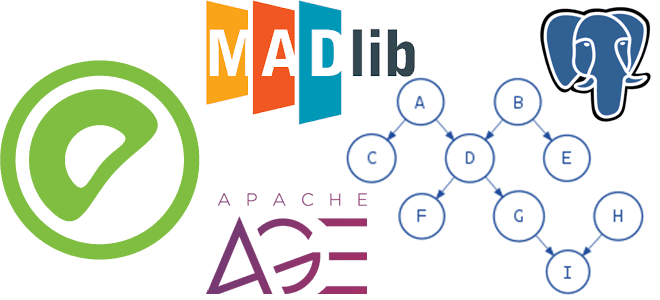
Инструменты графовых алгоритмов для аналитики больших данных в PostgreSQL и Greenplum: обзор расширений и возможностей. Знакомимся с Apache AGE и MADlib. Графовая аналитика в PostgreSQL Реляционные СУБД отлично подходят для хранения данных с четкой структурой практически в любой предметной области и предлагают широкие возможности аналитической обработки таких данных. Но иногда реляционная...
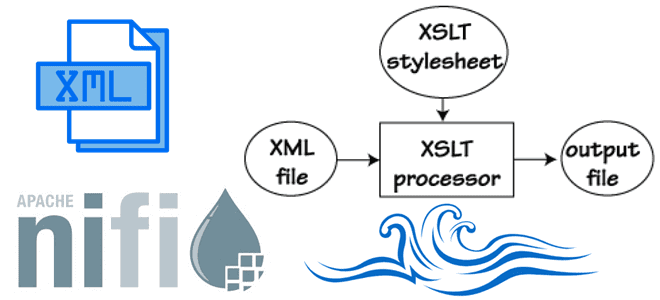
Недавно мы писали про JSON-преобразования в Apache NiFi. Продолжая тему работы с данными различного формата, сегодня рассмотрим, как штатными средствами этого потокового ETL-инструмента преобразовать данные, поступающие в виде XML-документов. Что такое XSLT Хотя сегодня XML-формат нельзя назвать самым модным, он до сих пор активно используется во многих информационных системах, которые...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями. Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД NoSQL-решения и Apache Hadoop реализуют стратегию «схема при...

Сегодня на примере Apache HBase и Redis разберемся со сходствами и отличиями NoSQL-СУБД типа «семейство колонок» и «ключ-значение». Что между ними общего и что выбирать для практического использования в зависимости от сценариев применения. 3 типа NoSQL-хранилищ данных Apache HBase и Redis являются довольно популярными базами данных среди NoSQL-решений. Однако, они...

Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...
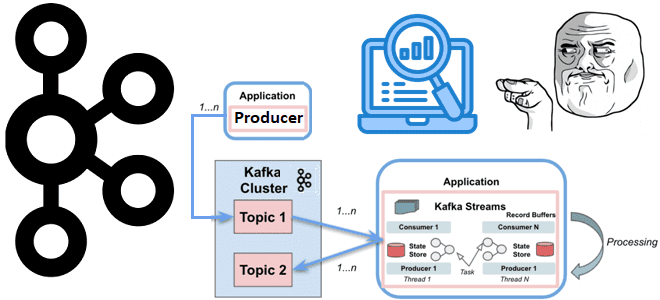
Как использовать один и тот же топик Kafka для источника и назначения данных, обеспечивая высокую пропускную способность и низкую задержку приложений Kafka Streams. А также рассмотрим, какие встроенные метрики приложений есть у Kafka Streams, как добавить свои собственные и с помощью каких инструментов их отслеживать в реальном времени. Топики и...

Мы уже делали краткий обзор некоторых исполнителей задач Apache AirFlow. Сегодня рассмотрим более подробно механизмы запуска удаленных задач и разберемся, чем Celery Executor отличается от CeleryKubernetes Executor и как они работают. Виды и назначение исполнителей Apache AirFlow Напомним, Apache AirFlow состоит из нескольких компонентов: Веб-сервер, предоставляющий GUI для настройки DAG...
Зачем нужна Python-библиотека Evidently, и как она помогает специалистам по Data Science выявлять дрейф данных моделей Machine Learning в производственной среде. Знакомимся с еще одним MLOps-инструментом. Что такое дрейф данных, чем это опасно и как его обнаружить В отличие от многих других информационных систем, проекты машинного обучения очень сильно зависят...

