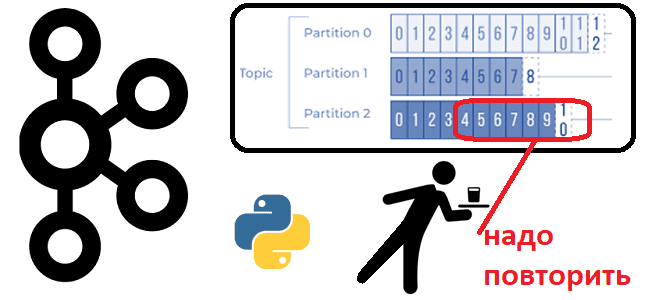
Иногда возникает потребность в повторном чтении данных из Apache Kafka с определенного момента времени. Сегодня рассмотрим, как это сделать, написав простенький Python-скрипт потребления из раздела топика. Публикация данных в Kafka В качестве примера возьмем ранее рассмотренный в этой статье кейс приема потока обращений в интернет-магазин. Обращения могут представлять собой заявки...
Недавно мы писали про устранение зависших в очереди задач в Apache AirFlow 2.6. Сегодня разберемся с другими новинками этого релиза, которые особенно важны для дата-инженера: настраиваемые поля DAG, добавление собственных уведомлений, управление ресурсами, кластеризация исполнителей Kubernetes и еще множество полезных возможностей. Главные новинки и исправления весенних выпусков Apache AirFlow в...

Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok. Проброска туннеля в Google Colab с ngrok для Spark-приложения Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики...

Мы уже писали про механизмы обеспечения высокой доступности в кластере Greenplum. Сегодня рассмотрим, какие инструменты и приемы помогут выявить сбои координатора и сегментов, а также как администратору кластера этой MPP-СУБД восстановить ее работоспособность. Что такое зеркалирование сегментов Greenplum Напомним, кластер Greenplum представляет собой несколько экземпляров популярной объектно-реляционной базы данных (БД)...
В этой статье для дата-инженеров поговорим про шифрование потока данных в Apache NiFi с помощью набора процессоров, поддерживающих спецификацию OpenPGP. Криптографическая защита целостности и конфиденциальности потока данных. Криптографические процессоры Apache NiFi Криптография является одним из наиболее распространенных методов защиты целостности и конфиденциальности данных с помощью шифрования и дешифрования. Сегодня чаще...

Сегодня рассмотрим, как написать и запустить в Google Colab свое Python-приложение считывания данных из топика Kafka с помощью коннектора FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors и почему заставить его работать оказалось не так просто. Использование FlinkKafkaConsumer для доступа к Kafka из Flink приложения Недавно я показывала, как написать PyFlink-скрипт считывания данных из...
Что такое «проблема разделенного мозга» в распределенных системах, почему она возникает, при чем здесь зомби-продюсеры и как с этим бороться. Разбираем на примере Apache Kafka. Проблема разделенного мозга или зомби-процессы в распределенных системах Термин зомби-процесс пришел из области операционных систем, однако, в распределенных системах его интерпретация абсолютно противоположна исходному значению....
Что такое безиндексная смежность и как она снижает сложность алгоритмов обхода графа, позволяя быстро и эффективно запрашивать множество узлов и отношений. Разбираемся с уникальными принципами работы графовых баз данных на примере Neo4j. Архитектура и принципы работы графовых баз данных Несмотря на стремление разработчиков современных СУБД к унификации их решений, первичная...
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions. Разделы и оптимизация распределенных вычислений в Spark-приложениях Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее...
Чем инженерия данных отличается от разработки ПО, как организовать оркестрацию конвейеров обработки данных и внедрить лучшие практики CI/CD. Почему дата-инженерия отличается от разработки ПО При том, что между инженерией данных и разработкой программного обеспечения (ПО) очень много общего, эти ИТ-дисциплины довольно сильно отличаются. Хотя в обоих направлениях используется облачная инфраструктура,...
