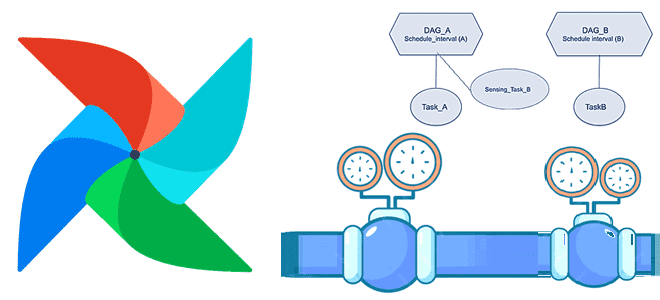
Мы уже писали про датчики или сенсоры - особый тип операторов Apache AirFlow, предназначенных для ожидания какого-то события. Сегодня рассмотрим практический пример обучения дата-инженеров и разработчиков по использованию внешнего сенсора в рамках типовой задачи дата-инженерии по организации ETL/ELT-процессов при поэтапной загрузке данных в DWH для OLAP-систем. Постановка задачи: поэтапная загрузка...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop рассмотрим, что такое Cloudera Data Platform Operational Database, как это связано с Apache HBase и Phoenix. Также разберем, каким образом перенести данные из кластера HBase в Cloudera Operational Database, избежав их потери и других подводных камней. Что такое Cloudera Operational Database: назначение...
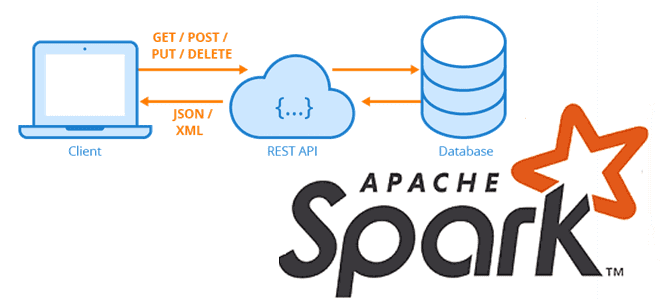
Сегодня рассмотрим, как загружать большие объемы данных из REST API-сервисов с Apache Spark, написав на PySpark собственную UDF-функцию с преобразованием withColumn(), чтобы воспользоваться всеми преимуществами распределенных вычислений этого фреймворка. Локальное исполнение на драйвере и распараллеливание REST-API вызовов в Apache Spark Мы уже рассказывали, что конвертация Python-скрипта в распределенный код Apache...

В феврале 2022 года вышел новый релиз Cloudera Flow Management 2.1.3 для совместного использования с Cloudera Manager и CDP Private Cloud Base 7.1.7. Этот выпуск основан на Apache NiFi 1.15, о новинках которого мы ранее рассказывали здесь, здесь и здесь. Сейчас рассмотрим основные преимущества этого решения. 5 главных улучшений в...

Сегодня поговорим про администрирование кластера Apache Kafka и разработку потоковых приложений передачи и разберем, как обеспечить их работу в бессерверном режиме с платформой Upstash. Финансовая экономия, простота сопровождения и другие преимущества FaaS-сервисов и serverless-подхода с RESTfull API для обработки событий в реальном времени. Снова про serverless: что такое Upstash Kafka...
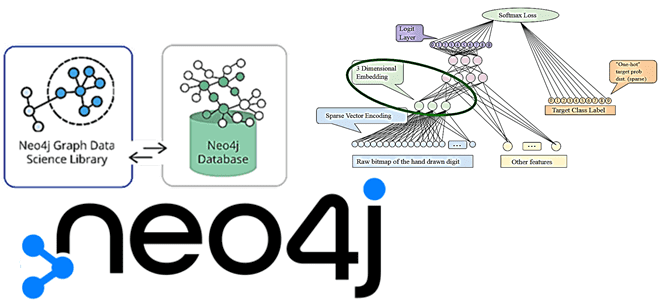
В рамках нашего нового курса графовым алгоритмам в бизнес-приложениях, сегодня разберем эмбеддинг-алгоритмы в библиотеке Graph Data Science СУБД Neo4j: их особенности и возможности практического использования для задач обработки естественного языка (NLP). Также рассмотрим, чем FastRP отличается от GraphSAGE с Node2Vec. NLP, эмбеддинги и Graph Data Science В обработке естественного языка...

Что такое Hive Transform, зачем это нужно дата-инженеру и разработчику распределенных приложений, где и как использовать эту функцию популярного средства SQL-on-Hadoop. Краткий обзор альтернативного способа операций с данными в Apache Hive, его возможности и ограничения, а также связь с HiveQL. Преобразования в Apache Hive Apache Hive – это популярная экосистема...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...

