
Сегодня рассмотрим, как запустить Apache AirFlow на мощностях Google в интерактивной среде Colab и войти в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. Запуск Apache AirFlow в Google Colab Хотя Google Colab является мощным облачным окружением для запуска и написания Python-кода, выполнение написанных...
Самый простой способ организовать обработку и логирование ошибок в приложении-потребителе, чтобы продолжать считывание из Apache Kafka, даже если продюсер изменил структуру полезной нагрузки сообщения. Публикация данных в Kafka Напомним, Apache Kafka, в отличие от RabbitMQ, не позволяет организовать очередь недоставленных сообщений (DLQ, Dead Letter Queue) средствами самой платформы, о чем мы...
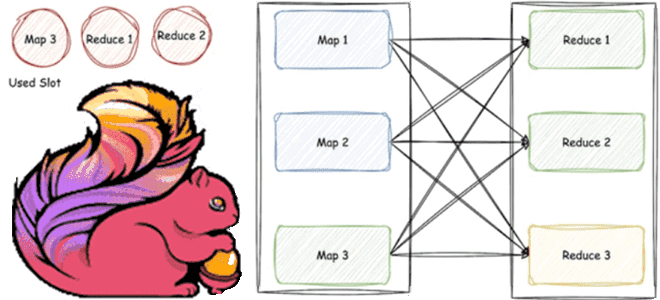
Что не так с планированием задач shuffle-операций, какие проблемы пакетной обработки данных устраняет введение гибридной перетасовки в Apache Flink 1.16 и как работает этот режим Hybrid Shuffle. Что такое режим гибридного перемешивания в Apache Flink В версии Apache Flink 1.16, о которой мы писали здесь, был впервые представлен режим гибридной...

Сегодня заглянем внутрь Neo4j, чтобы разобраться с базовыми концепциями этой графовой базы данных. Какие уровни изоляции транзакций поддерживаются в Neo4j, почему одна установка по умолчанию содержит две базы данных, что такое составная БД и как с этим работать. Транзакции в Neo4j Neo4j — это популярная нативная графовая СУБД, способная управлять...
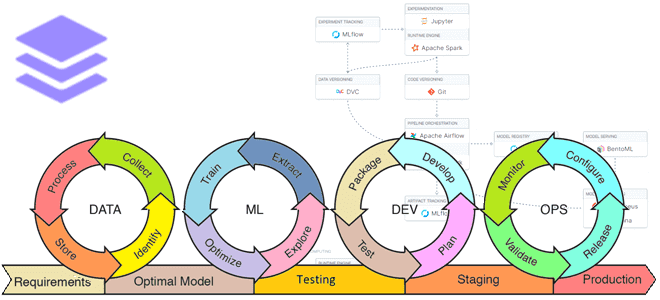
Вчера я нашла очень интересный MLOps-проект, который позволяет построить конвейер поддержки жизненного цикла системы машинного обучения, используя более 50 популярных инструментов. Что такое MyMLOps и как это пригодится ML-инженерам. Что такое MyMLOps: новый сервис для MLOps Чтобы реализовать идеи концепции MLOps автоматизации всего жизненного цикл системы машинного обучения, от подготовки...
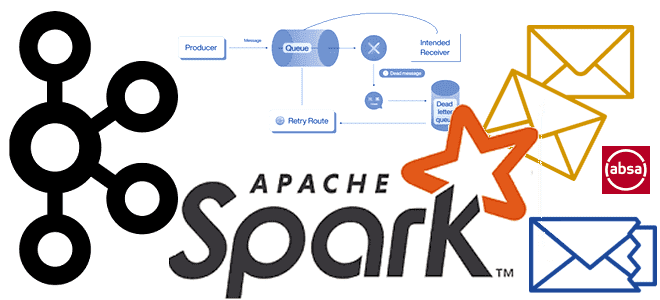
Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS. DLQ для Apache Kafka в Spark-приложении Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается....
Почему DevOps-подходы не так просто внедрить в инженерию данных, что не так с реестром Apache NiFi и зачем расширять набор инструментов Toolkit собственным Java-приложением для автоматизированной миграции потоковых конвейеров в разные среды развертывания. Что не так с реестром Apache NiFi с точки зрения DevOps-инженера Изначально Apache NiFi был создан как...
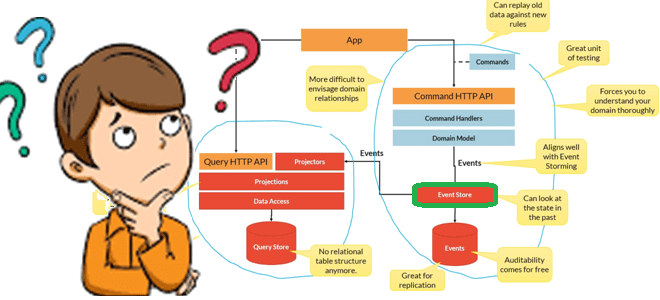
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...

