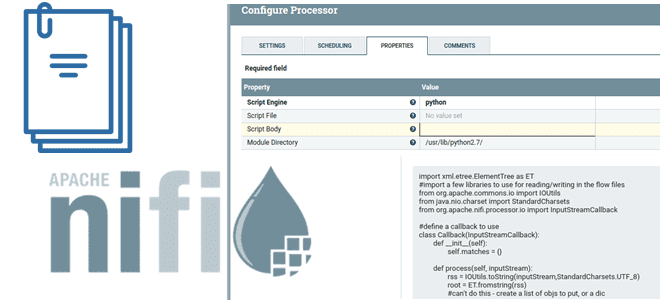
В этой статье для дата-инженеров разберемся, что такое NiFi Scripted Components и как они заполняют пробел между скриптами и пользовательскими компонентами: процессорами, контроллерами, сообщениями и средствами их чтения/записи. Рассмотрим примеры скиптовых процессоров и сервисов, а также определим реальные достоинства и недостатки этих компонентов. Почему просто скриптовых процессоров Apache NiFi недостаточно?...

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...

Весна богата на новые релизы: в начале мая 2022 года вышел Apache Flink 1.15. Рассказываем, что нового в свежем выпуске: краткий обзор самых полезных фич для разработчика распределенных приложений, а также интересные изменения, исправления ошибок и улучшения для дата-инженера. Scala под капотом и спецификация REST API по стандарту OpenAPI Apache...

30 апреля 2022 года вышел новый релиз Apache Airflow, который содержит более 700 коммитов с предыдущей версии 2.2.0 и включает 50 новых функций, 99 улучшений, 85 исправлений ошибок и несколько изменений в документации. Разбираемся, что особенно важно для дата-инженера в Apache Airflow 2.3.0. ТОП-7 главных фич Apache AirFlow 2.3.0: краткий...
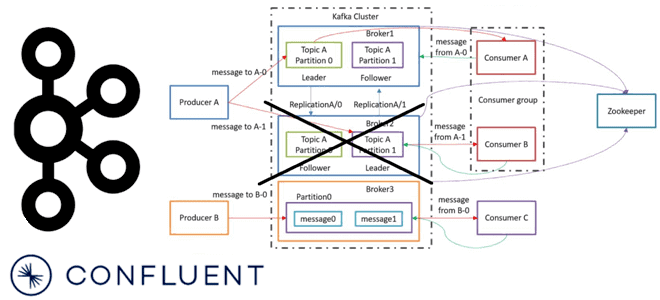
Сегодня рассмотрим важную для обучения администраторов кластера Apache Kafka тему про удаление брокеров. Что происходит, когда администратор удаляет брокер Kafka из кластера, какие сложности при этом могут возникнуть и как с ними справляется решение на базе платформы Confluent. Как вручную удалить брокер Kafka из кластера: краткий guide администратора На первый...

Специально для обучения начинающих аналитиков данных и дата-инженеров сегодня рассмотрим примеры выполнения простых SQL-запросов и оконных функций в Apache Spark на Google Colab. Как быстро проанализировать датафрейм из CSV-файлов с помощью нескольких строк на PySpark. Запуск и использование PySpark в Google Colab Предположим, необходимо определить потенциальный доход от проведения обучающих...

Сегодня в рамках продвижения нашего курса по графовой аналитике больших данных в бизнес-приложениях, рассмотрим новый инструмент популярной графовой СУБД Neo4j для загрузки данных - Data Importer. Что это такое, как работает, чем полезно специалисту по Data Science и зачем обновлять его до последней версии. Что такое Neo4j Data Importer Графовая...

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi. Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт)....
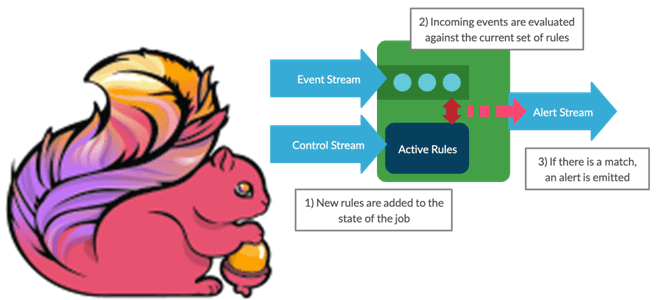
Мы уже писали про динамическое изменение правил фильтрации без перезапуска Flink-приложений. В продолжение этой темы в рамках продвижения нашего нового курса по потоковой обработке данных помощью Apache Flink, сегодня рассмотрим, как избежать неравномерного распределения данных во время выполнения программы. Больше 3-х не собираться: бизнес-правила и динамика разделения данных Перекос или...
Мы уже рассматривали, как загрузить в Greenplum большие объемы данных. В продолжение этой важной для обучения дата-инженеров темы, сегодня разберем еще несколько инструментов, решающих задачу организации ETL-процессов с этой MPP-СУБД. ETL-инструменты PostgreSQL Хотя Greenplum может хранить и обрабатывать огромные наборы данных на уровне петабайт, эта СУБД не генерирует их самостоятельно,...

