
Чтобы добавить в наши курсы для ИТ-архитекторов и дата-инженеров еще больше практических примеров, сегодня разберем ключевые требования к современному озеру данных и самые последние тренды в аналитике Big Data. Что такое DaaS, зачем это нужно и каковы риски. 7 преимуществ развертывания Data Lake в облаке При том, что Data Lake...

В отличие от каменных зданий, архитектуры данных постоянно меняются. Сегодня рассмотрим новую архитектурную модель под названием BigLake, выпущенную Google весной 2022 года. Что это такое, как устроено, чем похоже на Lakehouse, озеро данных и Data Mesh, а также чем от них отличается и какую пользу несет для конвейеров аналитики Big...

Недавно мы писали, от каких факторов зависит выбор подходящего MLOps-инструмента. В продолжение этой темы сегодня специально для ML-инженеров разберем сходства и различия двух самых популярных MLOps-решений: что общего у MLflow и Kubeflow, чем они отличаются и в каких случаях выбирать тот или иной инструмент. Краткий обзор 2-х самых популярных MLOps-решений...
Чтобы сделать наши курсы для специалистов по Machine Learning еще более интересными, сегодня рассмотрим 5 лучших практик по использованию популярного MLOps-инструмента. Как Data Scientist может работать с MLflow и сделать свои конвейеры машинного обучения еще более эффективными. Компоненты Mlflow для разработки и развертывания ML-систем Сегодня MLOps считается одним из самых...

В этой статье для обучения дата-инженеров сравним популярный ETL-оркестратор Apache AirFlow с облачным бессерверным сервисом от AWS под названием Step Functions. Оба этих решения представляют собой workflow-сервисы, которые позволяют автоматизировать бизнес-процессы и упростить процедуры дата-инженерии. Читайте далее, что между ними общего и чем они отличаются, а также какой из них...
В этой статье для специалистов по Machine Learning рассмотрим, от каких факторов зависит выбор MLOps-средств и как сделать его наиболее верным способом. Когда развертывание продукта с открытым исходным кодом или индивидуального решения на собственной инфраструктуре лучше готового инструмента в облаке и почему часто бывает наоборот. 3 главных фактора выбора MLOps-решений...

Как Cluster Autotuner от Sync для автонастройки кластера Spark в AWS EMR помог edtech-компании Duolingo снизить затраты на 55%. Полезный сервис для дата-инженера и администратора кластера, чтобы устранить неэффективную ручную настройку, обеспечив оптимальную стоимость, производительность и надежность распределенных вычислений без изменения кода. Дорогой Apache Spark на AWS EMR Duolingo –...
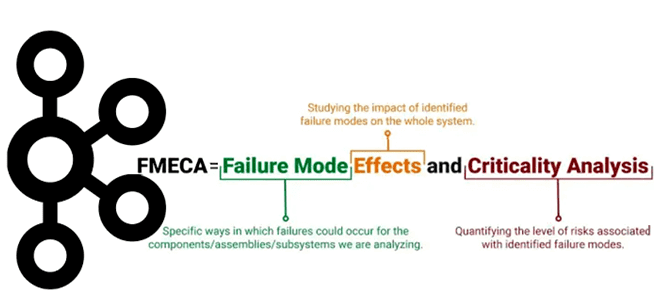
Хотя Apache Kafka является надежной платформой потоковой обработки событий, что особенно важно для распределенных приложений, отказы случаются и в ней. Сегодня разберем важную для обучения разработчиков и дата-инженеров тему про идентификацию и обработку отказов в Kafka-приложениях с помощью простого, но эффективного метода теории надежности. Что такое FMECA-анализ, как его проводить...

Недавно в Google Dataproc появился бессерверный Apache Spark. Разбираемся, что это такое и зачем нужно дата-инженерам. Как работает serverless Spark в облачной платформе Google и почему выбирать между Dataflow и Dataproc стало еще сложнее. Блеск и нищета Google Dataproc Напомним, Google Dataproc – это облачный Hadoop, который работает аналогично другим...
Недавно мы писали про Yandex Managed Service for Apache Kafka. Продолжая тему импортозамещения, сегодня рассмотрим, как этот и другие полностью управляемые сервисы Яндекса помогли отечественному маркетплейсу KazanExpress построить эффективное BI-решение. Что такое Yandex DataLens и как он способен заменить зарубежные системы бизнес-аналитики типа Tableau с Power BI, а также открытый Apache...

Сегодня разберем опыт австралийской ИТ-компании hipages по построению самообслуживаемого ETL-конвейера с Apache Airflow и Amazon Athena, призванного обеспечить высокое качество данных и облегчить дата-инженерам управление информационными активами. Изящное решение сложных проблем управления данными с примерами SQL-запросов к корпоративному Data Lake на AWS S3. Что не так с монолитной архитектурой платформы данных...

В свете импортозамещения сегодня рассмотрим российские альтернативы облачных управляемых сервисов для развертывания Apache Kafka. Сравнение отечественных Yandex Managed Service for Apache Kafka и VK Cloud Solutions Big Data с зарубежным Confluent Cloud. Облачная Apache Kafka от Confluent и не только Пожалуй, самым популярным облачным сервисом Apache Kafka во всем мире...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...

Как снизить затраты на AWS EMR, сохранив эффективность Spark-конвейеров обработки данных на спотовых инстансах и других типах узлов облачного кластера. Также рассмотрим, что такое прерываемые виртуальные машины в Яндекс.Облаке и каким образом настроить такую облачную инфраструктуру, чтобы сократить затраты на выполнение Spark-приложений, одновременно повысив их отказоустойчивость. Блеск и нищета спотовых...

В этой статье для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных разберем пример перевода сервиса Strava с кластера Cassandra в облачное хранилище AWS S3 и какую роль в этом сыграл вычислительный движок Apache Spark. Постановка задачи: слишком дорогая Cassandra Strava – это глобальный сервис отслеживания активности велосипедистов, бегунов...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...

В рамках обучения разработчиков распределенных Spark-приложений, сегодня рассмотрим, как добавить функции из пользовательских JAR-файлов в кластер AWS EMR. Достоинства и недостатки действия начальной загрузки EMR с переопределением конфигурации Spark, а также расширенное управление зависимостями через spark-submit. Трудности обращения к пользовательским JAR в Amazon EMR с Apache Spark и Livy На...

В этой статье для разработчиков Spark-приложений и дата-инженеров рассмотрим особенности взаимодействия с облачным объектным хранилищем больших данных AWS S3. Как повысить эффективность и ускорить выполнения Spark-заданий на чтение данных из S3: рекомендации Pinterest. Пара советов по работе Apache Spark с AWS S3 Прежде чем перейти к опыту дата-инженеров фотохостинга Pinterest,...
Недавно мы писали про пользу snapshot’ов Apache HBase на примере компании Vimeo. Сегодня рассмотрим кейс корпорации Box, которая специализируется на облачных enterprise-продуктах совместного управления контентом и файлами. Переход от локальной HBase к Google Cloud BigTable: сложности миграции и способы их обхода. Сходства и различия Apache HBase с Google Cloud BigTable...

Сегодня рассмотрим кейс международной ИТ-компании AppsFlyer, которая создает SaaS-решения для маркетинговой аналитики в режиме онлайн. В этой статье команда разработки аналитического продукта Data Locker делится опытом оптимизации ETL-приложений Apache Spark для снижения стоимости обработки данных и ускорения вычислений. Предыстория: слишком много файлов в ETL-решении на Spark и AWS S3 в...