Будучи популярным фреймворком для оркестрации пакетных процессов обработки Apache AirFlow образует вокруг себя целую экосистему. Сегодня познакомимся с некоторыми инструментами, которые пригодятся дата-инженеру для проектирования и отладки конвейеров данных: ADA, Ditto, Amundsen, gusty и Viewflow. Аналитика системных метрик Apache AirFlow с ADA и Amundsen ADA — это микросервис, созданный для...

Недавно мы писали про группы общего доступа в Apache Kafka, которые планируется реализовать в KIP-932. Сегодня рассмотрим, как именно это предполагается сделать. Принципы работы группы общего доступа Предложение по улучшению Kafka (KIP, Kafka Improvement Proposal) предполагает внесение значительных изменений. Все начинается с публикации предложения, которое рассматривается сообществом, комментируется и пересматривается до...
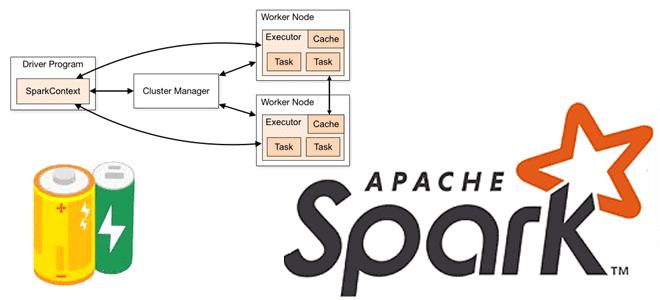
Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере. Широковещательные переменные vs аккумуляторы В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например,...
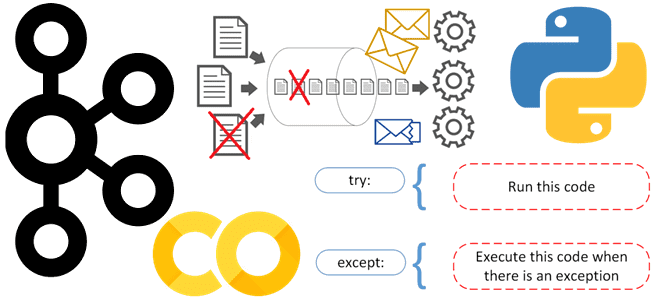
Сегодня поговорим о том, как обработка исключений позволяет спроектировать и реализовать надежную архитектуру конвейера обработки данных, включая ETL/ELT-процессы и их компоненты. Архитектура конвейеров обработки данных: ETL/ELT-процессы Наличие хорошо спроектированной инфраструктуры данных необходимо для получения максимальной отдачи от данных для data-driven управления. Поскольку данные постоянно увеличиваются в объеме, следует организовать управление...

