
7 ноября 2021 года вышел очередной релиз Apache NiFi с новыми фичами, улучшениями и исправлениями ошибок. Краткий обзор самых важных новинок: от постоянного хранилища для stateless-потоков и настроек облачных провайдеров до интеграции процессоров с пользователями Kerberos и улучшения работы с GitHub. Новинки и улучшения Apache NiFi 1.15.0 Свежий выпуск Apache...
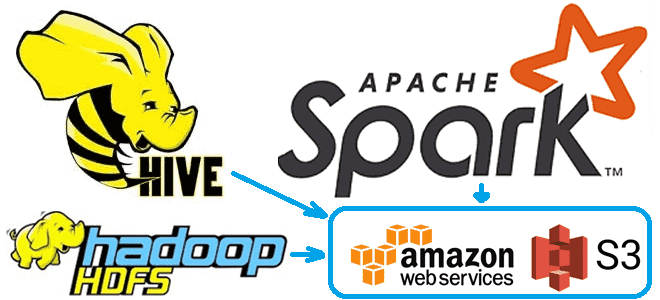
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive. Еще раз о разнице...
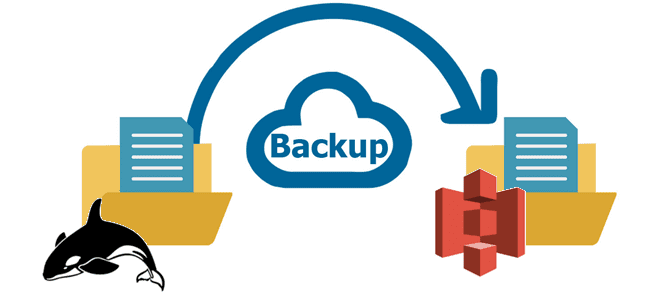
В статье для дата-инженеров и администраторов Apache Hadoop разберем, как реализовать инкрементное резервное копирование таблиц HBase из кластеров CDH/CDP в облачное объектное хранилище AWS S3. Практический пример от международной ИТ-компании Clairvoyant. 5 способов резервного копирования в Apache HBase Apache HBase - это популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой...

Недавно мы писали, что в новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, сделаны попытки объединения потоковой и пакетной парадигм обработки данных. Сегодня рассмотрим, как подобное стремление к унификации реализуется на практике дата-инженерами фотохостинга Pinterest, которые используют Apache Flink как универсальный инструмент аналитики больших данных в...

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....

Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....

Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим, что представляет собой облачная платформа VMware Tanzu Greenplum, где ее можно развернуть и каковы преимущества cloud-решения по сравнению с локальной версией этой MPP-СУБД. Что такое VMware Tanzu Greenplum и чем это отличается от open-source версии Напомним, в 2020 году корпорация...
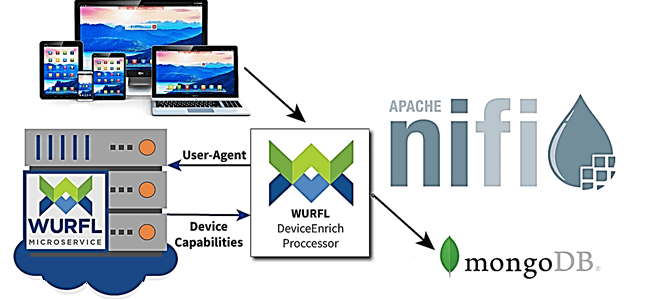
Развивая наши курсы по Apache NiFi для дата-инженеров и администраторов, сегодня рассмотрим, как как обогатить поток данных, сделав информацию об устройстве доступной для систем, которые хранят или потребляют данные в следующих этапах конвейера. Также разберем, зачем нужна технология детектирования устройств, что такое WURFL и как это реализовать в Apache NiFi....