Что такое код верхнего уровня в Apache AirFlow, почему его следует избегать и как это сделать: шаблонные переменные, динамическое сопоставление задач, Python-функции и библиотеки для кэширования. А также 3 нативных способа создания перекрестных зависимостей между DAG для их запуска: TriggerDagRunOperator, ExternalTaskSensor и SimpleHttpOperator. Что такое код верхнего уровня в Apache...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, какие механизмы обеспечения информационной безопасности поддерживает Apache Spark и как организовать безопасное взаимодействие Spark-приложения с хранилищами данных в экосистеме Hadoop. Безопасная работа Spark-приложений с сервисами Hadoop Многие технологии Big Data изначально оптимизированы для хранения и аналитики больших объемов данных с...
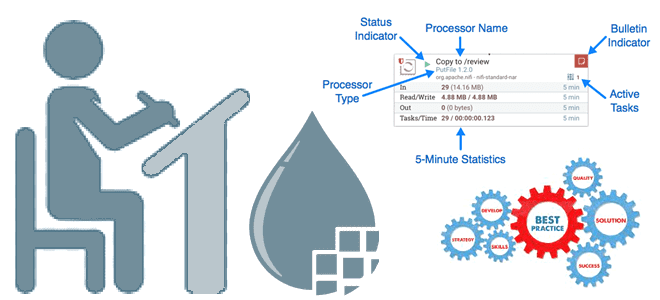
Поскольку Apache NiFi позволяет не только использовать готовые процессоры, но и разработать свой собственный, дата-инженеру полезно знать лучшие практики проектирования таких обработчиков Flow File. Принцип единой ответственности при проектировании процессора Apache NiFi В Apache NiFi есть более 300 готовых процессоров, которые выполняют определенные действия с потоковыми файлами в рамках конвейера...
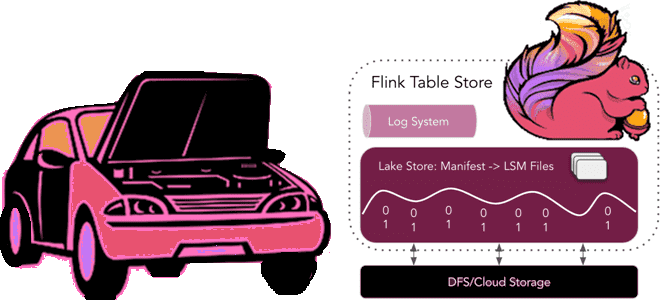
Год назад мы уже писали, как в Apache Flink появились табличные хранилища и зачем они нужны. Сегодня заглянем под капот Flink Table Store, познакомившись со структурой файлов и каталогов. Архитектура и принципы работы Flink Table Store Поскольку Apache Flink объединяет пакетную обработку данных с потоковой, для работы этого универсального stateful-механизма...
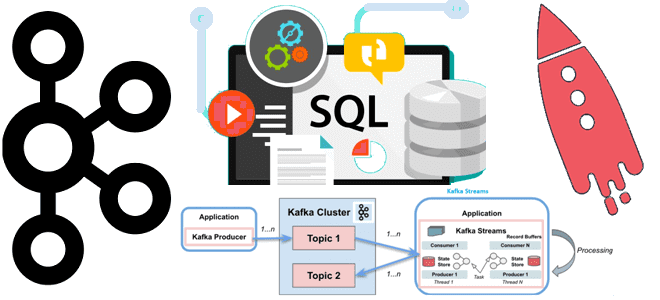
Недавно мы писали, чем Kafka Streams отличается от Consumer API. Сегодня рассмотрим, в чем разница между Kafka Streams и ksqlDB, а также разберем, почему использовать этот компонент экосистемы Apache Kafka не так просто. Как работает ksqlDB: практический пример Apache Kafka является полноценной экосистемой потоковой передачи, вокруг которой существует множество полезных...
