
Для обучения дата-инженеров и аналитиков данных, сегодня рассмотрим приемы оптимизации SQL-запросов в Apache Hive, выполняемых движком Tez. Каким образом Tez рассчитывает оптимальное количество редукторов, зачем включать индексацию фильтров, как статистика таблицы помогает улучшить план выполнения запросов и что за конфигурации нужно менять. 3 движка выполнения запросов в Apache Hive Напомним,...

10 июня 2022 года вышел свежий релиз популярной MPP-СУБД. Разбираемся с улучшениями функциональных возможностей и решенными проблемами в Greenplum версии 6.21.0. Самое важное для администратора кластера и дата-инженера. 4 новых модуля свежего релиза В Greenplum 6.21.0 теперь поддерживается команда SET TRANSACTION SNAPSHOT, которая устанавливает характеристики текущей транзакции, не влияя на...
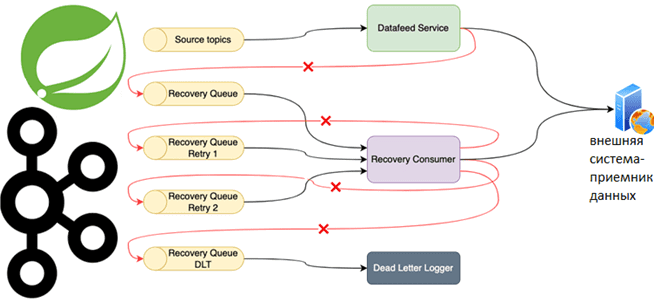
Специально для обучения разработчиков распределенных приложений и дата-инженеров, рассмотрим практический пример использования возможностей фреймворка Spring для управления повторными попытками отправки сообщений потребителям из топика Apache Kafka. Повторные попытки отправки сообщений и Spring для Apache Kafka Довольно часто Kafka-приложения требуют высокой надежности обработки сообщений. Например, в финтех- или медтех-проектах, а также...

Сегодня рассмотрим 2 основные категории технологий обработки данных: пакетную и потоковую. Что общего между batch и stream processing, где они применяются, какими технологиями поддерживаются, можно ли их использовать вместе и как это сделать: ликбез по архитектуре больших данных. Потоковая и пакетная обработка: краткий обзор с примерами Обработки данных в режиме...

15 июня 2022 года вышел новый выпуск Apache NiFi. Разбираем, что нового и полезного в релизе 1.16.3: исправленные ошибки, а также улучшения, важные для дата-инженера и администратора кластера Apache NiFi. 7 исправленных ошибок в релизе 1.16.3 Apache NiFi – один из самых популярных и востребованных инструментов современного дата-инженера. Эта платформа...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое связность в графе, зачем вычислять компоненты связности и как это сделать для ориентированных графов. Продемонстрируем все вычисления с помощью методов Python-библиотеки Networkx в Google Colab. Основы теории графов и применения Networkx в Google...
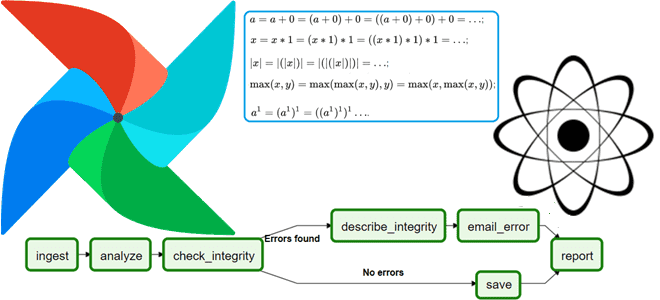
В этой статье для обучения дата-инженеров рассмотрим практическое применение 2-х важных принципов обработки данных: атомарность и идемпотентность задач в Apache Airflow. Читайте далее, как применить их к своим ETL-конвейерам, чтобы получить корректные и согласованные результаты. Все или ничего: атомарность задач Будучи популярным инструментом дата-инженерии, Apache Airflow снижает порог входа в...

Что такое SparkListener, какие встроенные слушатели бывают в Apache Spark, как написать собственный перехватчик событий и зачем это нужно разработчику распределенного приложения. Также рассмотрим, как реализовать свой слушатель для приложения на PySpark и зачем включать уровень логирования INFO для SparkContext. Что такое слушатель Spark Apache Spark позволяет быстро обрабатывать большие...

В свежем релизе Apache Kafka 3.2.0, который вышел 17 мая 2022 года, о чем мы писали здесь, есть много интересных улучшений для повышения устойчивости потоковых приложений. Почему важна новая фича назначения резервных задач с учетом стоек и как разработчик с дата-инженером могут использовать в помощь администратору кластера: разбор rack awareness...
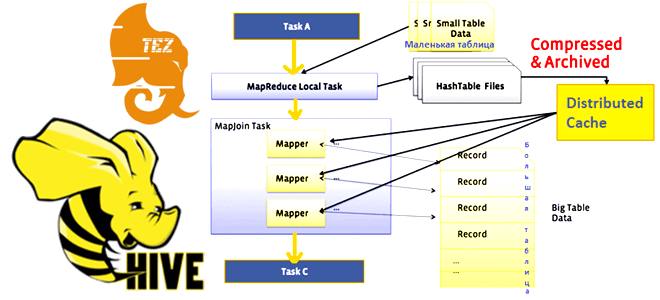
В этой статье для обучения дата-инженеров, аналитиков данных и разработчиков распределенных приложений рассмотрим один из методов оптимизации SQL-запросов в Apache Hive. Что такое оператор MapJoin, в каких условиях и как он работает, чем выгоден для HiveQL-запросов и почему при его выполнении с движком Tez может возникнуть нехватка памяти. Что такое...