В октябре прошлого года вышел крупный релиз Apache AirFlow 2.2.0. Разбираем его главные фичи, которые больше всего интересны с точки зрения инженерии данных: пользовательские расписания и декораторы, отложенные задачи, а также валидация параметров DAG по JSON-схеме. Краткий обзор обновлений AirFlow 2.2.0 Хотя последней версией популярного batch-планировщика задач Apache Airflow на...
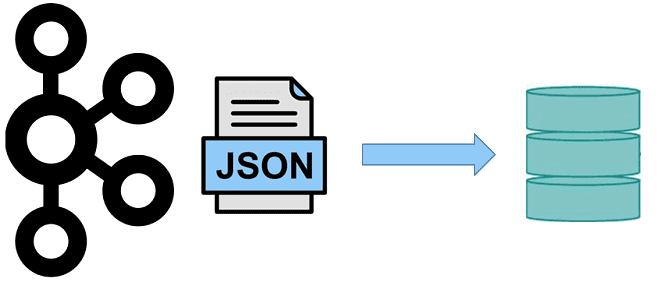
Мы уже рассматривали особенности обработки вложенных структур данных на примере парсинга JSON-файлов с Apache Spark и Hive. Развивая эту тему, сегодня поговорим про перенос записей с вложенными массивами из топиков Apache Kafka в реляционные СУБД с пользовательскими SMT-преобразователями и JDBC-коннектором: кейс для разработчиков. Проблемы обработки сложных структур данных с JDBC-коннектором...
Сегодня рассмотрим, как использовать статистический язык R для анализа данных в Greenplum. Что такое GreenplumR, как работает этот интерактивный клиент, чем он полезен специалисту по Data Science и каковы недостатки этого инструмента аналитики больших данных. Что такое GreenplumR Хотя основным языком в области Data Science сегодня считается Python, иногда специалисты...

В рамках нашего нового курса по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим популярную сегодня тему про невзаимозаменяемые токены в криптовалютах и не только. Пример анализа графа по NFT-транзакциям в графовой СУБД Neo4j с помощью инструкций языка запросов Cypher. Что такое NFT и причем здесь блокчейн с криптовалютами Уникальный или невзаимозаменяемый...

Недавно мы писали про декабрьский релиз Apache NiFi. Спустя месяц, 18 января 2022 года сообщество выпустило новую версию фреймворка – 1.15.3 с аутентифицированным доступом к SFTP-серверам через прокси-серверы SOCKS и улучшенным потреблением памяти. Разбираем 9 исправленных багов и 2 улучшения, а также особенности миграции на свежий выпуск. Снова про библиотеки...

В этой статье для дата-инженеров и аналитиков рассмотрим пример мониторинга состояния электрогенераторов с помощью анализа данных временных рядов и ранжирования в pandas для предупреждения выхода оборудования из строя. А также разберем основы анализа временных рядов на больших данных с открытой библиотекой Flint для Apache Spark. Постановка задачи: температура и производительность...
Сегодня заглянем под капот особых операторов Apache AirFlow, разберемся с режимами работы датчиков, а также рассмотрим, как создать собственный сенсор. Краткий ликбез по разработке своего sensor’а с лучшими практиками настройки и использования в DAG’ах AirFlow. Что такое сенсор: краткий ликбез по AirFlow Сенсоры или датчики AirFlow — это особый тип...
Вчера мы писали о недавно вышедшем свежем релизе Apache Kafka 3.1.0, который вышел в январе 2022 года. Сегодня рассмотрим, как безболезненно перейти на эту версию и избежать возможных побочных эффектов, связанных с некоторыми архитектурными изменениями платформы. Побочные эффекты и подводные камни обновления Напомним, в Apache Kafka 3.1.0 добавлена новая фича...

24 января 2022 года вышел новый релиз Apache Kafka. Главные новинки самой последней на сегодня стабильной версии 3.1.0: добавленные фичи, улучшения и исправленные баги краткий обзор для разработчиков распределенных приложений Kafka Streams и администраторов кластера этой платформы потоковой передачи событий. Новинки Apache Kafka 3.1.0 для администратора кластера В свежем релизе...
Недавно мы писали про архитектурный шаблон CQRS и его реализацию на базе Apache Kafka. В продолжение этой темы для обучения ИТ-архитекторов и разработчиков Big Data приложений, сегодня рассмотрим еще несколько популярных шаблонов проектирования распределенных систем: достоинства, недостатки, примеры реализации и способы их использования. Шаблоны проектирования распределенных систем: что это и...

Развивая наши курсы по Apache Spark и AirFlow для дата-инженеров и администраторов кластеров, сегодня рассмотрим кейс крупного маркетплейса Joom по переходу от 2-ой версии фреймворка на облачной платформе EMR к развертыванию сотен распределенных заданий на 3-ей версии в Amazon Elastic Kubernetes Service. Про сокращение расходов, повышение производительности и апдейт вычислительных движков. Постановка...
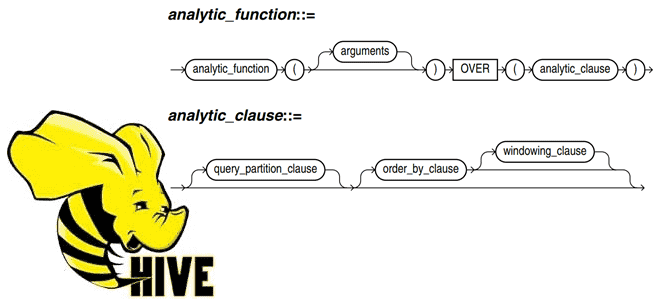
Постоянно добавляя в наши курсы по SQL-on-Hadoop для дата-инженеров и разработчиков распределенных приложений интересные примеры, сегодня рассмотрим пару практических техник по работе с Apache Hive. Читайте далее, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank(). Генерация порядкового номера строки...