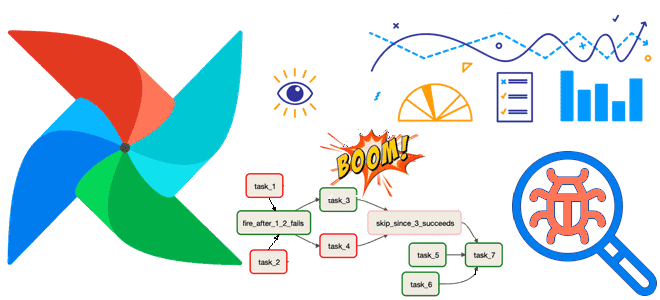
Проблемы отладки конвейеров обработки данных в Apache AirFlow и способы их решения средствами самого фреймворка. Как дата-инженеру настроить мониторинг системных событий на уровне DAG или отдельной задачи: операторы, кластерные политики и обратные вызовы. Отладка конвейеров обработки данных в Apache AirFlow: проблемы и возможности Практикующий дата-инженер знает, как бывает сложно найти...
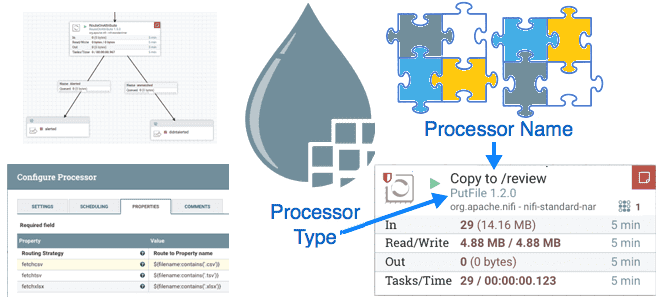
Вчера мы писали про паттерны проектирования процессоров Apache NiFi, ориентированные на данные. Сегодня рассмотрим шаблоны с фокусом на маршрутизацию потоковых файлов, которые можно применять при разработке пользовательского процессора. Маршрутизация на основе содержимого (Route Based on Content) Процессор этого типа направляет входящий FlowFile на основе его содержимого в одно или несколько...

Что пригодится дата-инженеру при разработке пользовательского процессора Apache NiFi: паттерны приема и выдачи данных, а также обогащение содержимого потокового файла. Знакомимся с принципами работы шаблонов проектирования процессоров NiFi, ориентированных на данные. Прием данных (Data Ingress) Apache NiFi предоставляет более 300 готовых процессоров – обработчиков, которые выполняют определенные действия с потоковыми...
Что не так с механизмом контрольных точек в Apache Flink, и как журнал изменений состояния справляется с ростом сквозной задержки в потоковой обработке данных средствами этого фреймворка. Проблемы контрольных точек в Apache Flink Одной из наиболее важных характеристик систем потоковой обработки данных является сквозная задержка, которая в Apache Flink зависит...
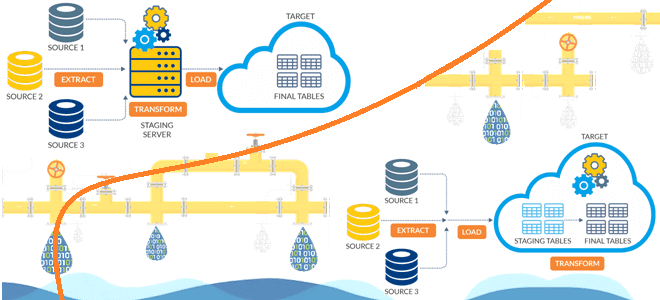
Чем динамичный ELT-подход лучше традиционного ETL, в чем разница между этими архитектурами конвейеров данных и зачем нужно профилирование данных при построении высокоэффективных дата-пайплайнов. Чем ETL отличается от ELT: ликбез для дата-инженера Аналитика больших данных невозможна без ETL/ELT-процессов, т.е. извлечения данных из разных источников (базы данных, файлы, API, прикладные системы), их...
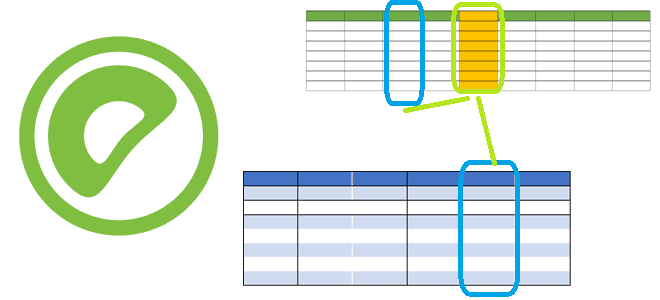
Зачем в Greenplum 7 добавлены вычисляемые (генерируемые) столбцы, как их использовать, и чем они опасны: достоинства, недостатки и ограничения этой возможности. Что такое генерируемые столбцы Поскольку Greenplum основана на PostgreSQL, эта MPP-СУБД имеет множество похожих функций. В частности, в 7-ю версию Greenplum добавлена возможность сохранения вычисляемых (генерируемых) столбцов, которые вычисляются...

