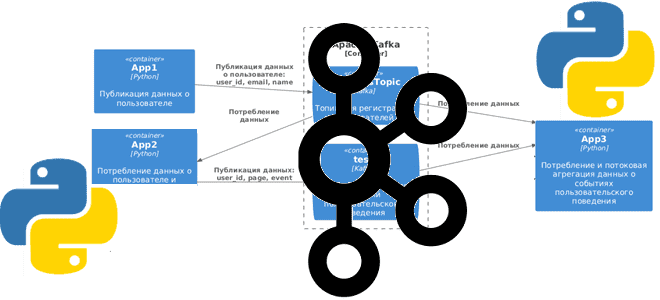
Сегодня я покажу простую демонстрацию потоковой агрегации данных из разных топиков Apache Kafka на примере Python-приложений для соединения событий пользовательского поведения с информацией о самом пользователе. Постановка задачи Рассмотрим примере кликстрима, т.е. потокового поступления данных о событиях пользовательского поведения на страницах сайта. Предположим, данные о самом пользователе: его идентификаторе, электронном...
Что такое rich-функции в Apache Flink, зачем они нужны, чем отличаются от обыкновенных UDF и как с ними работать: простой пример на PyFlink с запуском в Google Colab. Rich-функции в Apache Flink Будучи очень мощным фреймворком для разработки распределенных потоковых приложений, Apache Flink не только предоставляет широкий набор stateful-функций, но...

20 июня 2024 года вышел очередной релиз Greenplum. Разбираемся с ключевыми новинками выпуска 7.2: сканирование индекса в AO-таблицах, изменения в оптимизаторе GPORCA, улучшенная обработка геопространственных данных и новая служба централизованного управления сегментами Postmaster. Новинки Greenplum 7.2 для дата-инженера Начнем с изменений, повышающих производительность Greenplum. Одним из них стало сканирование индекса...
Почему триггеры отсроченных операторов Apache AirFlow не могут быть блокирующими и как сделать их асинхронными с помощью Python-библиотеки asyncio. Создание своего отсроченного оператора в Apache AirFlow О том, что такое отсроченные операторы, как они связаны с триггерами и асинхронными Python-вызовами в Apache AirFlow, мы недавно говорили здесь. Помимо использования существующих...
Почему производительность confluent-kafka выше, чем у kafka-python, чем еще отличаются эти Python-библиотеки для разработки клиентов Apache Kafka, и что выбирать. Сравнение Python-библиотек для разработки клиентов Kafka Хотя Java считается более подходящей для создания высоконагруженных приложений, многие разработчики используют Python, который намного проще. Этот язык программирования подходит даже для написания продюсеров...
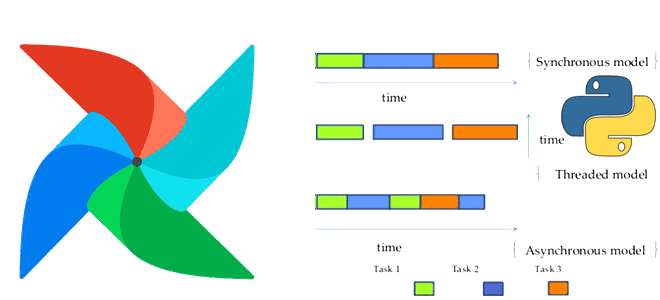
Что общего между триггерами, отсроченными операторами и асинхронными Python-вызовами в Apache AirFlow, чем они отличаются от стандартных операторов и сенсоров, для чего их использовать и как это сделать. Асинхронные вызовы и отсроченные операторы в Apache AirFlow В синхронном коде задачи выполняются последовательно, одна за другой. Причем каждая задача должна завершиться...
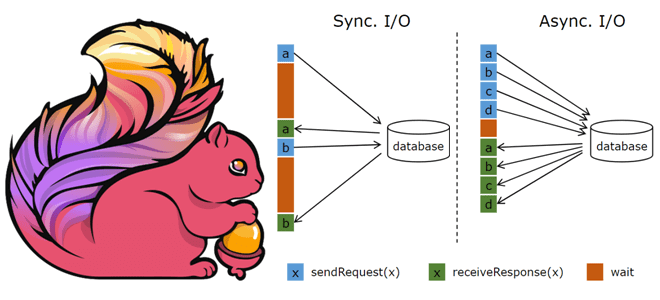
API асинхронного ввода-вывода в Apache Flink и как его использовать для асинхронной интеграции данных из внешней системы с потоком событий. Основы асинхронной обработки в Apache Flink Обогащение потоков данных информацией из внешних систем является довольно сложным кейсом из-за необходимости синхронизировать скорость поступления событий с задержкой доступа к внешнему источнику. При...

Как устроен потоковый запрос Spark Structured Streaming на уровне кода: интерфейсы, их методы и как их настроить, создание и запуск StreamingQuery. Создание потокового запроса в Spark Structured Streaming Хотя структурированная потоковая передача Spark основана на SQL-движке этого фреймворка, в ней гораздо больше сложных абстракций. Например, с точки зрения программирования потоковый...

