
Мы уже писали про тестирование приложений Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Сегодня рассмотрим, как с помощью тестовых наборов тестировать UDF-функции, использующих состояние и таймеры. Модульное тестирование UDF-функций Flink-приложения с помощью тестовых наборов При работе с Apache Flink разработчики часто сталкиваются с проблемами при...
Как с помощью Apache NiFi запрашивать информацию из баз данных постранично. Разбираемся с возможностями и рисками использования процессоров NiFi для пагинации в SQL-запросах. Пагинация баз данных и процессоры Apache NiFi Apache NiFi позволяет запрашивать из баз данных целые таблицы с помощью разбиения на страницы, т.е. пагинации. Напомним, базы данных хранят...
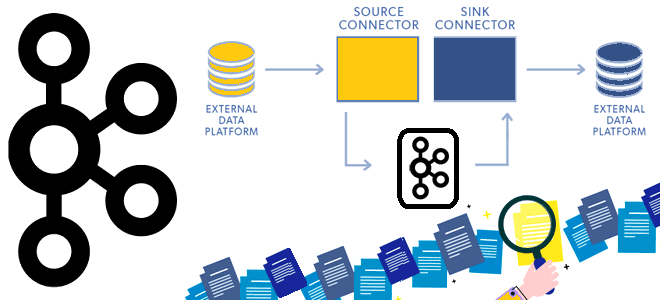
Сегодня рассмотрим принципы работы компонента экосистемы Apache Kafka под названием Connect и разберемся, как он устроен. Программная архитектура коннекторов и способы избежать дубликатов при зависании внешней системы-приемника. Архитектура и принципы работы Kafka Connect Apache Kafka не зря считается платформой потоковой передачи, а не просто брокером сообщений. Вокруг нее выстроена целая...

Как сделать запуск UDF-функций Python или R на узлах сегмента Greenplum более быстрым и безопасным с помощью Docker-контейнеров и расширения PL/Container. Что такое PL/Container и как это использовать в Greenplum Запуск пользовательского кода для базы данных всегда имеет риск нарушения информационной безопасности. Если речь идет о стеке Big Data, ущерб...
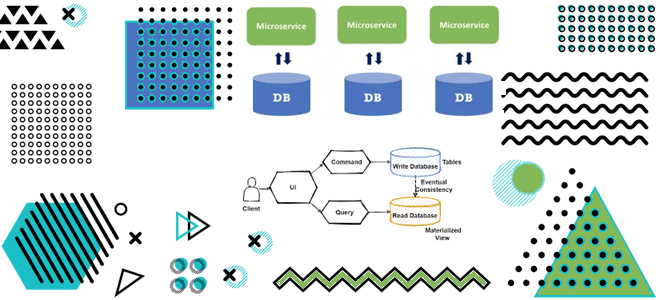
Как материализованные представления в потоковой базе данных с CDC-подходом и шаблоном CQRS позволяют реализовать масштабируемую и высокопроизводительную систему с микросервисной архитектурой для транзакций и аналитики данных в реальном времени. Разбираемся с паттернами проектирования микросервисов на примере интернет-магазина. Что не так с шаблоном композиция API и другие проблемы микросервисной архитектуры в...

Что появилось нового в мажорном релизе самой популярной Python-библиотеки pandas, чем она похожа на Rust-пакет с Python API polars и в чем между ними разница: тестирование производительности и польза для дата-инженера. Главные новинки pandas 2.0 3 апреля 2023 года вышел долгожданный релиз Python-библиотеки pandas, которая для многих дата-инженеров, аналитиков данных...
В этой статье для обучения дата-инженеров рассмотрим типы оповещений в Apache AirFlow и их отслеживание в сервисе мониторинга cron-заданий Healthchecks.io. Оповещения Apache AirFlow: какие они бывают и зачем их отслеживать Apache AirFlow позволяет создавать сложные конвейеры обработки данных, которые могут выполняться по расписанию, по событию или запускаться вручную. Для повышения...
Сегодня вспомним, какие процессоры есть в Apache NiFi для работы с HTTP-запросами, зачем их так много, чем они отличаются и в каких случаях использовать каждый из них. Разница между HandleHttpRequest, HandleHttpResponse, GetHTTP, PostHTTP, InvokeHTTP и ListenHTTP. Мы с Тамарой ходим парой: совместное использование процессоров HandleHttpRequest и HandleHttpResponse На первый взгляд...
Обогащение потока данных информацией из внешнего API без остановки вычислений: 3 способа реализовать это средствами Apache Flink на примере сервиса геолокации. Зачем обогащать потоковые данные через внешний API и как это сделать для Flink-приложения? Иногда необходимо обогатить потоки данных, т.е. дополнить потоковые данные в реальном времени, т.е. на лету, не...
Чтобы разобраться, как на самом деле работают разделы и потребители Apache Kafka, сегодня рассмотрим небольшой демонстрационный пример, иллюстрирующий потребление сообщений. Пишем Python-скрипты публикации и потребления сообщений из разных разделов топика Kafka с занесением данных в несколько вкладок Google-таблицы. Как сообщения распределяются по разделам топика Kafka Напомним, в Apache Kafka раздел...

