
Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j: знакомство с Python-пакетом для RDF-графов rdflib-neo4j. Возможности, ограничения и пример использования. Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j Что такое RDF-графы, триплеты и плагин Neosemantics для работы с этими концепциями в графовой СУБД...
Какие файловые системы поддерживает Apache Flink: средства взаимодействия с файлами, хранящимися локально или в объектных хранилищах HDFS, S3 и GCS. Особенности работы с файловыми системами в Apache Flink Apache Flink имеет собственную абстракцию файловой системы через класс org.apache.flink.core.fs.FileSystem. Эта абстракция обеспечивает общий набор операций и минимальные гарантии для различных типов...
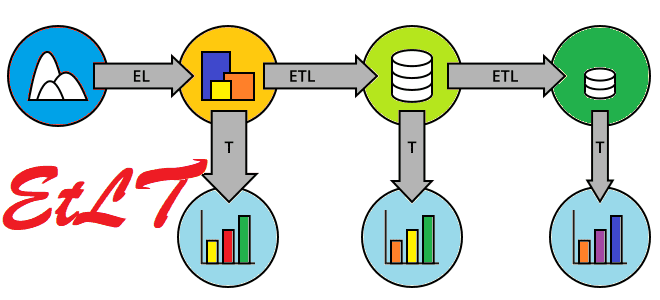
Как развивалась архитектура конвейеров обработки данных, что такое EtLT и почему этот подход почему постепенно заменяет классические ETL и ELT-инструменты. Краткая история развития современной дата-инженерии. От ETL к ELT и обратно: предыстория Архитектура конвейеров обработки данных претерпела несколько итераций от ETL, ELT, XX ETL (Reverse ETL, Zero-ETL) до EtLT. Если экосистема...
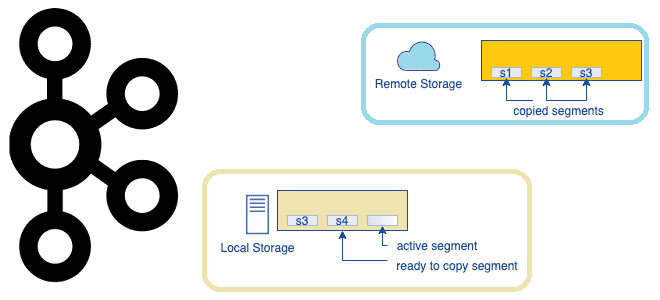
Что представляет собой очередное предложение по улучшению проекта Apache Kafka, которое расширяет возможности этой распределенной платформы потоковой передачи событий, превращая ее в средство долговременного хранения данных. Надежность vs скорость: вечный компромисс в Apache Kafka Изначально Apache Kafka позиционировалась как middleware, т.е. сервисный слой для асинхронной интеграции нескольких информационных систем. Этот...
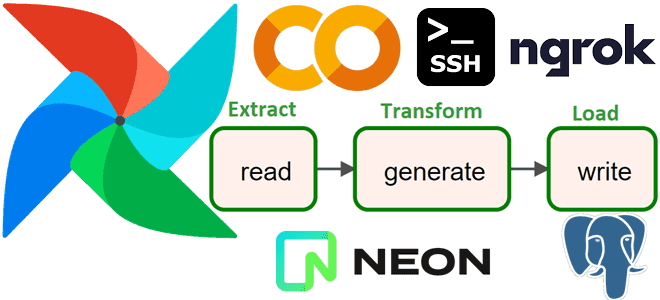
Сегодня реализуем простой ETL-конвейер для реляционной СУБД PostgreSQL, запустив Apache AirFlow в интерактивной среде Google Colab. Пример DAG из 3-х задач: получить количество строк в одной из таблиц БД, сгенерировать новые строки и записать их, не нарушив ограничений уникальности первичного ключа. Постановка задачи Возьмем в качестве примера базу данных для...
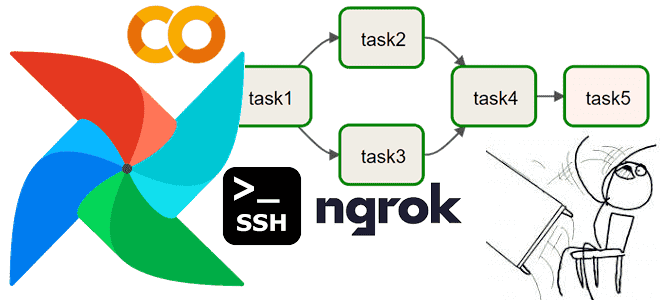
Медленно, муторно, небезопасно: что не так с запуском Apache AirFlow в интерактивной среде Google Colab и можно ли с этим смириться. Разбираем на личном опыте. Трудности работы с Apache AirFlow в среде Google Colab О том, что можно настроить AirFlow в Google Cloud Platform, и запускать DAG-файлы из Colab, используя...

Что общего у Apache HBase с Google Bigtable, чем они отличаются и какую NoSQL-СУБД выбирать для практического использования. Чем похожи NoSQL-хранилища для больших данных Apache HBase часто называют Google BigTable для Hadoop, поскольку она обеспечивает аналогичные возможности и использует многие концепции этой облачной NoSQL-СУБД. В частности, именно Bigtable был выпущен...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...

