
В этой статье для дата-инженеров рассмотрим новую полезную фичу июньского выпуска Greenplum и обновления интеграционного фреймворка PXF, который обеспечивает интеграцию этой MPP-СУБД с внешними источниками и приемниками данных. Читайте далее, как PXF поддерживает запись данных в формате AVRO в Hadoop HDFS и хранилища объектов, а также чтение логических типов этого...
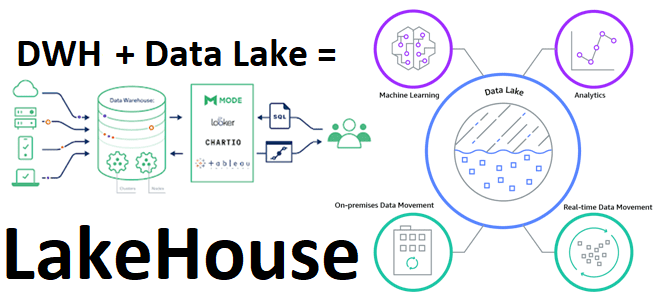
В рамках обучения дата-инженеров и архитекторов корпоративных платформ и приложений аналитики больших данных, сегодня рассмотрим, что такое LakeHouse. Как эта новая гибридная архитектура управления данными объединяет 2 разнонаправленные парадигмы хранения информации, а также чего от нее ожидают бизнес-пользователи, дата-инженеры, аналитики и ML- специалисты. Историческая справка: от DWH к Data Lake...
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...

Сегодня рассмотрим пример программы лояльности турецкого интернет-магазина Trendyol, где Apache Kafka и документо-ориентированная NoSQL-СУБД Couchbase используются для генерации купонов на скидки. Почему при большом объеме данных случаются проблемы тайм-аутов в Couchbase, как их решить и при чем здесь коннекторы к Apache Kafka. Архитектура системы управления купонами Trendyol – это популярный...

Для обучения дата-инженеров и аналитиков данных, сегодня рассмотрим приемы оптимизации SQL-запросов в Apache Hive, выполняемых движком Tez. Каким образом Tez рассчитывает оптимальное количество редукторов, зачем включать индексацию фильтров, как статистика таблицы помогает улучшить план выполнения запросов и что за конфигурации нужно менять. 3 движка выполнения запросов в Apache Hive Напомним,...
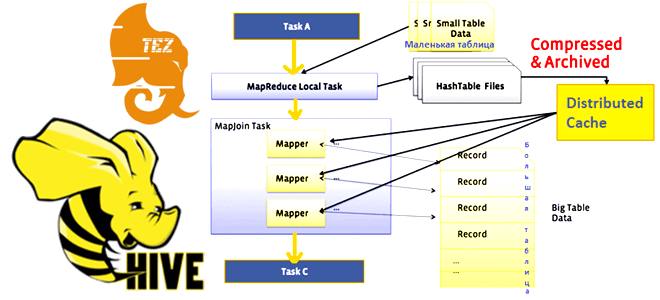
В этой статье для обучения дата-инженеров, аналитиков данных и разработчиков распределенных приложений рассмотрим один из методов оптимизации SQL-запросов в Apache Hive. Что такое оператор MapJoin, в каких условиях и как он работает, чем выгоден для HiveQL-запросов и почему при его выполнении с движком Tez может возникнуть нехватка памяти. Что такое...
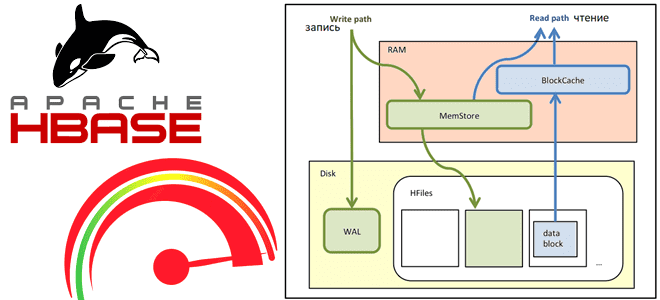
Сегодня рассмотрим, как выполняются операции чтения и записи в Apache HBase, а также с помощью каких приемов можно их ускорить. Как рассчитать оптимальное количество регионов в таблице, зачем отключать версионирование, почему размер ключа строки должен быть небольшим и еще 7 полезных лайфхаков для администратора HBase-кластера. Оптимизация записи данных в Apache...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим особенности обработки пакетных транзакций в популярной графовой СУБД Neo4j . Когда вместо простых запросов встроенного SQL-подобного языка Cypher лучше использовать процедуры библиотеки APOC, чтобы избежать проблем с памятью или остановки обновлений. OOM, большие графы и пакетные транзакции в Neo4j...

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...