12 апреля 2023 года вышел очередной релиз Apache Spark. Разбираемся с самыми главными новинками этого выпуска, которые порадуют аналитиков, разработчиков, инженеров данных и специалистов по Data Science. Расширенная поддержка Python, улучшения Spark SQL и Structured Streaming. Обновления Spark SQL и новинки для пользователей Python Apache Spark 3.4.0 — это пятый...
Сегодня решим логистическую задачу поиска кратчайшего пути, создав граф знаний в Neo4j, развернутой в облачной платформе Aura DB и визуализируем найденный путь с помощью Python-библиотеки Networkx. Работа с Neo4j в AuraDB В прошлой статье мы упоминали, что для работы с популярной графовой СУБД Neo4j совсем необязательно устанавливать ее локально. Можно...
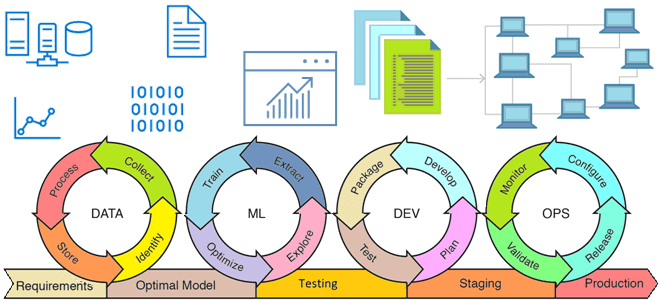
Из каких компонентов состоит архитектура MLOps, что такое инфраструктура как код, как управлять ею с помощью скриптов и почему это нужно на каждом этапе жизненного цикла моделей Machine Learning. Жизненный цикл ML-модели и MLOps MLOps – это набор методов и техник машинного обучения вместе с лучшими практиками разработки, развертывания и...
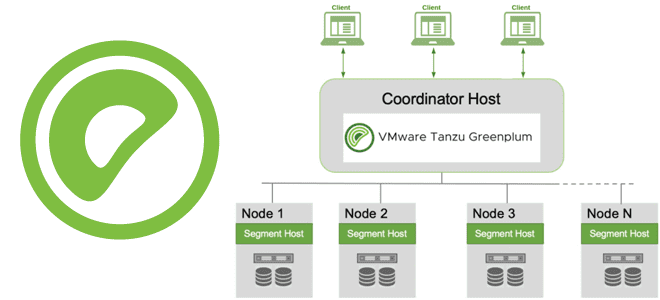
Через какие интерфейсы пользователи и клиентские приложения могут подключиться к базе данных Greenplum, как происходит подключение, какие параметры и конфигурации надо задать при этом, а также почему для этого так важна библиотека libpq. Параметры подключения к Greenplum Пользователи могут подключаться к базе данных Greenplum с помощью клиентской программы, совместимой с...