Сегодня познакомимся с сервером истории Apache Spark: зачем он нужен, как работает и при чем здесь слушатели событий. Отладка и мониторинг распределенных приложений для дата-инженера в веб-GUI. Что такое сервер истории Apache Spark Каждый раз при запуске Spark-приложения его контекст SparkContext запускает веб-интерфейс по умолчанию на порту 4040. Если несколько...
Мы уже рассказывали про задачи-зомби в Apache AirFlow и способы их устранения. Продолжая тему управления распределенными процессами, сегодня поговорим про задачи, зависшие в очереди и универсальное решение для борьбы с ними, которое будет реализовано в выпуске Apache AirFlow 2.6.0, о других новинках которого читайте здесь. Жизненный цикл задачи в Apache...
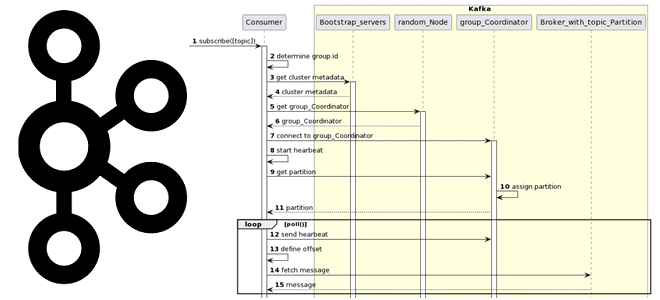
Вчера мы разбирали работу приложения-продюсера и строили UML-диаграмму последовательности. Сегодня рассмотрим, какие системные вызовы происходят при потреблении сообщений из Apache Kafka, при чем здесь группы потребителей и фиксация смещений. Как работает потребитель Kafka Аналогично разработке приложения-продюсера, при написании кода потребителя, который считывает данные из топика Apache Kafka, используются методы специальных...
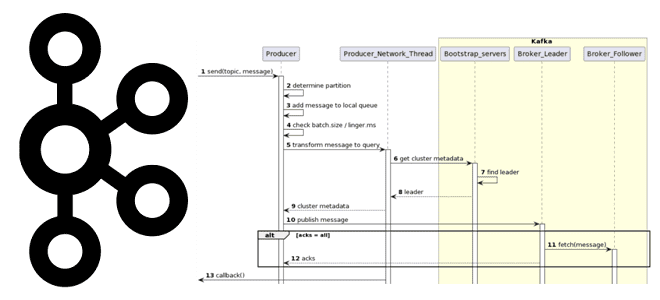
Как на самом деле работает приложение-продюсер Apache Kafka: разбираемся с конфигурациями и составляем UML-диаграмму последовательности системных вызовов при публикации сообщений в топик. Как работает продюсер Kafka Когда разработчик пишет приложение-продюсер, которое публикует сообщение в топик Apache Kafka, он использует методы специальных библиотек, таких как kafka-python и пр. Достаточно только создать...

Как использовать DataStream API в Apache Flink: пишем потребителя из Kafka и запускаем скрипт в Google Colab. StreamExecutionEnvironment и методы коллекций потока данных в PyFlink. DataStream API в Apache Flink: PyFlink в Google Colab для работы с Kafka Apache Flink предоставляет множество возможностей разработчикам на Scala и Java, а также...
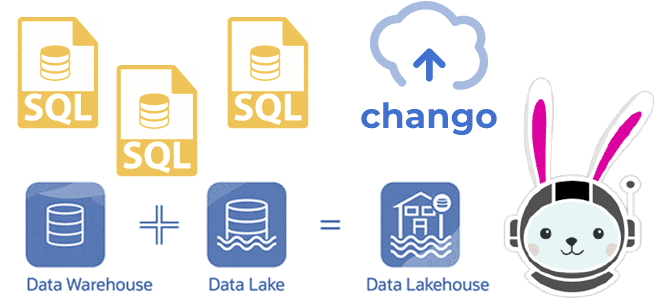
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...
Проблемы анализа данных временных рядов и способы их решения: какие статистические методы и алгоритмы глубокого обучения лучше подходят для прогнозирования. Особенности прогнозирования временных рядов Напомним, временным рядом считается набор данных, каждая точка которого привязана ко времени (час, минуты, дни, месяцы, годы и прочие периоды). Эти данные имеют динамический характер и...

