
Какие задачи решают инженеры и администраторы кластера для организации многопользовательского доступа к платформе потоковой передачи событий, а также чем полезен фреймворк Strimzi для развертывания и сопровождения мультиарендной среды Apache Kafka на Kubernetes. Задачи управления мультипользовательским кластером Kafka Выступая в качестве средства интеграции информационных систем и микросервисов, в корпоративной среде Apache...
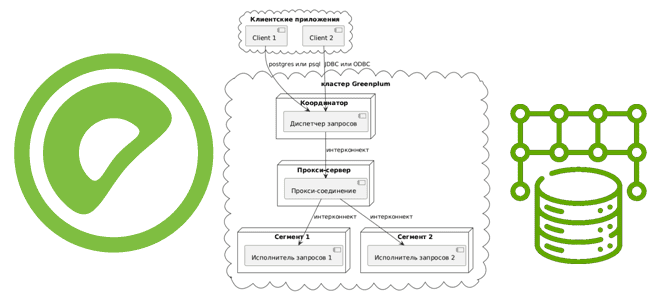
Как сегменты Greenplum взаимодействуют друг с другом для выполнения распределенных SQL-запросов, чем UDPIFC-режим интерконнекта лучше TCP-протокола, зачем проксировать межсетевые соединения и какими командами это сделать. Что такое интерконнекты в Greenplum Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных. Точкой входа в...
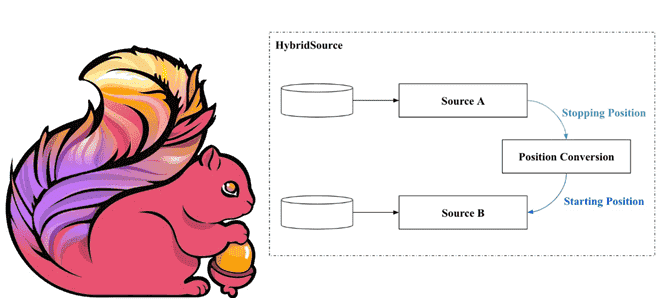
Как задание Apache Flink может читать информацию из разных источников данных в одном потоке. Что такое HybridSource и как с ним работать: разбираем на примере файла и топика Kafka. Что такое гибридный источник данных Иногда заданию Flink необходимо считывать данные из нескольких источников в последовательном порядке. Напомним, источником данных для...

23 октября 2024 года опубликован предварительный выпуск Apache Flink. Знакомимся с самыми яркими новинками этого мажорного релиза: удаленные API, коннекторы и конфигурации, динамическая оптимизация логических планов, а также дизагрегированное состояние и управление им. Критические изменения: удаление устаревших компонентов Начнем с критических изменений, связанных с удалением устаревших компонентов. В Apache Flink...