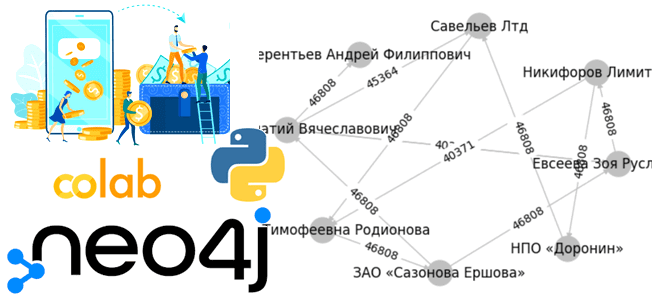
Чтобы показать еще один вариант использования графовой базы данных Neo4j, сегодня реализуем небольшое Python-приложение, которое генерирует граф знаний в облачной платформе Aura DB. Ищем финансовые переводы между компаниями и физическими лицами, считаем общую сумму и визуализируем найденные транзакции с помощью библиотеки Networkx. Python-приложение для работы с Neo4j в AuraDB Как...
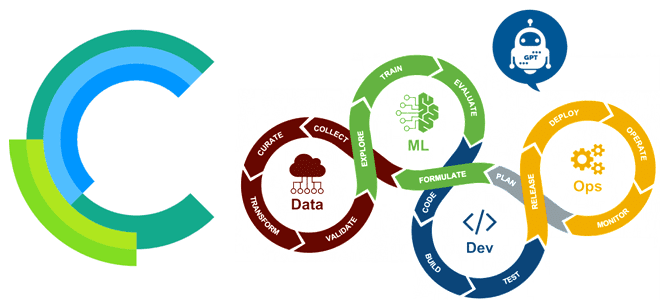
Чтобы сделать наши курсы для специалистов по Data Science и ML-инженеров еще более полезными, сегодня познакомимся с очень мощным инструментом MLOps – open-source платформой ClearML. Что это такое, как работает, насколько упрощает разработку продуктов Machine Learning, а также зачем бизнесу ClearGPT. Что такое ClearML и как это поможет MLOps-инженеру Концепция...
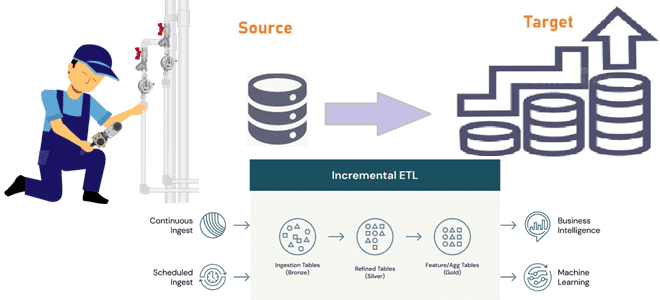
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
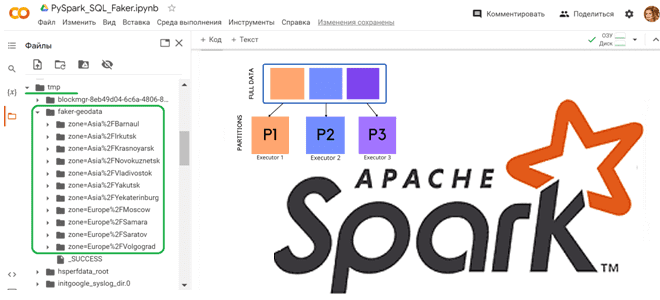
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab. Как работает partitionBy() в Apache Spark Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache...
Сегодня рассмотрим, какие ошибки, связанные с DAG, отображаются в пользовательском интерфейсе Apache AirFlow и как дата-инженеру их исправить. А также рассмотрим еще несколько рекомендаций по повышению эффективности этого фреймворка. 4 ошибки с DAG в интерфейсе Apache AirFlow и как их исправить Сегодня все больше компаний, независимо от их домена и...