
Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...

Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
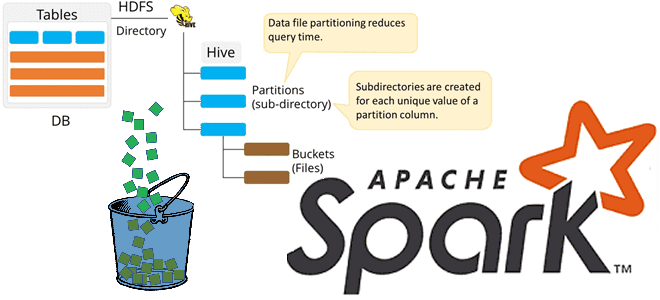
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Вчера мы говорили про важные обновления Apache Kafka 2.8.0, помимо долгожданного KIP-500, который позволяет избавиться от Zookeeper для синхронизации метаданных в распределенном кластере с помощью встроенного Quorum Controller. Сегодня рассмотрим, какие KIP’ы нового релиза коснулись одного из основных инструментов разработчика Apache Kafka – библиотеки Streams для создания распределенных приложений потоковой...

KIP-500, который позволяет наконец-то избавиться от Zookeeper в кластере Apache Kafka, заменив его Quorum Controller – далеко не единственное важное обновление в релизе 2.8.0. Сегодня рассмотрим, какие еще улучшения реализованы в новой версии главной Big Data платформы потоковой обработки событий, выпущенной в апреле 2021 года. Apache Kafka 2.8.0: новинки главных...
Продолжая говорить про обучение разработчиков и администраторов Apache Kafka, сегодня разберем сложности семантики строго однократной доставки сообщений (exactly once) в случае нескольких экземплярах, находящихся в разных кластерах. Читайте далее, что не так с межкластерными транзакциями, какие KIP’ы связаны с этой проблемой и при чем здесь MirrorMaker. Что не так с...

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...
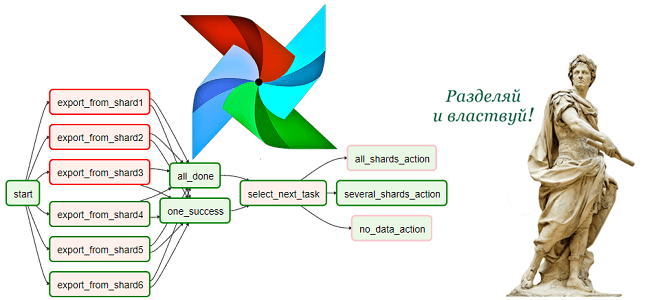
Чтобы сделать обучение дата-инженеров еще более полезным, сегодня мы рассмотрим проблему управления взаимозависимыми цепочками задач в Apache AirFlow. Читайте далее, как бразильская ИТ-компания QuintoAndar разработала промежуточный компонент Mediator на базе одноименного шаблона архитектурного проектирования ПО, чтобы облегчить взаимодействие между разными DAG’ами в конвейерах обработки больших данных. Проблема взаимозависимых DAG’ов в...
Сегодня рассмотрим важную тему из курсов для разработчиков и администраторов Apache Kafka: как сэкономить место на диске и увеличить пропускную способность всей Big Data системы на базе этой платформы потоковой обработки событий. Читайте далее, зачем добавлять задержку перед отправкой сообщений брокеру, как кодеки сжатия помогут снизить затраты на облачный Kafka-кластер...

В этой статье продолжим говорить про обучение разработчиков Apache Spark и рассмотрим, какие сегменты памяти есть в этом Big Data фреймворке и как с ними работать наиболее эффективно. Читайте далее, почему процессы PySpark и SparkR потребляют внешнюю память, чем пользовательская память кучи JVM отличается от памяти хранилища и какие конфигурации...

Продолжая разговор про практическое обучение разработчиков Apache Spark, сегодня рассмотрим пример повышения скорости выполнения SQL-запросов к большому датафрейму. Читайте далее, как определить и исправить асимметрию распределения данных по разделам, зачем добавлять контрольные точки в длинные DAG и в чем здесь опасность, чем хороша широковещательная трансляция, для чего фильтровать данные перед...

На практике каждый аналитик Big Data и Data Scientist часто сталкивается с удалением дублирующихся значений в датасете. Поэтому, чтобы добавить в наши курсы по Apache Spark еще больше полезных примеров, сегодня рассмотрим 5 простых способов решения этой востребованной задачи. Читайте далее, чем distinct() отличается от dropDuplicates(), а reduceByKey() - от...

Дополняя наши курсы по Apache Kafka практическими примерами, сегодня рассмотрим, как загрузить в топик данные из ответа REST API или HTTP-запроса. Читайте далее, что такое cURL и какие команды нужно отправить через эту утилиту, чтобы записать в Kafka сообщения из JSON-файла. REST API, HTTP и сURL Импорт данных из REST...

Практическое обучение дата-инженеров – это не просто курсы по основам Big Data, а полезные рекомендации с реальными примерами. Поэтому сегодня рассмотрим, как работать с DAG в Apache AirFlow еще эффективнее с помощью параметров конфигурации, плагинов, меток, шаблонов, переменных и еще 10 различных инструментов. 15 лучших практики для DAG в Apache...

В рамках обучения дата-инженеров, сегодня рассмотрим проблему роста числа операций ввода-вывода в секунду (IOPS) при обработке большого количества данных в потоках Apache NiFi и способы ее решения. Читайте далее, как перемещение репозиториев NiFi с жесткого диска в оперативную память снижает IOPS, а также зачем при этом в Big Data систему...

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS...

Поскольку наши курсы по Apache Spark предполагают практическое обучение с глубоким погружением в особенности разработки и настройки распределенных приложений, сегодня рассмотрим, как именно выполняются кластерные вычисления в рамках этого Big Data фреймворка. Читайте далее, из чего состоит архитектура Spark-приложения, как связаны SparkContext и SparkConf, а также зачем ограничивать размер драйвера...

Чтобы добавить в наши обновленные авторские курсы для дата-инженеров по Apache AirFlow еще больше интересного, сегодня продолжим разбирать полезные дополнения релиза 2.0 и поговорим, почему разделение фреймворка на пакеты делает его еще удобнее. Также рассмотрим практический пример создания общедоступного провайдера из локального Python-пакета с собственными операторами, хуками и прочими компонентами....

Продолжая вчерашний разговор про потоковую аналитику больших данных на Apache Kafka и Pinot, сегодня рассмотрим особенности интеграции этих систем. Читайте далее, как входные данные Kafka разделяются, реплицируются и индексируются в Pinot, каким образом выполняется обработка данных через распределенные SQL-запросы. Также разберем, почему управление памятью серверов Pinot, потребляющих данные из Kafka,...