Как MLOps-инженеры платформы онлайн-курсов Udemy ускорили цикл разработки и внедрения проектов машинного обучения, используя возможности Amazon SageMaker для создания и отладки Spark-приложений в удаленном облачном кластере. MLOps на AWS Чтобы воспользоваться преимуществами бесшовной интеграции процессов разработки и развертывания машинного обучения согласно концепции MLOps, совсем не обязательно выстраивать собственную платформу из...
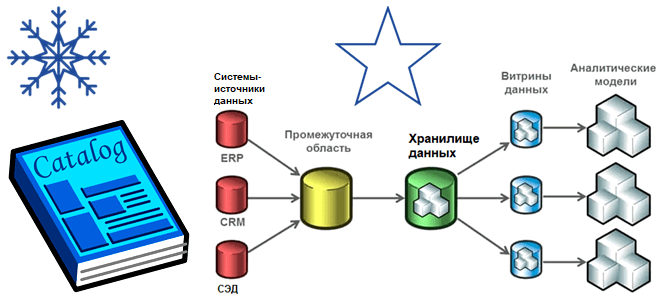
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...

В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных. Постановка задачи и ограничения POC для...
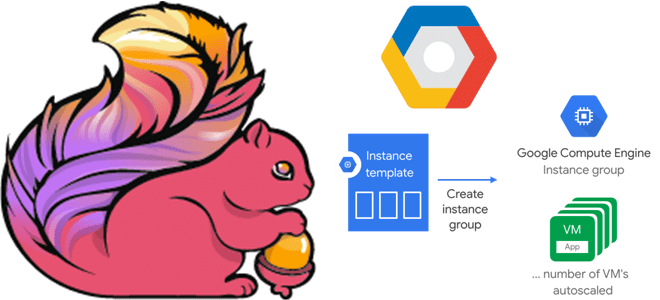
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера. Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости Apache Flink — отличный фреймворк создания приложений...

Учитывая рост интереса к DevOps-инструментам, сегодня рассмотрим, зачем переводить кластер Apache Spark, управляемый YARN, в Kubernetes, и как это сделать наиболее эффективно. А также разберем, какие системные метрики контейнерных Spark-приложений надо отслеживать и с помощью каких средств. Зачем переводить кластер Apache Spark от YARN на Kubernetes Apache Spark не зря...

Недавно мы писали про чтение данных из AWS S3 с помощью PySpark-задний. Продолжая разбираться, как перейти от HDFS к облачным объектным хранилищам, сегодня рассмотрим пример чтения и записи файлов из Google Cloud Storage с помощью Apache Spark. От HDFS к GCS Распределенная файловая система Apache Hadoop (HDFS) уже много лет...
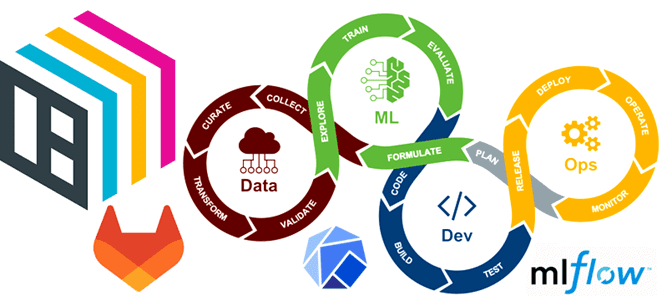
Чтобы сделать наши курсы для DevOps-инженеров и специалистов по Machine Learning еще более полезными, сегодня рассмотрим, как автоматизировать развертывание и обслуживание ML-моделей согласно концепции MLOps с помощью GitLab CI/CD, BentoML, Yatai, MLflow и Kubeflow. BentoML для CI в MLOPS При развертывании ML-модели необходимо учитывать следующие аспекты: как была построена модель...

Мы уже сравнивали MLflow и Kubeflow, которые позволяют управлять конвейерами машинного обучения. Продолжая эту важную для ML-инженера тему, сегодня рассмотрим 2 других MLOps-инструмента для оркестрации конвейеров Machine Learning: Vertex AI Pipelines и Apache AirFlow. Что такое Vertex AI Pipelines от Google Поскольку цель концепции MLOps в том, чтобы объединить разработку...

Data Mesh воплощает децентрализованный подход к построению распределенной архитектуры данных. При всех достоинствах этой модели, которая совмещает потоковую и пакетную парадигмы обработки данных, она еще довольно незрелая и имеет ряд недостатков. Одним из них является проблема с информационной безопасностью, что мы и рассмотрим далее для обучения ИТ-архитекторов и дата-инженеров. Безопасность...

Недавно мы рассматривали производительность ETL-конвейеров на Apache Spark с озером данных на MinIO. Сегодня разберем, чем это легковесное объектное хранилище отличается от распределенной файловой системы Apache Hadoop и как перейти на него с HDFS. Зачем переходить на MinIO Хотя HDFS до сих пор активно используется во многих Big Data проектах...

В связи с активным переходом от локальной ИТ-инфраструктуры в облачные полностью управляемые сервисы многие ИТ-архитекторы и дата-инженеры задумываются о замене собственного кластера Apache Kafka ее Cloud-альтернативами. Читайте, что общего у Apache Kafka с AWS Kinesis, чем они отличаются и какую платформу выбрать для потоковой передачи событий. Потоковая обработка событий с...
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...