В этой статье для дата-инженеров рассмотрим кейс компании PayPal, которая переводит свои аналитические рабочие нагрузки из локального кластера Apache Spark в Google Cloud Processing. Читайте далее, чем это решение оказалось лучше выполнения Spark-заданий в кластере DataProc с использованием данных BigQuery и облачного хранилища Google (GCS, Google Cloud Storage) для потоковой...
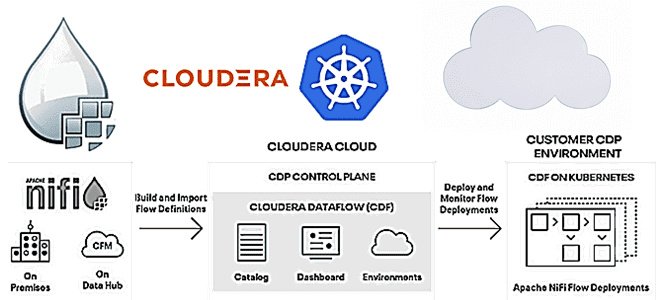
Чтобы сделать наши курсы по Apache NiFi для дата-инженеров еще более полезными, сегодня рассмотрим новые возможности последнего релиза Cloudera Flow Management 2.1.1 на базе этого фреймворка. Выпущенная в апреле 2021 года, платформа Cloudera Flow Management в составе публичного и частного облака предоставляет Apache NiFi версии 1.13.2, включая дополнительные компоненты, а...

Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL....

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...
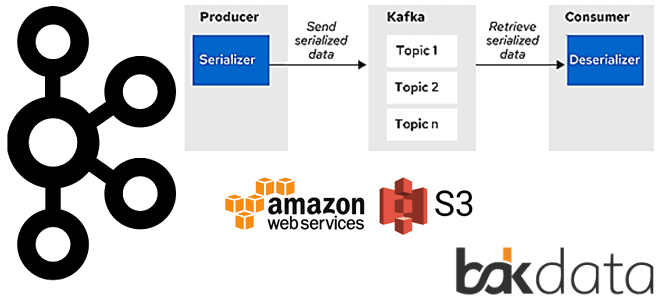
Сегодня рассмотрим проблему обработки больших сообщений в Apache Kafka Streams и способы ее решения с помощью средства сериализации и десериализации (SerDe) от немецкой ИТ-компании Bakdata. Узнайте, почему максимального лимита конфигурации max.message.bytes не хватает, зачем и как приложение Kafka Streams материализует данные, а также каким образом kafka-s3-backed-serde читает и записывает большие...
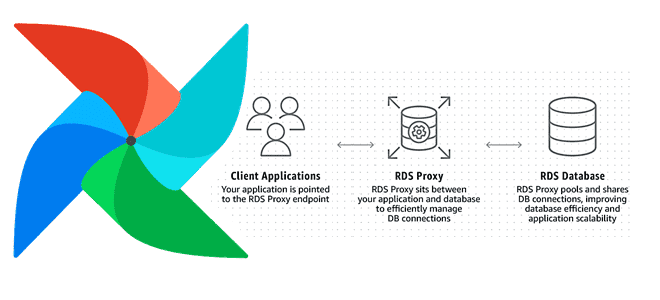
Увеличение пропускной способности и повышение скорости обработки данных на любой Big Data платформе при приемлемых затратах – одна из главных задач дата-инженера. Сегодня мы рассмотрим, как улучшить производительность множества экземпляров Apache AirFlow с помощью прокси-сервера Amazon RDS и сколько это стоит в денежном выражении: кейс компании Datafy. Больше не значит...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...
Сегодня поговорим про обработку геопространственных данных с Apache Spark и рассмотрим, что такое Apache Sedona, как этот фреймворк связан с GeoSpark, какие форматы и структуры данных он поддерживает. Читайте далее про пространственные RDD, Spatial SQL-запросы и построение конвейеров обработки геоданных в облачных сервисах Amazon. Как обработать геопространственные данные в...

Чтобы добавить в наши практические курсы по Apache Kafka еще больше интересных примеров, сегодня рассмотрим кейс немецкой ИТ-компании Mobimeo, которая несколько раз перекраивала свою систему аналитики больших данных, чтобы быстро узнавать о событиях клиентских приложений. Читайте далее, зачем дата-инженеры Mobimeo предпочли AVRO формату JSON, почему вместо брокера сообщений ActiveMQ решили...
Совмещение Airflow с Kubernetes уже становится стандартом де-факто для дата-инженеров. Недавно мы рассказывали про 3 популярные среды развертывания и сопровождения этого ETL-фреймворка в Kubernetes. Продолжая эту тему, сегодня рассмотрим, какие операторы использовать для контейнерного запуска batch-задач, а также поговорим о том, как Docker-образы помогут решить проблему изменения версий Python и...

Для практического использования Apache Airflow в production дата-инженеру необходимо не только обучение основам работы с этим фреймворком, но и знания о базовой инфраструктуре его развертывания. Поэтому сегодня поговорим о 3-х популярных средах для развертывания и сопровождения этого ETL-фреймворка: Astronomer, Google Cloud Composer и Amazon Managed Workflows, разобрав их основные возможности...

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...