
12 апреля 2023 года вышел очередной релиз Apache Spark. Разбираемся с самыми главными новинками этого выпуска, которые порадуют аналитиков, разработчиков, инженеров данных и специалистов по Data Science. Расширенная поддержка Python, улучшения Spark SQL и Structured Streaming. Обновления Spark SQL и новинки для пользователей Python Apache Spark 3.4.0 — это пятый...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...

Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...
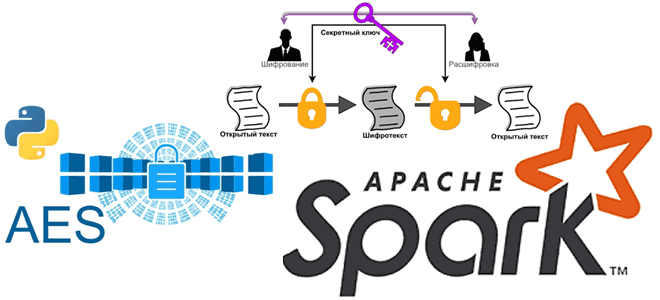
Мы уже писали про использование криптографии в Apache Spark. Сегодня в рамках обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как шифровать столбцы датафрейма в PySpark и расшифровывать их с использованием алгоритма шифрования AES. Основы кибербезопасности: ликбез по шифрованию данных Шифрование данных преобразует данные в другую форму или код, чтобы их...
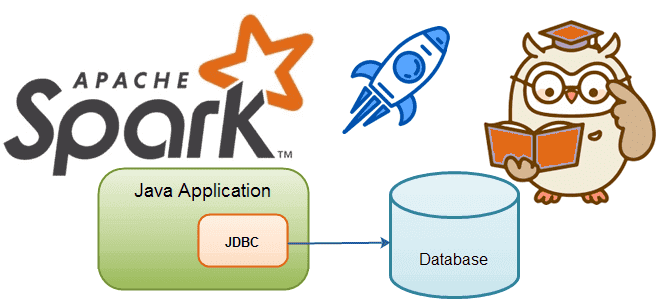
Сегодня разберем тему, важную для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Почему чтение данных из реляционных баз в Apache Spark может быть медленным и как его ускорить, изменив SQL-запрос или структуру таблицы. JDBC-источники данных для Apache Spark Apache Spark является средством обработки, а не хранения больших данных. Поэтому, чтобы использовать...

Чтобы добавить в наши практические курсы по Apache Spark еще больше приемов, полезных для дата-инженеров и разработчиков, сегодня рассмотрим, как упаковать PySpark-приложение, используя нативные Python-функции и сторонние решения. Отличия Virtualenv от PEX и Conda. 4 способа упаковать PySpark-приложение для запуска в кластере Apache Spark Разработчики распределенных приложений знают, что недостаточно...
Чтобы добавить в наши курсы для дата-инженеров и разработчиков распределенных приложений еще больше практических примеров, сегодня рассмотрим, как написать Python-код для вычисления задержки потребителя Apache Kafka, расширив типовой слушатель StreamingQueryListener, который есть в Java и Scala API библиотеки Spark Structured Streaming, но недоступен в PySpark. Проблема отставания потребителя Apache Kafka...

Сегодня разберемся, когда для Data Science-проектов вместо Apache Spark, самого популярного вычислительного движка аналитики больших данных, стоить выбрать Dask – легковесную Python-библиотеку для параллельных вычислений. И, наоборот, в каких случаях инженер данных и Data Scientist получают преимущества, выбирая Spark. Что такое Dask и зачем он нужен Data Scientist’у Прежде чем...

16 июня 2022 года вышла новая версия Apache Spark – 3.3.0. Разбираем главные фичи этого минорного релиза, особенно важные для дата-инженера и разработчика распределенных приложений: от расширения поддержки ANSI SQL до профилирования UDF на Python. Главные изменения Apache Spark 3.3.0 Apache Spark 3.3.0 — это четвертый релиз линейки 3.x, в...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...

Специально для обучения начинающих аналитиков данных и дата-инженеров сегодня рассмотрим примеры выполнения простых SQL-запросов и оконных функций в Apache Spark на Google Colab. Как быстро проанализировать датафрейм из CSV-файлов с помощью нескольких строк на PySpark. Запуск и использование PySpark в Google Colab Предположим, необходимо определить потенциальный доход от проведения обучающих...
Мы уже рассказывали про функции перераспределения данных по разделам coalesce() и repartition(). Сегодня сравним их работу с еще одним методом управления разделами в Apache Spark и разберем, как все они могут помочь дата-инженеру и разработчику распределенных приложений повысить эффективность этого популярного фреймворка аналитики больших данных. Отобрать и поделить: лучшие практики партиционирования данных...
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого...
В этой статье для дата-инженеров и аналитиков данных, рассмотрим, что такое широковещательные соединение в Apache Spark SQL, чем оно полезно и как работает на практических примерах. BROADCAST JOIN в SELECT-запросах Spark SQL, а также краткий ликбез по подсказкам или хинтам. Что такое широковещательное соединение в Apache Spark SQL Распределенная природа...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, как повысить эффективность выполнения Python-кода с помощью кросс-языковой платформы Apache Arrow. Что такое PyArrow и как это улучшает производительность PySpark-программ. Почему Spark Java быстрее PySpark и как это исправить с Apache Arrow Будучи популярным вычислительным движком в области Big Data, Apache...

Постоянно добавляя в наши курсы по Apache Spark и машинному обучению практические примеры для эффективного повышения квалификации Data Scientist’ов и инженеров данных, сегодня рассмотрим задачу пакетного прогнозирования и планирование ее запуска по расписанию без применения масштабных MLOps-решений. Apache Spark для пакетного прогнозирования Есть много готовых решений и инструментов для пакетного...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...

Практический пример аналитики больших данных в реальном времени с Apache Spark, Kafka, ClickHouse и AWS S3: возможности, архитектура, также специально для дата-инженеров и разработчиков распределенных приложений рассмотрим, сколько времени нужно для разрешения каждого вызова API в определенном временном диапазоне. Анализ событий пользовательского поведения в реальном времени Основным продуктом международной ИТ-компании...
Сегодня рассмотрим, как загружать большие объемы данных из REST API-сервисов с Apache Spark, написав на PySpark собственную UDF-функцию с преобразованием withColumn(), чтобы воспользоваться всеми преимуществами распределенных вычислений этого фреймворка. Локальное исполнение на драйвере и распараллеливание REST-API вызовов в Apache Spark Мы уже рассказывали, что конвертация Python-скрипта в распределенный код Apache...

В этой статье для дата-инженеров и аналитиков рассмотрим пример мониторинга состояния электрогенераторов с помощью анализа данных временных рядов и ранжирования в pandas для предупреждения выхода оборудования из строя. А также разберем основы анализа временных рядов на больших данных с открытой библиотекой Flint для Apache Spark. Постановка задачи: температура и производительность...