Недавно мы рассказывали про стратегии обработки ошибок в потоковых конвейерах данных на Apache NiFi. В продолжении этой темы, сегодня более детально разберем, с какими исключениями может столкнуться дата-инженер, о чем они говорят и как их обойти. Виды исключений Apache NiFi При разработке собственного процессора может возникнуть несколько различных неожиданных ситуаций....
Чтобы добавить в наши курсы для дата-инженеров и специалистов по Machine Learning еще больше практических примеров, сегодня рассмотрим, как построить ETL-конвейер для преобразования речи в текст с использованием Apache Kafka, Airflow и Spark. А также познакомимся с популярными фреймворками и готовыми сервисами распознавания речи. ETL-конвейер распознавания речи: используемые технологии Предположим,...

Сегодня в рамках обучения дата-инженеров разберем, как организовать логическое ветвление рабочего процесса в Apache AirFlow с помощью операторов. Какие операторы позволяют организовать условную логику в DAG, чем BranchPythonOperator отличается от ShortCircuitOperator, как запустить задачу в зависимости от времени и/или дня недели, а также результата выполнения SQL-запроса. Условная логика в DAG:...

Сегодня рассмотрим, с какими нетиповыми ошибками может столкнуться дата-инженер при работе с Apache Flink, а также как решить эти проблемы. Где и что править, когда сервер BLOB-объектов завис из-за слишком большого количества подключений, почему не хватает памяти при развертывании Flink-приложений в кластере Kubernetes и как ускорить инициализацию заданий. Особенности работы...
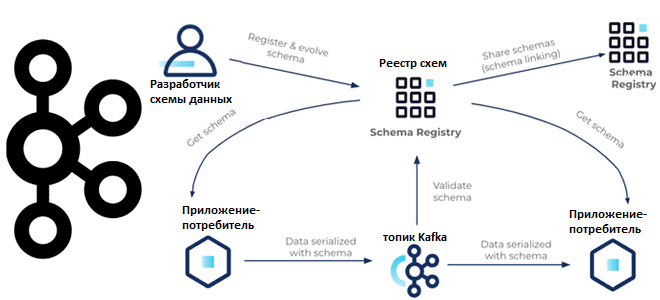
С какими проблемами качества данных сталкивается дата-инженер при работе с Apache Kafka и как реестр схем поможет их решить. Чем формат сериализации Apache AVRO отличается от JSON и Protobuf, как использовать Schema Registry и обеспечить совместимость данных: краткое пошаговое руководство для дата-инженера. Качество данных и реестр схем Apache Kafka Низкое...

В этой статье для обучения дата-инженеров и архитекторов распределенных систем рассмотрим, что такое наблюдаемость, как ее измерить и при чем здесь стандарт OpenTelemetry. А в качестве примера разберем, как французский маркетплейс Cdiscount управляет почти 1000 микросервисов в кластере Kubernetes с Apache Kafka, Jaeger, Elasticsearch и OpenTelemetry. Наблюдаемость распределенной системы: стандарт...

Сегодня разберемся, когда для Data Science-проектов вместо Apache Spark, самого популярного вычислительного движка аналитики больших данных, стоить выбрать Dask – легковесную Python-библиотеку для параллельных вычислений. И, наоборот, в каких случаях инженер данных и Data Scientist получают преимущества, выбирая Spark. Что такое Dask и зачем он нужен Data Scientist’у Прежде чем...

В апреле 2022 года вышел очередной минорный релиз Apache Hive, который работает с Hadoop версии 3. Рассмотрим основные улучшения и исправленные ошибки этого обновления, которые пригодятся дата-инженеру и разработчику распределенных приложений аналитики больших данных. Исправленные ошибки В апрельском выпуске популярного NoSQL-хранилища Apache Hive, которое реализует возможность обращения к данным в...

В этой статье для дата-инженеров рассмотрим новую полезную фичу июньского выпуска Greenplum и обновления интеграционного фреймворка PXF, который обеспечивает интеграцию этой MPP-СУБД с внешними источниками и приемниками данных. Читайте далее, как PXF поддерживает запись данных в формате AVRO в Hadoop HDFS и хранилища объектов, а также чтение логических типов этого...
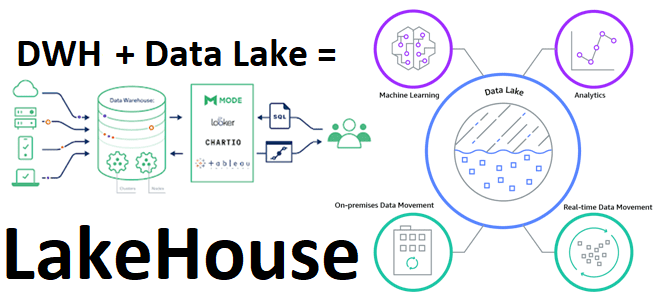
В рамках обучения дата-инженеров и архитекторов корпоративных платформ и приложений аналитики больших данных, сегодня рассмотрим, что такое LakeHouse. Как эта новая гибридная архитектура управления данными объединяет 2 разнонаправленные парадигмы хранения информации, а также чего от нее ожидают бизнес-пользователи, дата-инженеры, аналитики и ML- специалисты. Историческая справка: от DWH к Data Lake...