Где создать граф знаний и попробовать графовые алгоритмы для решения бизнес-задач: смотрим варианты запуска графовой СУБД на примере Neo4j. 4 варианта запуска Neo4j Neo4j является ярким представителем нереляционных СУБД и относится к категории графовых баз. Она поддерживает специализированные алгоритмы работы с графами, включая поиск путей, выявление сообществ, анализ связей и...
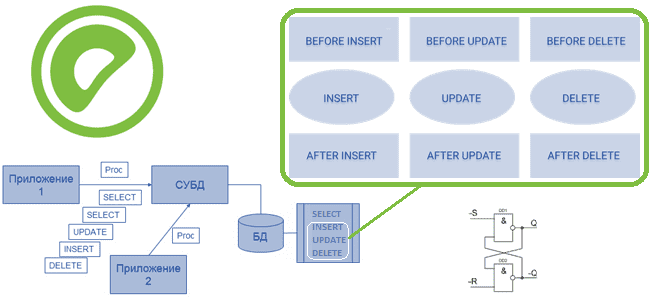
Где и как используются триггеры, чем они отличаются от хранимых процедур, как это реализуется в Greenplum. Создание, изменение и удаление триггеров и ограничения их применения в Greenplum. Что такое хранимые процедуры и триггеры Напомним, хранимые процедуры представляют собой именованные блоки SQL-команд, которые заранее откомпилированы и хранятся на сервере, чтобы ускорить...

Как обеспечить безопасное подключение процессора InvokeHTTP к внешнему API, настроив SSL-службу контекста в Apache NiFi. Краткий ликбез по SSL-соединению и реализации API службы контроллера SSLContextService в Apache NiFi для дата-инженера. Безопасность работы с внешним API с SSL-соединением Apache NiFi включает множество процессоров – обработчиков, которые выполняют определенные действия с потоковыми...

Недавно мы разбирали, как дата-инженеру написать собственный оператор Apache AirFlow и использовать его в DAG. Сегодня посмотрим, каким образом с этой задачей справляется модный ИИ под названием ChatGPT. GPT-генерация пользовательского оператора AirFlow Хотя Apache AirFow предоставляет множество операторов для выполнения самых разных задач, иногда дата-инженеру приходится писать свои собственные Python-классы,...

Как разработчику выбрать подходящий режим развертывания для своего Spark-приложения, достоинства и недостатки клиентского и кластерного режимов, а также особенности запуска под управлением YARN. Архитектура и режимы развертывания Spark-приложения Будучи фреймворком для создания приложений быстрой обработки Big Data, Apache Spark имеет несколько режимов развертывания, которые зависят от варианта запуска Spark-приложения: на...
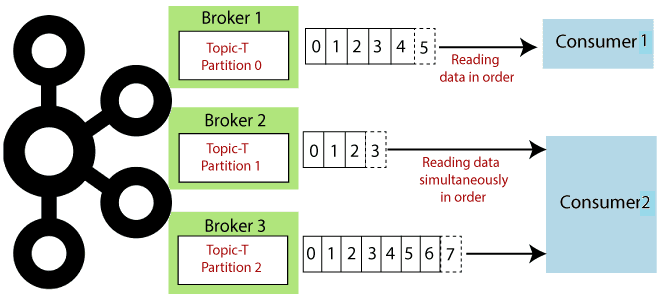
Что общего у Kafka Streams и Consumer API, чем они отличаются и что выбирать для практического использования: краткое руководство для разработчика приложений потоковой обработки событий. Возможности и ограничения Kafka Streams и Consumer API Поскольку Apache Kafka как огромная экосистема со множеством компонентов для потоковой передачи событий, обилие и разнообразие этих...
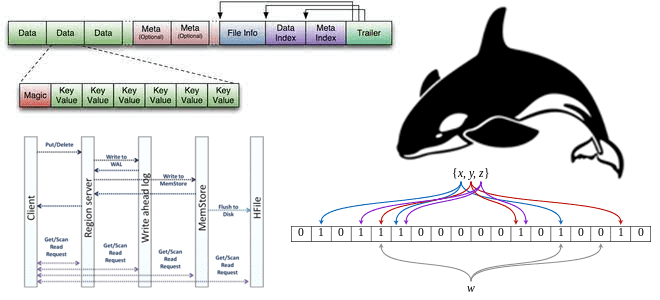
Что такое HFile, как появился этот низкоуровневый файловый формат, каковы его главные принципы работы, как Apache HBase использует его для хранения и быстрой аналитики больших данных, и при чем здесь фильтр Блума. Роль HFile в Apache HBase Apache HBase реализует возможности Google BigTable для Hadoop. Эта NoSQL-СУБД типа «семейство колонок»...