1 июля 2024 г. опубликован очередной выпуск Apache NiFi 2.0.0. Знакомимся с его наиболее интересными добавлениями и улучшениями: критические изменения, обновленная интеграция с Kafka и новые процессоры для работы с файлами разных форматов. Обновленная интеграция с Kafka и другие новинки Apache NiFi 2.0.0-M4 Выпуск мажорного релиза не всегда происходит одним...
Почему параллельное выполнение заданий в Apache Spark зависит от языка программирования и как можно обойти однопоточную природу Python в PySpark. Что не так с параллельным выполнением заданий PySpark и как это исправить? Apache Spark позволяет писать распределенные приложения благодаря инструментам для распределения ресурсов между вычислительными процессами. В режиме кластера каждое...
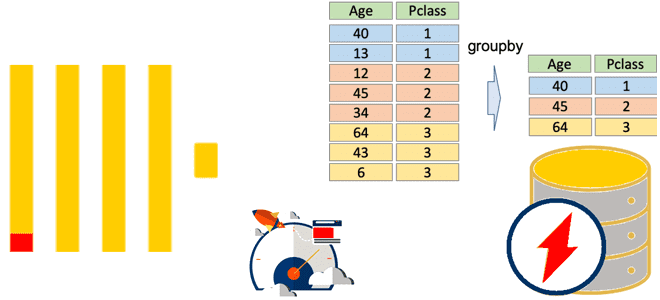
Как работают агрегатные функции в ClickHouse, почему SQL-запросы с GROUP BY потребляют много памяти и что поможет сделать их быстрее и эффективнее: лайфхаки многопоточной агрегации в колоночной базе данных. Особенности выполнения оператора GROUP BY в ClickHouse Агрегатные функции позволяют вычислить экстремум (минимум/максимум), среднее значение, количество, сумму или другое результирующее значение...
Что такое вебхук и как отправить событие из PostgreSQL в Apache Kafka, используя API Webhook на платформе Upstash. NoCode-интеграция БД и брокера сообщений: практический пример. Практический пример: CDC из PostgreSQL в Kafka через веб-хуки Веб-хук или перехватчик – это настраиваемый обратный HTTP-вызов из одной системы к другой. Он используется для...

Как размер пакета, режим вывода и интервал срабатывания триггера потоковой обработки влияют на скорость вычислений в приложении Apache Spark Structured Streaming и как настроить эти параметры. Размер пакета при потоковой обработке данных в Spark Streaming Хотя скорость обработки данных средствами Apache Spark Streaming зависит от многих факторов, включая саму структуру...
Почему в ClickHouse нет полноценных транзакций, но введена экспериментальная поддержка ACID для операций вставки в таблицы движка MergeTree, как это реализуется и чем синхронная вставка отличается от асинхронной. Особенности операций вставки в ClickHouse В ClickHouse нет полноценных транзакций, поскольку это колоночное хранилище в первую очередь ориентировано на чтение большого объема...
Какие SQL-команды есть в Greenplum для транзакционной обработки данных, как MVCC исключает явные блокировки, можно ли установить их вручную и как это сделать: режимы блокировки и глобальный детектор взаимоблокировок в MPP-СУБД. Транзакции, MVCC и режимы блокировки Greenplum Про изоляцию транзакций в Greenplum и Arenadata DB мы уже писали здесь. Транзакции...
Как Apache Kafka использует страничный кэш операционной системы, какие конфигураций файловой системы надо настраивать для повышения пропускной способности и снижения задержки и каковы недостатки RAID-массивов для надежного хранения опубликованных сообщений. Страничный кэш ОС и быстродействие Kafka В отличие от RabbitMQ, Apache Kafka может обеспечить долговременное хранение сообщений, записывая их на...
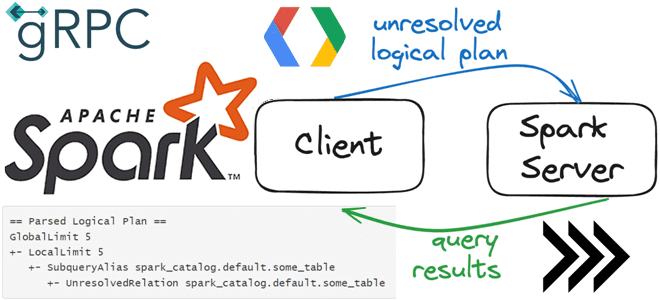
Что общего у клиент-серверной архитектуры Spark Connect с JDBC-драйвером подключения к БД, как взаимодействуют клиент и сервер по gRPC, как подключиться к серверу и указать обязательность поля в схеме proto-сообщения. Как работает Spark Connect О том, что представляет собой Spark Connect и зачем нужен этот клиентский API, позволяющий удаленно подключаться...

3 июня 2024 года вышел предварительный релиз Apache Spark 4.0. Эта версия еще не считается стабильной и предназначена только для ознакомления. Поэтому даже полноценные release notes по ней пока отсутствуют. Тем не менее, сегодня познакомимся с наиболее интересными фичами этого выпуска: новый тип данных VARIANT, API источника данных Python и...

Почему потоковый сервер Greenplum выгружает данные во внешние системы пакетно: тонкости утилиты gpfdist и YAML-файла конфигурации выгрузки. Возможности и ограничения GPSS-сервера при выгрузке данных во внешние системы из MPP-СУБД. Потоковый сервер Greenplum Ключевым отличием Greenplum от PostgreSQL является поддержка механизма массово-параллельной обработки, благодаря чему эта MPP-СУБД относится к стеку Big...
Как изменить приоритет задачи в очереди исполнителя Apache AirFlow, на что влияет метод определения весов, каким образом можно балансировать нагрузку с помощью пулов и зачем настраивать количество слотов. Как приоритизировать задачи в очереди Apache AirFlow Дата-инженеры, которые используют Apache AirFlow для оркестрации пакетных процессов, знают, что задачи скапливаются в очереди...