Как сделать Apache NiFi еще эффективнее, избежав трех самых популярных ошибок дата-инженера. Разбираемся с автоматизацией операций развертывания, скриптовыми процессорами, а также шаблонами и реестром NiFi для развертывания потоков данных. Ошибка №1: ручное развертывание Хотя Apache NiFi имеет мощный пользовательский интерфейс для проектирования конвейеров потоковой обработки данных, его не стоит рассматривать...
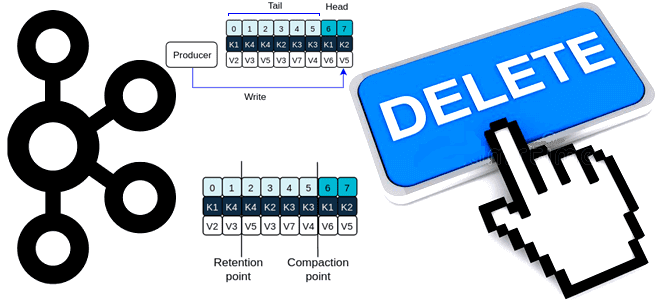
Почему в Apache Kafka нет функций очистки топика и как же все-таки удалить из него все сообщения, если очень нужно, используя конфигурации retention и другие приемы администрирования кластера. Политика очистки и конфигурации retention В отличие от брокеров сообщений, которые после отправки данных приложениям-потребителям, удаляют их из очереди, Apache Kafka хранит...
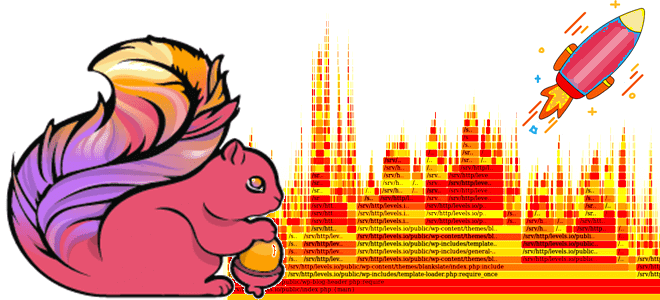
Мы уже писали о важности отслеживания системных метрик приложений Apache Flink и RocksDB, используемой этим фреймворком для хранения состояния stateful-заданий. Сегодня рассмотрим, как отследить потребление ресурсов ЦП средствами встроенной визуализации Flame Graphs. Что такое Flame Graph и зачем это нужно? Помимо мониторинга длительности выполнения задач и заданий, дата-инженерам и разработчикам...
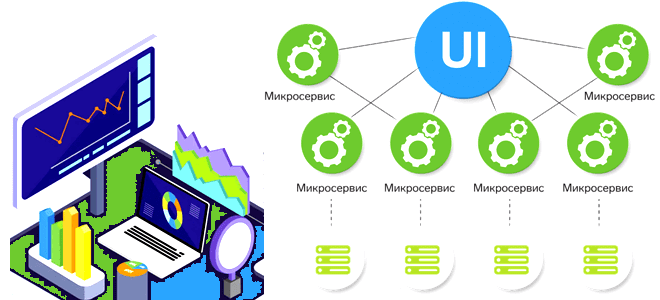
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы. Проблемы микросервисной архитектуры для платформы данных и способы их решения При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая...

Чем тип JSONB отличается от JSON и почему это так важно для хранения и обработки данных гибкой структуры в Greenplum. Примеры SQL-запросов к JSON-данным и особенности синтаксиса JSONPath. Чем JSONB отличается от JSON и почему это так важно? Будучи основанной на PostgreSQL, Greenplum имеет множество аналогичных возможностей, включая поддержку работы...
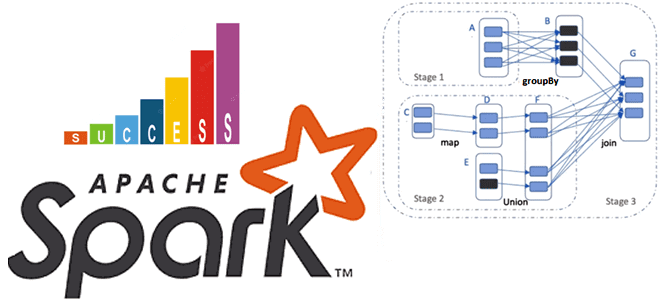
Почему на самом деле нельзя избежать shuffle-операций в Spark SQL, в чем разница перетасовки RDD и датафреймов, а также как сократить негативное влияние перемешивания данных по узлам кластера, настроив конфигурации распределенного приложения. Что такое shuffle-операции в Apache Spark SQL и зачем они нужны Распределенный характер вычислительного движка Apache Spark позволяет...