Проблема своевременного пополнения товарных запасов актуальна для любого ритейлера. Разбираемся, как торговый гигант США Walmart построил свою платформу планирования и пополнения продукции в реальном времени на базе Apache Kafka: ключевые требования к системе, архитектура и принципы работы, настройка конфигураций продюсеров и потребителей. Постановка задачи: пополнение товарного запаса в реальном времени...
Интеграция Apache Airflow с инструментами CI/CD является одной из лучших практик современной дата-инженерии, о чем мы недавно писали. Читайте далее, зачем нужно управлять кодом DAG с помощью популярных систем управления версиями и как это сделать на примере GitLab CI/CD. Сложности управления DAG в разных средах AirFlow Apache Airflow считается наиболее...
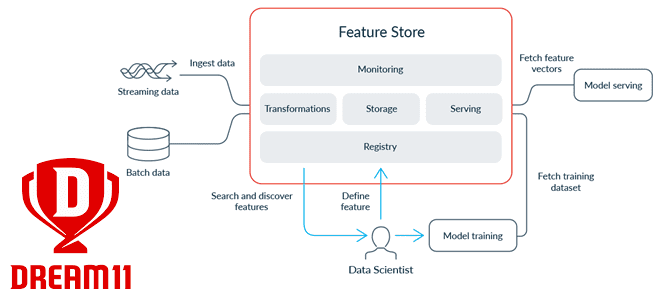
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...
Зачем нужен мониторинг ML-систем в production, чем он отличается от простого отслеживания метрик ПО и при чем здесь MLOps. Как настроить телеметрию ML-приложений в New Relic: 5 простых шагов для специалистов по Machine Learning и дата-инженеров. Зачем нужен мониторинг ML-систем и при чем здесь MLOps В реальных системах машинного обучения...

В рамках практического обучения аналитиков данных и специалистов по Data Science реальным задачам современных бизнес-приложений, сегодня разберем актуальную и острую для многих стран тему по промышленному использованию природных ресурсов в современных непростых условиях. Строим граф европейской газотранспортной системы в Neo4j. Создание графа европейской газотранспортной системы в Neo4j Российский природный газ...
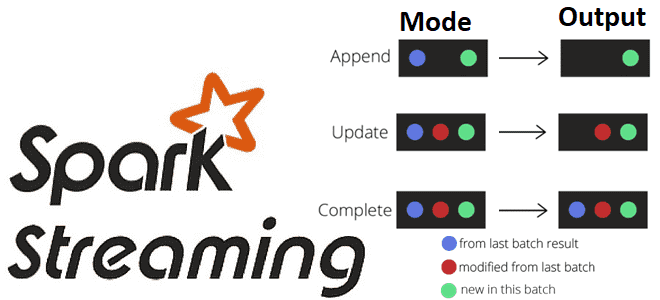
Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений. Что такое режимы вывода в Apache Spark Structured Streaming Apache Spark...
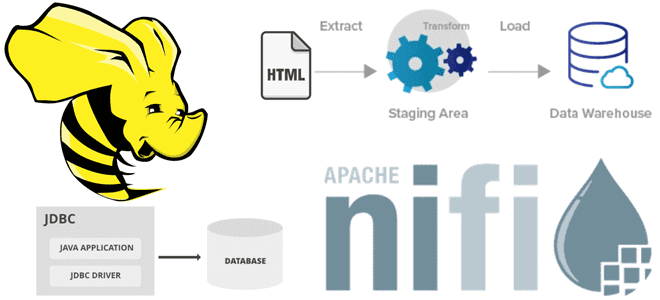
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени. Постановка задачи: ETL-процесс веб-скрейпинга В реальной жизни задача считать данные с веб-сайта для последующей...
Сегодня рассмотрим, что такое процессор ExecuteScript в Apache NiFi, как с его помощью реализовать собственную бизнес-логику обработки потоков данных на мульти-парадигмальном языке программирования TypeScript и чем это будет лучше кода на JavaScript. Краткий ликбез для дата-инженеров. Процессор ExecuteScript в Apache NiFi Напомним, за обработку потоков данных в Apache NiFi отвечают...
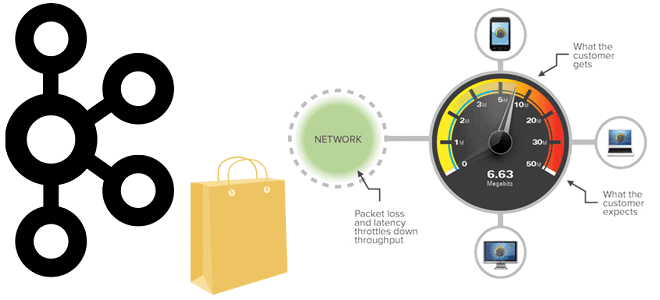
Пропускная способность информационной системы на базе Apache Kafka говорит о том, сколько данных могут быть обработаны за определенный период времени. Несмотря на потоковую передачу событий, здесь работает классический закон обратной зависимости скорости обработки данных от их объема. Разбираемся, как найти баланс между производительностью и задержкой. Еще раз о пропускной способности...

В продолжение недавней статьи для дата-инженеров по эффективной работе с Apache AirFlow, сегодня разберем еще несколько рекомендаций от компании Astronomer, которая продвигает и коммерциализирует этот ETL-оркестратор. Чем полезна микрооркестрация с несколькими средами AirFlow, как обеспечить повторное использование и воспроизводимость, зачем нужна интеграция с инструментами и процессами CI/CD. Микрооркестрация с множеством...