Недавно мы писали про главные новинки свежего релиза Apache Flink 1.15, особенно важные с точки зрения обучения разработчиков распределенных приложений и дата-инженеров. Сегодня рассмотрим подробнее, зачем в этом выпуске введены дополнительные режимы восстановления потоковых stateful-заданий из моментальных снимков, когда и какой режим использовать, а также как выбрать формат точки сохранения...

Сколько ядер ЦП выделить на каждый исполнитель и каково оптимальное количество памяти для Spark-приложения при статическом и динамическом выделении ресурсов. Важные вопросы эффективной утилизации кластера, с которыми сталкивается каждый дата-инженер и разработчик распределенных программ. Запуск распределенного приложения через spark-submit Повысить эффективность работы приложения Apache Spark можно не только через оптимизацию...

Мы уже писали о преимуществах развертывания Apache NiFi на Kubernetes, а также сложностях практической реализации этого процесса. Сегодня поговорим о контейнеризации реестра NiFi с использованием Helm-диаграмм, а также совмещения с Apache Ranger и Kerberos. 7 главных трудностей развертывания Apache NiFi на Kubernetes Apache NiFi активно используется дата-инженерами для организации потоковых...
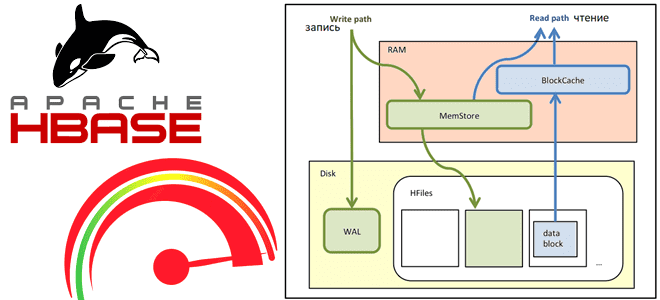
Сегодня рассмотрим, как выполняются операции чтения и записи в Apache HBase, а также с помощью каких приемов можно их ускорить. Как рассчитать оптимальное количество регионов в таблице, зачем отключать версионирование, почему размер ключа строки должен быть небольшим и еще 7 полезных лайфхаков для администратора HBase-кластера. Оптимизация записи данных в Apache...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим особенности обработки пакетных транзакций в популярной графовой СУБД Neo4j . Когда вместо простых запросов встроенного SQL-подобного языка Cypher лучше использовать процедуры библиотеки APOC, чтобы избежать проблем с памятью или остановки обновлений. OOM, большие графы и пакетные транзакции в Neo4j...

Недавно мы писали про Apache AirFlow 2.3.0 от 30 апреля 2022 года. Сегодня более подробно разберем одну из главных новинок этого релиза – динамическое сопоставление задач. Что это такое, как работает и зачем нужно дата-инженеру. Что такое динамическое сопоставление задач в ETL-конвейере Напомним, динамическое сопоставление задач (Dynamic Task Mapping) считается...

17 мая 2022 года вышел очередной релиз главной платформы потоковой передачи событий. Смотрим самые важные обновления свежей Apache Kafka 3.2.0 с точки зрения разработчика распределенных приложений, дата-инженера и администратора кластера. ТОП-5 новинок свежей версии Apache Kafka для администратора кластера Apache Kafka 3.2.0 включает 2 новые фичи, 36 улучшений и 65...

Как писать UDF-функции Greenplum на Python: краткий обзор расширения PL/Python для дата-инженера и разработчика распределенных приложений. Как его установить, настроить и использовать: сопоставления типов данных, SQL-запросы, модули и функции. Поддержка Python в MPP-СУБД Поскольку освоить Python намного проще других языков программирования, например, Java или C#, неудивительно, что он сегодня очень...

Что такое Tungsten, зачем он нужен в Apache Spark и как этот проект устраняет узкие места вычислительного движка, чтобы повысить его производительность и эффективность утилизации ресурсов за счет приближения JVM к bare metal. Рассматриваем самые важные для разработчика распределенных приложений особенности и разбираемся, при чем здесь вольфрам и почему с...
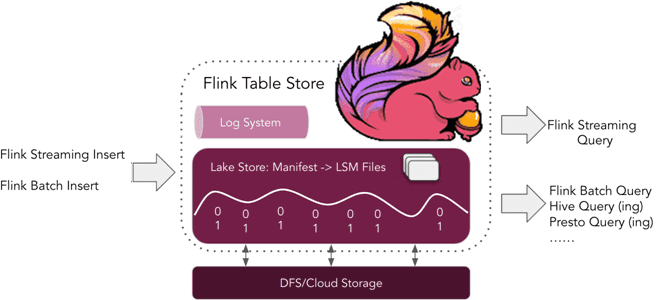
Что такое табличное хранилище Apache Flink, зачем это нужно и почему оно пока не рекомендуется для применения в реальных проектах. Краткий обзор Apache Flink Table Store 0.1.0 для дата-инженеров и разработчиков распределенных приложений. Что такое Flink Table Store и зачем это нужно Уже более полугода, с релиза 1.14, выпущенного в...