Подводим итоги нарушений информационной безопасности в Apache NiFi за первую половину 2023 года. Инъекции кода, десериализация недоверенных данных и неправильное ограничение ссылок на внешние объекты XML. Какие уязвимости в Apache NiFi найдены и исправлены за первую половину 2023 года За 2023 год в Apache NiFi выявлено и исправлено всего 3...
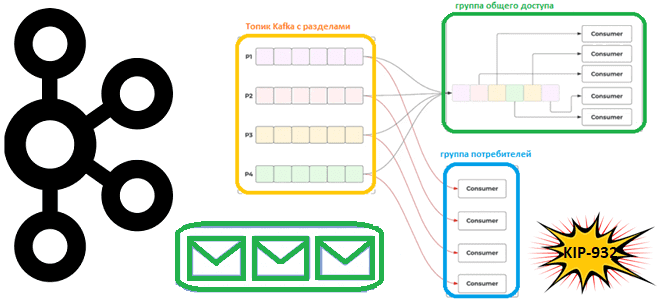
Что такое группы общего доступа для потребителей, чем это отличается от существующей концепции группы потребителей, почему в Apache Kafka появляются очереди и чем это улучшит потоковую обработку событий. Что такое KIP-932: группы общего доступа потребления данных из Apache Kafka Напомним, группы потребителей в Kafka предназначены для повышения надежности упорядоченной доставки...
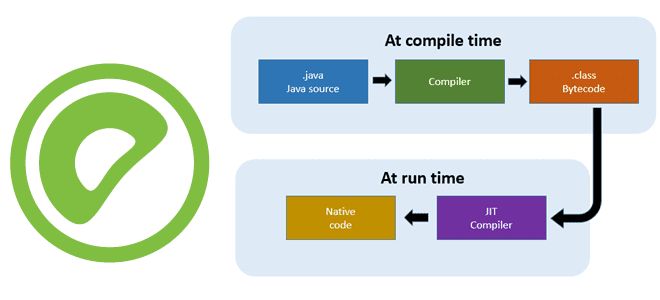
Чтобы SQL-запросы выполнялись быстрее, в Greenplum, как и в PostgreSQL, поддерживается JIT-компиляция. Читайте далее, что это такое и всегда ли эта динамическая генерация машинного кода на лету дает выигрыш в скорости для аналитики больших данных. Что такое JIT-компиляция Технология JIT-компиляции (Just-In-Time) позволяет генерировать машинный код во время выполнения программы. В...
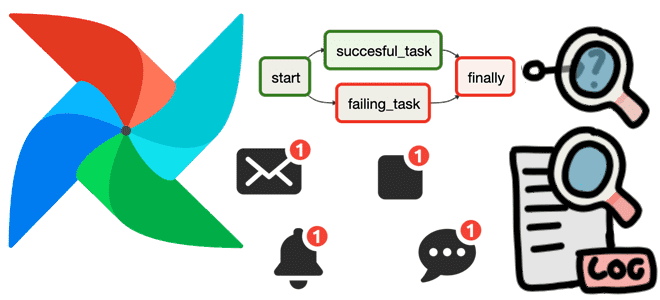
Как использовать функции обратного вызова для отладки конвейера обработки данных в Apache AirFlow, а также отправки оповещений об ошибках. Полезные примеры регистрации и мониторинга сбоев на уровне задачи и всего DAG с on_failure_callback(). Польза обратных вызовов Apache AirFlow на примере on_failure_callback По мере роста и усложнения конвейеров данных, построенных с...

Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника. Прямой поток и подход на основе приемника Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме...

Недавно мы писали про источники данных Apache Flink. Сегодня рассмотрим, как создать и протестировать собственный источник данных для их обработки в распределенном приложении. Создание своего источника данных в Apache Flink Напомним, источник данных в Apache Flink состоит из трех основных компонентов: Split, SplitEnumerator и SourceReader. Splits — это часть данных,...

11 июня 2023 года вышел очередной релиз Apache NiFi. Разбираемся с главными новинками выпуска 1.22.0: улучшения, добавленные возможности и замененные компоненты. Главные новинки Apache NiFi 1.22.0: обзор июньского релиза Основные моменты выпуска 1.22.0 включают: Агенты MiNiFi теперь могут общаться с серверами C2, используя обратный прокси или балансировщик нагрузки. В то...
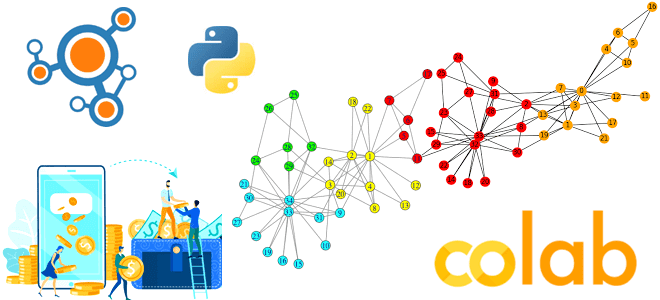
Недавно мы разбирали, чем внутренне устройство графовых баз данных отличается от реляционных. Поэтому именно графовые базы целесообразно использовать для анализа больших графовов. Однако, на малых датасетах вполне можно обойтись и Python-библиотекой Networkx, что мы и рассмотрим далее на примере анализа банковских транзакций. Python-скрипт поиска сообществ в графе с библиотекой...