Чем обмен данными через XCom отличается от использования Dataset и какой из механизмов выбирать для обмена данными между задачами Apache Airflow: разбираем на практическом примере. Обмен данными через XCom В Apache Airflow есть несколько механизмов для обмена данными между задачами: XCom и набор данных (Dataset). При общей цели они предназначены...
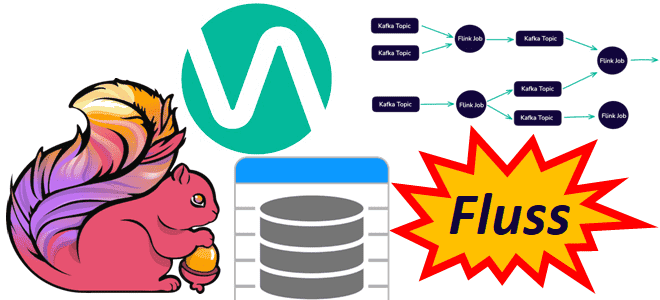
Чтобы сделать конвейеры обработки данных еще более эффективными, устраняя промежуточные хранилища для потоковых вычислений и сократить количество ETL-инструментов, немецкая компания Ververica разработала Fluss – потоковое хранилище для Apache Flink. Читайте далее, что это и чем полезно в непрерывной обработке потоков Big Data. Что не так с архитектурой конвейеров обработки данных...
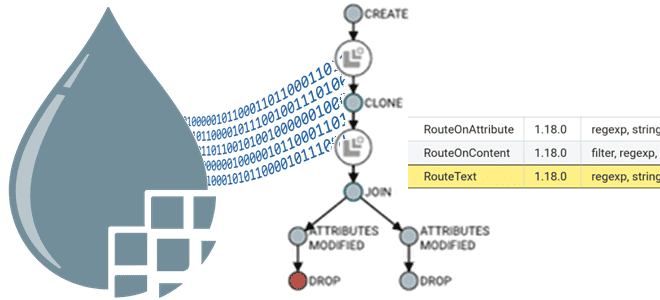
Чем процессор RouteOnContent отличается от RouteOnAttribute и RouteText: преимущества и недостатки каждого из них для маршрутизации FlowFile в Apache NiFi, варианты использования каждого из них с примерами. Маршрутизация на основе контента Как мы уже отмечали в прошлой статье, маршрутизация FlowFile в в Apache NiFi может быть на основе контента, т.е....
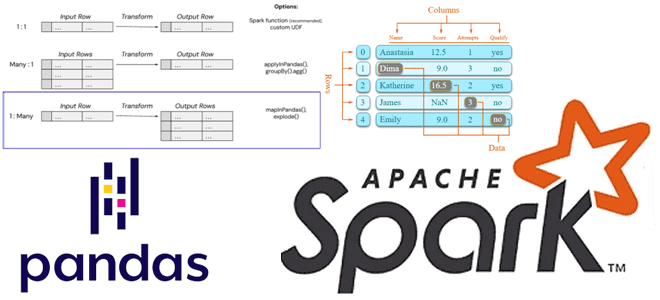
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах. Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в...

Как разработать свой плагин Apache AirFlow: пошаговое руководство с наглядной демонстрацией. Добавляем свои пункты меню в веб-интерфейс фреймворка и встраиваем пользовательскую HTML-страницу с новым эскизом Flask. Разработка своего плагина для AirFlow Вчера я рассказывала, как расширить функциональные возможности Apache AirFlow с помощью плагинов. Сегодня рассмотрим, как это сделать на практике....
Зачем нужны плагины в Apache AirFlow, как их создать и встроить в пакетный оркестратор для внедрения пользовательских операторов, хуков, датчиков или интерфейсов взаимодействия с внешними системами. Плагины AirFlow Продолжая недавний разговор про добавление пользовательского кода в Apache AirFlow, сегодня разберемся, как расширить функциональные возможности этого ETL-оркестратора с помощью встраиваемых модулей...
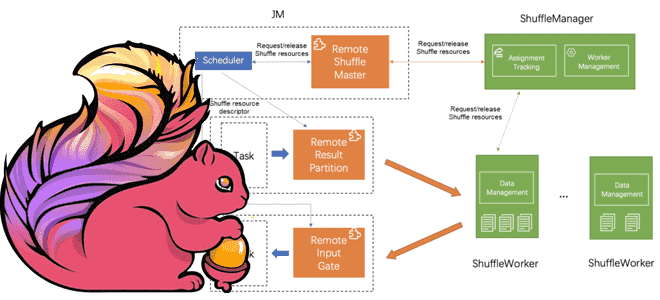
Что такое Remote Shuffle Service в Apache Flink, зачем это нужно и как служба удаленного перемешивания позволяет создавать масштабируемые и надежные приложения для унифицированной потоковой и пакетной обработки больших объемов данных. Что такое Remote Shuffle Service в Apache Flink Apache Flink рассматривает пакетную обработку как частный случай потоковых вычислений. Однако,...

4 октября 2024 года вышел очередной релиз ClickHouse. Знакомимся с его самыми интересными особенностями: добавление строк в обновляемые материализованные представления, агрегатные функции для типов данных JSON и Dynamic, поддержка заголовков HTTP-ответов, автозамена строк с overlay-командами и другие новинки выпуска 24.9. Обновляемые материализованные представления Начнем с наиболее значимой новой функции ClickHouse...

Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...
Как добавить пользовательский код в Apache AirFlow и где его хранить: лучшие практики и рекомендации для дата-инженера с примером создания и импорта своего пакета. Как хранить общий код в AirFlow Недавно мы писали про сложности управления DAG в многопользовательской среде Apache AirFlow. Однако, даже когда речь идет про однопользовательскую работу...
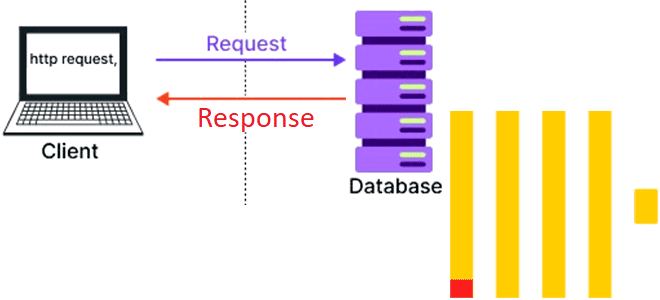
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....
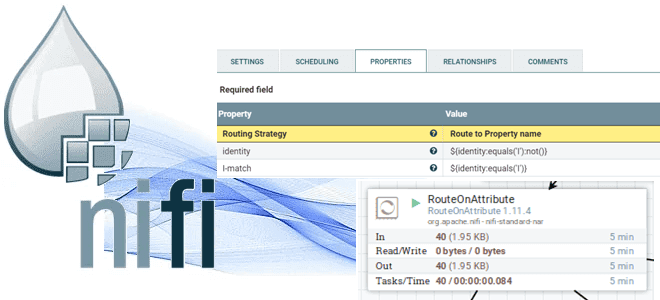
Что такое атрибуты FlowFile, какие процессоры есть в Apache NiFi для работы с ними и как маршрутизировать поток данных на основе пользовательских свойств. Атрибуты FlowFile и процессоры для работы с ними Основной единицей данных, которая перемещается через систему в Apache NiFi является FlowFile. Он представляет собой контейнер для данных и...
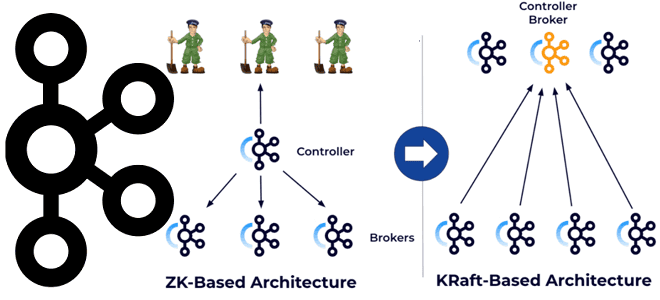
Как перевести кластер Kafka с ZooKeeper на KRaft, чтобы обеспечить управление метаданными с помощью этого протокола консенсуса: последовательность действий и настройки конфигураций. Зачем и как переводить Apache Kafka с Zookeeper на KRaft Напомним, протокол KRaft, который заменяет ZooKeeper для управления метаданными и консенсуса кластера Kafka, был введен еще в версии...

Зачем в Apache Flink 1.20 добавлена новая функция восстановления пакетных заданий после сбоя JobMaster, как она работает и какие параметры надо настроить для повышения ее эффективности. Восстановление пакетных заданий Flink после сбоя JobMaster Как и любой фреймворк стека Big Data, Apache Flink включает множество компонентов, каждый из которых выполняет конкретную...
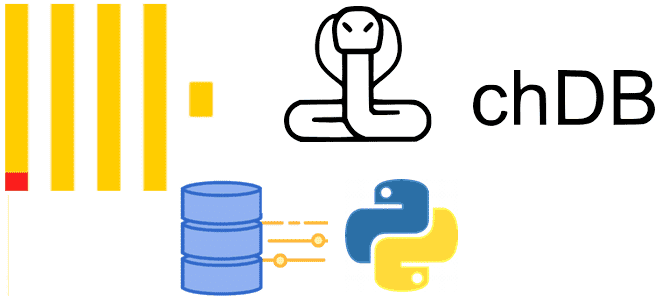
Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Как и зачем работать с ClickHouse без сервера СУБД ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно...
Что такое волатильные функции, зачем они нужны и чем опасны: разбираем на примере Greenplum и PostgreSQL. К чему приведет некорректное использование атрибутов изменчивости в SQL-запросе или UDF-функции распределенной MPP-СУБД. Что такое волатильность функции и почему это важно для Greenplum Волатильной или изменчивой считается функция, значение которой может изменяться даже в...