В этой статье для обучения дата-инженеров рассмотрим, почему в потоковых конвейерах обработки данных на базе Apache NiFi случаются ошибки, и какие популярные стратегии и инструменты помогут идентифицировать эти проблемы, а также решить их. Проблемы конвейеров обработки данных на Apache NiFi Конвейеры данных помогают консолидировать информацию из разных источников, чтобы получить...
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...
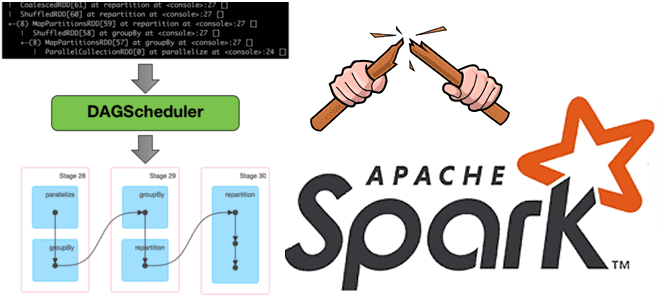
Недавно мы говорили про трудности наблюдаемости данных вообще и возможности мониторинга их происхождения в Apache Spark. Сегодня рассмотрим, зачем дата-инженеру прерывать DAG lineage в Spark-приложениях и как это сделать. Что такое DAG lineage и зачем его прерывать? Напомним, Apache Spark использует концепция DAG для выполнения распределенных вычислений. Направленный ациклический граф...

Сегодня рассмотрим пример программы лояльности турецкого интернет-магазина Trendyol, где Apache Kafka и документо-ориентированная NoSQL-СУБД Couchbase используются для генерации купонов на скидки. Почему при большом объеме данных случаются проблемы тайм-аутов в Couchbase, как их решить и при чем здесь коннекторы к Apache Kafka. Архитектура системы управления купонами Trendyol – это популярный...

16 июня 2022 года вышла новая версия Apache Spark – 3.3.0. Разбираем главные фичи этого минорного релиза, особенно важные для дата-инженера и разработчика распределенных приложений: от расширения поддержки ANSI SQL до профилирования UDF на Python. Главные изменения Apache Spark 3.3.0 Apache Spark 3.3.0 — это четвертый релиз линейки 3.x, в...
Недавно мы говорили про непрерывный мониторинг Flink-приложений и подробно рассмотрели метрики состояния и пропускной способности. В продолжение этой важной для разработчиков и дата-инженеров темы, сегодня рассмотрим, как идентифицировать временную задержку обработки данных. Пользовательские метрики задержки в потоковых приложениях Для потоковых приложений, которые обрабатывают события в режиме, близком к реальному времени,...
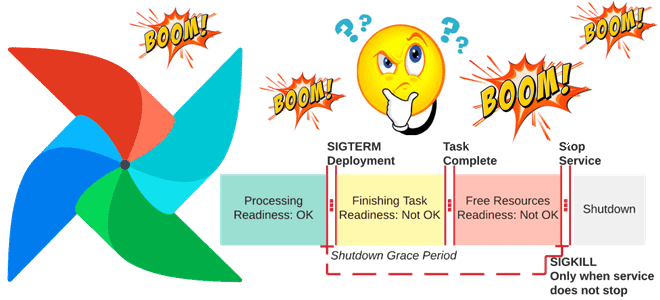
Каждый дата-инженер, который работает с Apache Airflow, сталкивался с сигналом SIGTERM, который отправляется задачам и приводит к сбою DAG. Сегодня рассмотрим, почему случается исключение airflow.exceptions.AirflowException, которое генерирует этот сигнал, и как его избежать. Тайм-аут выполнения DAG Одна из причин, по которой задача получает сигнал SIGTERM, связана с небольшим значением параметра...
Вчера мы рассказывали, почему важна наблюдаемость данных какие платформы помогают комплексно обеспечить все ее аспекты. В продолжение этой темы сегодня заглянем под капот происхождения данных в Apache Spark с помощью агента Spline и других способов. Трудности data lineage в Apache Spark Когда конвейер данных выходит из строя, дата-инженеру нужно скорее...
Сегодня рассмотрим, почему наблюдаемость данных так важная для проектов Big Data, какие компоненты обеспечивают ценную информацию о качестве и надежности данных, чем это похоже на DataOps, а также как эти идеи реализовать на практике с использованием популярных инструментов современной дата-инженерии. Почему важна наблюдаемость данных Цифровизация предполагает управление на основе качественных...
Специально для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink, рассмотрим наиболее важные системные показатели, а также инструменты мониторинга этих метрик. Мониторинг Flink-приложений: особенности и метрики В общем случае мониторинг приложений гарантирует, что ПО обрабатывает данные и выполняет запрошенные действия ожидаемым образом. Непрерывное отслеживание...