Что общего у Neo4j с TigerGraph и чем они отличаются: разбираемся с популярными графовыми СУБД и их возможностями для аналитики больших данных в рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях. Сравнение Neo4j с TigerGraph Подробно об архитектуре, принципах работы, функциональных возможностях и вариантах использования TigerGraph мы писали...

Сегодня познакомимся с расширением PostGIS, которое позволяет PostgreSQL и Greenplum обрабатывать пространственные данные в геолокационных и логистических задачах. Как оно устроено и каковы ограничения его практического использования в MPP-СУБД. Что такое PostGIS и как это работает Как и PostgreSQL, Greenplum поддерживает геометрические типы данных, с помощью которых можно строить статичные...
В этой статье для обучения дата-инженеров поговорим про тестирование потоковых конвейеров обработки данных в Apache NiFi. Утилиты, классы и сервисы для проверки правильной работы процессоров, контроллеров и потоков. Модульное тестирование процессоров Apache NiFi Обычно тестирование компонентов крупной инфраструктуры не самая простая задача. В Apache NiFi проверка корректности обработки потоков данных...

Недавно мы писали про использование AirFlow для оркестрации dbt-конвейеров. Сегодня познакомимся с адаптером dbt-flink, который позволяет запускать SQL-конвейеры в проекте dbt на Apache Flink. Зачем нужен адаптер dbt к Apache Flink и как он работает В аналитике данных огромную роль играет эффективный, стабильный и надежный ETL-процесс, реализовать который можно с...

Зачем биотехнологической платформе Polly от Elucidata понадобился API SQL-запросов в облачном сервисе Elasticsearch и как дата-инженеры реализовали его, развернув Delta Lake с AWS Atnena и S3. Что не так с SQL-запросами в облачном Elasticsearch на AWS Ежедневно биотехнологическая платформа Polly от Elucidata обрабатывает гигабайты биомолекулярных данных для биологов по всему...

Метод ближайших соседей активно используется в машинном обучении для решения задач классификации в различных бизнес-приложениях. Познакомимся поближе с этим алгоритмом Machine Learning, а также разберем, почему NoSQL-хранилище Apache HBase отлично подходит для работы с ним. Что такое метод ближайших соседей: ликбез по Machine Learning В проектах Machine Learning и приложениях...

Чтобы сделать наши курсы для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня мы расскажем про новый бесплатный сервис от маркетплейса Joom для поиска проблем с производительностью Spark-заданий. Разбираемся, как он работает и чем полезен дата-инженеру. 4 главных проблемы Spark-приложений, их последствия и трудности обнаружения Если количество Spark-приложений невелико,...
Для параллельной обработки сообщений из своих топиков Kafka использует механизм группы приложений-потребителей, о чем мы писали здесь. Читайте далее, что происходит при изменении состава группы потребителей, чем опасна частая перебалансировка и как ее избежать. Что такое перебалансировка потребителей и почему она случается? Выполняя роль интеграционного звена между приложениями-продюсерами и приложениями-потребителями...

Что такое dbt, чем полезен этот инструмент для анализа и инженерии данных, зачем переносить в него бизнес-логику обработки данных и представлять эти задачи в DAG-конвейере Apache AirFlow. Python и SQL для анализа данных и дата-инженерии: versus или вместе? Распил крупных монолитных систем на множество автономных взаимодействующих друг с другом приложений...

Как MLOps-инженеры платформы онлайн-курсов Udemy ускорили цикл разработки и внедрения проектов машинного обучения, используя возможности Amazon SageMaker для создания и отладки Spark-приложений в удаленном облачном кластере. MLOps на AWS Чтобы воспользоваться преимуществами бесшовной интеграции процессов разработки и развертывания машинного обучения согласно концепции MLOps, совсем не обязательно выстраивать собственную платформу из...

Сегодня в рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях, решим классическую задачу логистики в графовой базе данных Neo4j без использования методов ее специальной библиотеки Graph Data Science, а средствами Cypher-запросов. Постановка задачи: критерии оценки для поиска кратчайшего пути Поиск кратчайшего пути – это классическая задача на графах,...