
Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

Чтобы показать, насколько разной бывает аналитика больших данных, сегодня рассмотрим кейс международной компании Spidertracks, которая с помощью технологий Big Data создает ИТ-решения для отслеживания, связи и управления безопасностью воздушных судов. Читайте далее, почему для потоковой обработки событий был выбран Kinesis Analytics for SQL, а не конвейер из Apache Kafka и...

Отвечая на вопрос, что такое большие данные для чайников, сегодня мы рассмотрим 3 практических примера использования технологий Big Data в малом и среднем бизнесе. Никакой Rocket Science, только понятные кейсы, которые актуальны для любой современной компании, даже если она состоит из пары человек: аналитика больших данных и машинное обучение для...
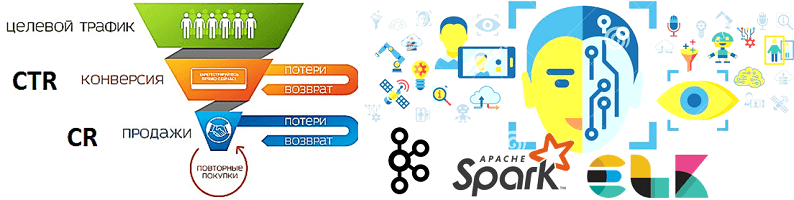
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
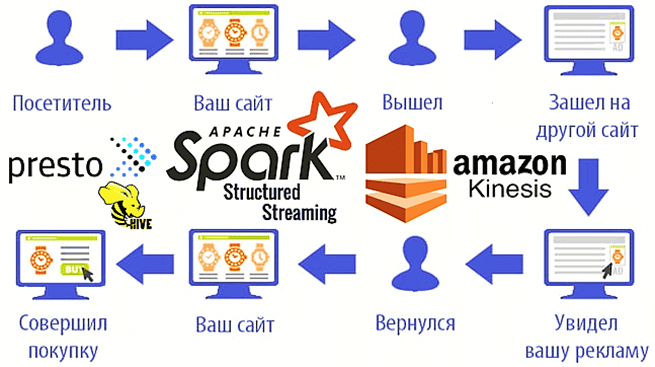
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

Интерактивная аналитика больших данных - одно из самых востребованных и коммерциализированных приложений для технологий Big Data. В этой статье мы рассмотрим, как крупный британский ритейлер запустил цифровую трансформацию своей ИТ-архитектуры, уходя от традиционного DWH с пакетной обработкой к событийно-стриминговой облачной платформе на базе Apache Kafka и Snowflake. Зачем модному ритейлеру...

В этой статье разберем, что такое прикладная аналитика больших данных на примере практического использования Apache Kafka и Druid в Netflix для обработки и визуализации метрик пользовательского поведения. Читайте далее, зачем самой популярной стриминговой компании отслеживать показатели клиентских устройств и как это реализуется с помощью Apache Druid, Kafka и других технологий...

Недавно мы рассказывали про систему онлайн-аналитики Big Data на базе Apache Kafka, Spark Streaming и Druid для площадки рекламных ссылок Outbrain, а затем на этом же кейсе рассматривали, зачем нужен Graceful shutdown в потоковой обработке больших данных. Сегодня в рамках этого примера разберем, как снизить нагрузку при потоковой передаче множества...

Продолжая разбирать, как работает аналитика больших данных на практических примерах, сегодня мы рассмотрим, что такое Graceful shutdown в Apache Spark Streaming. Читайте далее, как устроен этот механизм «плавного» завершения Спарк-заданий и чем он полезен при потоковой обработке больших данных в рамках непрерывных конвейеров на базе Apache Kafka и других технологий...

Современная аналитика больших данных ориентируется на обработку Big Data в реальном времени. Такие вычисления «на лету» позволяют в режиме онлайн узнавать о критически важных производственных показателях и оперативно понимать клиентские потребности. Это существенно ускоряет и автоматизирует цикл принятия управленческих решений в соответствии с требованиями сегодняшнего бизнеса. Обычно для реализации архитектуры...
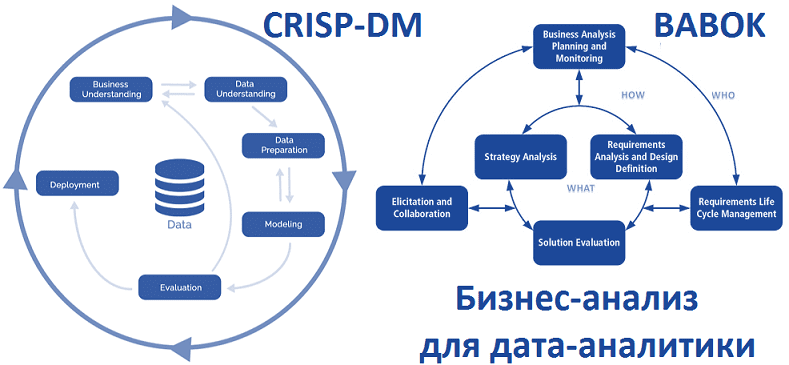
Мы уже рассказывали, что цифровизация и другие масштабные проекты внедрения технологий Big Data должны обязательно сопровождаться процедурами бизнес-анализа, начиная от выявления требований на старте до оценки эффективности уже эксплуатируемого решения. Сегодня рассмотрим, как задачи бизнес-анализа из руководства BABOK®Guide коррелируют с этапами методологии исследования данных CRISP-DM, которая считается стандартом де-факто в...

Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...

В продолжении темы про текущее состояние и ожидаемые тренды цифровой трансформации отечественных предприятий, сегодня мы рассмотрим, что мешает директору по цифровизации успешно воплощать стратегию корпоративного изменения. Читайте далее, с какими основными трудностями сталкивается Chief Digital Transformation Officer (CDTO) и как их обойти. 5 проблем CDTO: главные факторы, препятствующие цифровой трансформации...

Недавно мы писали про 5 главных факторов, которые сдерживают цифровизацию бизнеса и государства по версии аналитического агентства Gartner. Сегодня поговорим про динамику отечественной цифровой трансформации, рассмотрев соответствующий отчет российского исследовательского бюро KMDA. Читайте в нашей статье, какие отрасли в России могут считать себя data-driven, от чего зависит успех цифровизации и...

Сегодня мы расскажем о важности прикладного бизнес-анализа в проектах Big Data, включая цифровизацию частного бизнеса и государственных предприятий. Читайте в нашей статье, как области знаний профессионального руководства по бизнес-анализу BABOK®Guide соответствуют типовым этапам внедрения технологий больших данных в корпоративную деятельность, и почему цифровая трансформация любой компании – это, прежде всего,...

Мы уже писали о преимуществах DaaS-похода, когда облачные провайдеры предоставляют данные как услугу, включая сложную предиктивную аналитику с использованием алгоритмов машинного обучения. Это позволяет быстро и удобно воспользоваться технологиями Big Data без существенных инвестиций в ИТ-инфраструктуру и дорогих специалистов, таких как Data Scientist, инженер и аналитик больших данных. Однако все...

Недавно мы рассказывали, что аналитика больших данных с помощью технологий Big Data – это необязательно удел только крупных корпораций. В этой статье мы рассмотрим реальный бизнес-кейс, как извлечь выгоду из накопленных данных о своих пользователях, применяя для этого возможности NoSQL-СУБД Elasticsearch для полнотекстового поиска по полуструктурированным данным и веб-интерфейс визуализации...