
Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
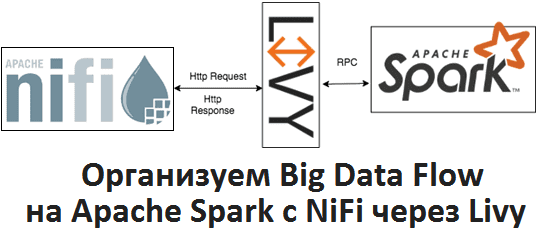
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...
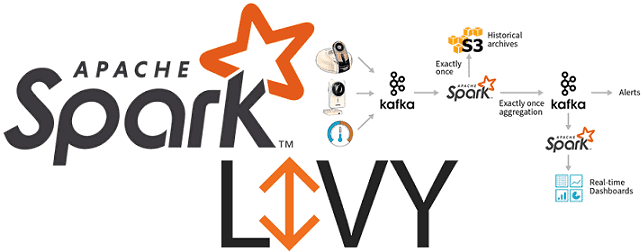
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...
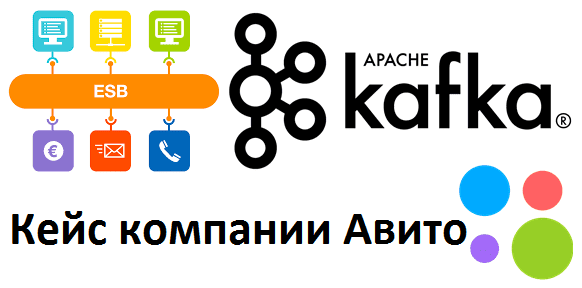
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru. Что такое ESB и чем это отличается от брокера сообщений...
Сегодня рассмотрим примеры совместного использования двух популярных технологий потоковой обработки больших данных (Big Data): Apache Kafka и NiFi. Читайте в нашей статье, как они дополняют друг друга, каковы преимущества их объединения и каким образом инженеру Data Flow это реализовать на практике. Еще раз о том, что такое Apache Kafka и...

В этой статье мы рассмотрим несколько популярных мифов о Data Science и аналитике больших данных (Big Data), разобрав, когда и почему простое использование BI-систем или облачных DaaS-платформ бывает гораздо эффективнее попыток внедрения алгоритмов машинного обучения (Machine Learning) и прочих методов Data Science в операционные и стратегические бизнес-процессы. Почему 80% Data...

Администрирование кластера Kafka порой напоминает работу детектива, когда нужно понять мотив преступления причину появления того или иного бага и устранить ее вместе с последствиями наиболее оптимальным способом. В этой статье мы рассмотрим несколько практических примеров конфигурирования Apache Kafka из опыта компании Booking.com, кейс которой был представлен в докладе ее сотрудника...

В продолжении серии статей по докладу Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим некоторые проблемы администрирования Apache Kafka, с которыми можно столкнуться на практике. Читайте в этом материале, как не допустить разрастание топика, правильно задав параметр CreateTime. Что делать,...

Аутентификация – далеко не единственная возможность обеспечения информационной безопасности в Apache Kafka. Сегодня мы продолжим разговор про Big Data cybersecurity и рассмотрим особенности авторизации в Apache Kafka в формате самообслуживания (self-service), как это было сделано в travel-компании Booking.com. В качестве примера продолжим разбирать доклад Александра Миронова, который был представлен 23...

Продолжая разбирать доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим, с какими проблемами столкнулись администраторы Big Data при обеспечении информационной безопасности своих Кафка-кластеров. Читайте в нашей статье про возможные методы аутентификации в Apache Kafka и их практическое использование в...

Сегодня мы разберем доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech [1]. Читайте в нашей статье, как одна из ведущих travel-компаний использует Apache Kafka, с какими проблемами столкнулись администраторы ее Big Data инфраструктуры и DevOps-инженеры, а также почему были выбраны именно такие...

Завершая серию статей про DaaS-подход, сегодня рассмотрим наиболее популярные решения класса Data as a Service, а также поговорим, какое место в этой области занимают маркетплейсы/биржи данных и DMP-платформы. Читайте в нашей статье, как заработать на информации о своих пользователях и получить аналитику больших данных для бизнес-инсайтов без локального развертывания сложной...

В этой статье продолжим разбираться с DaaS-подходом и рассмотрим несколько реальных кейсов, когда бизнес выбирал услугу «данные как сервис» у облачного провайдера и какую практическую пользу, а также проблемы это принесло. Читайте в нашей статье, как концепция Data as a Service влияет на деятельность частных компаний и целых государств, а...

Аналитика больших данных (Big Data) сегодня нужна всем компаниям, но далеко не каждое предприятия готово инвестировать в сложную ИТ-инфраструктуру и дорогих специалистов. Избежать этих затрат, получив все преимущества практического использования технологий Data Science, поможет парадигма «данные как сервис». В продолжение темы по цифровизации, сегодня поговорим про концепцию Data as a...

В этой статье рассмотрим, как технологии Industry 4.0 помогают российскому нефтехимическому холдингу СИБУР повысить операционную эффективность производства и обеспечить безопасность труда. Сегодня мы собрали для вас 5 примеров практического использования различных методов и инструментов Big Data, Machine Learning, Industrial Internet of Things (IIoT), а также XR (AR+VR). Зачем нефтехимикам технологии...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

Недавно мы разбирали особенности интеграции Apache Kudu и Spark. В продолжение этой темы, сегодня поговорим про некоторые особенности выполнения SQL-операций с данными при интеграции этих Big Data фреймворков, а также рассмотрим пример записи данных в мульти-мастерный кластер Куду через Impala с помощью API Data Frame на PySpark. Что приносит Kudu...