными (Big Data). Читайте далее, чем отличаются датафреймы в Pandas и Apache Spark, для чего нужны...

Обработка данных является одной из самых первоочередных задач анализа Big Data. Сегодня мы расскажем о самых полезных преобразованиях PySpark, которые можно выполнить над столбцами. Читайте далее, как привести значения к 0 или 1, как преобразовать из строк в числа и обратно, а также как обработать недостающие значения(Nan) с примерами в...

Продолжаем говорить о NLP в PySpark. После того как тексты обработаны: удалены стоп-слова и проведена лемматизация — их следует векторизовать для последующей передачи алгоритмам Machine Learning. Сегодня мы расскажем о 3-x методах векторизации текстов в PySpark. Читайте в этой статье: применение CountVectorizer для подсчета встречаемости слов, уточнение важности слов с...

В одной из прошлых статей мы говорили о методах NLP (natural language processing) в PySpark. Сегодня мы покажем, как обработать реальный датасет, который содержит тексты на русском языке. Читайте у нас: удаление знаков пунктуации, символов и стоп-слов, токенизация и лемматизация на примере новостей на русском языке. Датасет с текстами на...
В прошлый раз мы говорили о методах NLP в PySpark. Сегодня рассмотрим методы нормализации и стандартизации данных модуля ML библиотеки PySpark. Читайте в нашей статье: применение Normalizer, StandardScaler, MinMaxScaler и MaxAbsScaler для нормализация и стандартизации данных. Нормализация и стандартизация — методы шкалирования данных Нормализация (normalization) и стандартизация (standardization) являются методами...

Говоря про перспективы развития экосистемы Apache Hadoop с учетом современного тренда на SaaS-подход к работе с большими данными (Big Data), сегодня мы рассмотрим, как работает коннектор облачного хранилища Google для этого фреймворка. Читайте далее, чем HCFS отличается от HDFS и каковы преимущества практического использования Google Cloud Storage Connector for Hadoop....

Обработка естественного языка (Natural Language Processing, NLP) является перспективным направлением Data Science и Big Data. Сегодня мы расскажем вам о применении методов NLP в PySpark. В этой статье вы узнаете об обычной токенизации и на основе регулярных выражений, стоп-словах русского и английского языков, а также о N-граммах в PySpark. Токенизация...

Чтобы сделать наши курсы по Spark еще более интересными и добавить в них самые актуальные тренды, сегодня мы расскажем о новом релизе этого Big Data фреймворка. Читайте далее, что нового в Apache Spark 3.0 и почему Spark SQL стал еще лучше. 10 лет в Big Data или немного истории В...
В прошлый раз мы говорили о решении задачи классификации в рамках Machine Learning с помощью PySpark MLlib. Сегодня рассмотрим задачу регрессии. Читайте далее: что такое линейная регрессия, L1 и L2 регуляризация, алгоритм подбора значений гиперпараметров Grid Search, а также применение кросс-валидации в PySpark. Датасет с домами на продажу Обучать модель...

PySpark позволяет работать не только с большими данными (Big data), но и создавать модели машинного обучения (Machine Learning). Сегодня мы расскажем вам о модуле ML и покажем, как обучить модель Machine Learning для решения задачи классификации. Читайте у нас: подготовка данных, применение логистической регрессии, а также использование метрик качеств в...

В прошлый раз мы говорили о том, как установить PySpark в Google Colab, а также скачали датасет с помощью Kaggle API. Сегодня на примере этого датасета покажем, как применять операции SQL в PySpark в рамках анализа Big Data. Читайте далее про вывод статистической информации, фильтрацию, группировку и агрегирование больших данных...

Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...
Недавно мы рассказывали, что такое PySpark. Сегодня рассмотрим, как подключить PySpark в Google Colab, а также как скачать датасет из Kaggle прямо в Google Colab, без непосредственной загрузки программ и датасетов на локальный компьютер. Google Colab Google Colab — выполняемый документ, который позволяет писать, запускать и делиться своим Python-кодом через...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
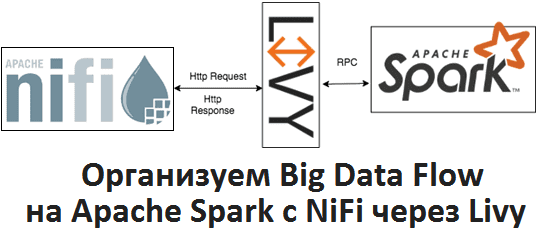
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Python считается из основных языков программирования в областях Data Science и Big Data, поэтому не удивительно, что Apache Spark предлагает интерфейс и для него. Data Scientist’ы, которые знают Python, могут запросто производить параллельные вычисления с PySpark. Читайте в нашей статье об инициализации Spark-приложения в Python, различии между Pandas и PySpark,...