Сегодня в рамках продвижения нашего курса по графовой аналитике больших данных в бизнес-приложениях, рассмотрим новый инструмент популярной графовой СУБД Neo4j для загрузки данных - Data Importer. Что это такое, как работает, чем полезно специалисту по Data Science и зачем обновлять его до последней версии. Что такое Neo4j Data Importer Графовая...
Мы уже рассматривали, как загрузить в Greenplum большие объемы данных. В продолжение этой важной для обучения дата-инженеров темы, сегодня разберем еще несколько инструментов, решающих задачу организации ETL-процессов с этой MPP-СУБД. ETL-инструменты PostgreSQL Хотя Greenplum может хранить и обрабатывать огромные наборы данных на уровне петабайт, эта СУБД не генерирует их самостоятельно,...
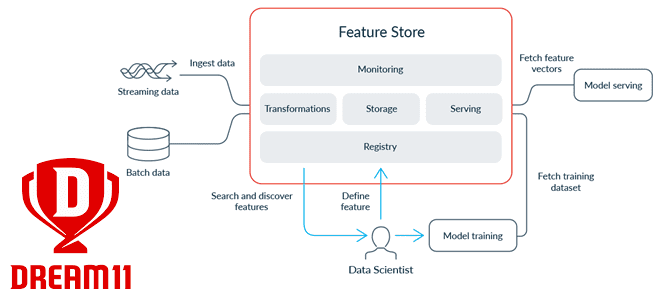
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...

В рамках практического обучения аналитиков данных и специалистов по Data Science реальным задачам современных бизнес-приложений, сегодня разберем актуальную и острую для многих стран тему по промышленному использованию природных ресурсов в современных непростых условиях. Строим граф европейской газотранспортной системы в Neo4j. Создание графа европейской газотранспортной системы в Neo4j Российский природный газ...
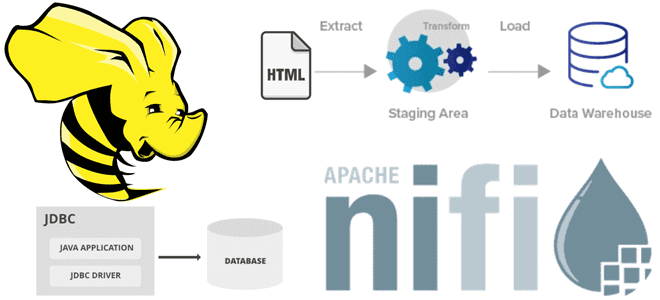
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени. Постановка задачи: ETL-процесс веб-скрейпинга В реальной жизни задача считать данные с веб-сайта для последующей...
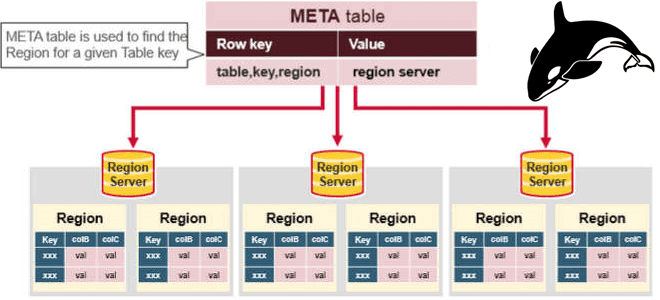
Сегодня затронем тему администрирования кластеров Apache HBase и рассмотрим, приносит ли реальную пользу совместное размещение нескольких региональных серверов (RegionServer) на одном узле кластера. Сравнительный анализ по тестам YCSB-бенчмарка. Регионы и сервера Apache HBase Напомним, Apache HBase является популярной колоночной NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности...

Как быстро и эффективно с помощью Neo4j выявить преступников, незаконно ввозящих в страну контрафактные товары. Почему графовая СУБД Neo4j обошла документо-ориентированную MongoDB, из чего состоит алгоритм поиска рецидивистов средствами технологий аналитики больших данных и как это может пригодиться в других бизнес-приложениях. Постановка задачи: сложности отслеживания контрафакта Каждый день практически в...

В этой статье для дата-инженеров и администраторов кластера рассмотрим, как считать данные из распределенной файловой системы Apache Hadoop в MPP-СУБД Greenplum. Архитектура и принцип работы PXF-коннектора к HDFS с примерами команд. Интеграция Greenplum и Hadoop через PXF-коннекторы Мы уже писали, что представляет собой интеграционный фреймворк PXF (Platform Extension Framework), который...

В этой статье для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных разберем пример перевода сервиса Strava с кластера Cassandra в облачное хранилище AWS S3 и какую роль в этом сыграл вычислительный движок Apache Spark. Постановка задачи: слишком дорогая Cassandra Strava – это глобальный сервис отслеживания активности велосипедистов, бегунов...
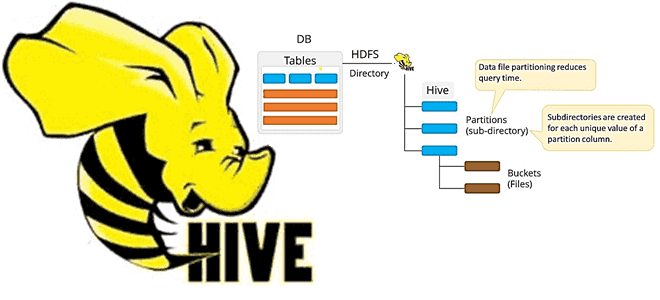
Что такое MSCK REPAIR TABLE в Apache Hive, зачем нужна эта команда, ее достоинства и недостатки, а также альтернативные варианты для задач пакетной дата-инженерии. Разбираем на примере конвейера обработки данных в ML-приложениях при работе с Data Lake. Команда MSCK REPAIR TABLE в Apache Hive В ML-приложениях особенно важно, как озеро данных (Data...