
14 июля 2021 года вышел минорный релиз Apache NiFi – версия 1.14.0. Сегодня рассмотрим его главные фичи, исправленные ошибки и улучшения, уделив особое внимание новым функциям обеспечения информационной безопасности в этой популярной платформе управления потоками Big Data. ТОП-5 новинок Apache NiFi 1.14.0 В новом выпуске Apache NiFi 1.14.0 исправлено 139...

Продолжая обучение дата-инженеров, сегодня рассмотрим, как сделать управление потоками данных в Apache NiFi эффективнее. Читайте далее, какие настройки позволят обойтись без процессора RetryFlowFile для повторных попыток, зачем менять GetFile на ListFile и FetchFile, когда использовать воронки и почему типичные настройки Linux не подходят для NiFi. Неочевидные особенности готовых процессоров Напомним,...

В рамках нового курса Эксплуатация Apache NIFI, сегодня разберем особенности развертывания этого маршрутизатора потоков Big Data на платформе управления контейнерными приложениями Kubernetes. Советы дата-инженерам, как сократить расходы на AWS, избежать сбоев узлов и потерь данных, обеспечить безопасность и автоматическое масштабирование облачного кластера Apache NiFi в Amazon EKS, а также зачем...

Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...

Сегодня разберем еще одну интересную тему из нашего нового курса «Greenplum для инженеров данных» по построению конвейеров приема данных для этой MPP-СУБД в рамках веб-интерфейса платформы автоматизированного управления потоками работ Apache NiFi. Читайте далее, как устроен коннектор VMware Tanzu Greenplum для Apache NiFi и какие возможности он предоставляет дата-инженеру. Что...

В рамках обучения дата-инженеров, сегодня рассмотрим проблему роста числа операций ввода-вывода в секунду (IOPS) при обработке большого количества данных в потоках Apache NiFi и способы ее решения. Читайте далее, как перемещение репозиториев NiFi с жесткого диска в оперативную память снижает IOPS, а также зачем при этом в Big Data систему...

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...

Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас...

Сегодня рассмотрим, как можно фильтровать потоки больших данных в Apache NiFi через типовой механизм SQL-запросов. Читайте далее, чем эта ETL-платформа стриминговой маршрутизации Big Data отличается от других систем, которые используют язык структурированных запросов вне СУБД, какие процессоры позволяют работать с потоковыми файлами (FlowFile) как с таблицами базы данных и при...
Продолжая разговор про инженерию больших данных, сегодня рассмотрим, как построить ETL-pipeline на открытых технологиях Big Data. Читайте далее про получение, агрегацию, фильтрацию, маршрутизацию и обработку потоковых данных с помощью Apache NiFi, Kafka и Spark, преобразование JSON, а также обогащение и сохранение данных в Hive, HDFS и Amazon S3. Пример потокового...
Однажды мы уже рассказывали про StreamSets Data Collector, сравнивая его с Apache NiFi. Сегодня рассмотрим, как устроен этот исполнительный движок для запуска конвейеров обработки больших данных, каким образом он связан с Apache Spark и чем полезен инженеру Big Data при организации ETL-процессов на локальных и облачных озерах данных (Data Lake,...

Apache NiFi – это простая и мощная система для обработки и распределения больших данных в потоковом режиме, которая отлично справляется с огромными объемами и скоростями, оперируя с сотнями гигабайт и даже терабайтами информации. Однако, на практике при работе с этой Big Data платформой можно столкнуться с проблемой ввода-вывода (IOPS, Input-Output...
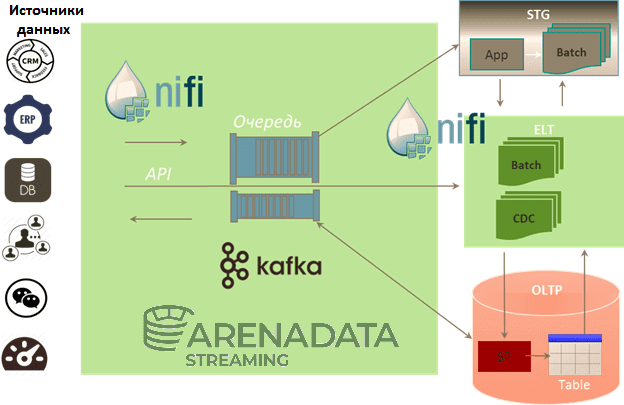
Мы уже рассказывали про преимущества совместного использования Apache Kafka и NiFi. Сегодня рассмотрим, как эти две популярные технологии потоковой обработки больших данных (Big Data) сочетаются в рамках единого решения от отечественного разработчика - Arenadata Streaming. Читайте далее про основные сценарии использования и ключевые достоинства этого современного продукта класса Event Stream...
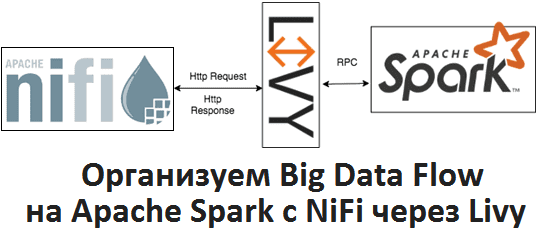
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...
Сегодня рассмотрим примеры совместного использования двух популярных технологий потоковой обработки больших данных (Big Data): Apache Kafka и NiFi. Читайте в нашей статье, как они дополняют друг друга, каковы преимущества их объединения и каким образом инженеру Data Flow это реализовать на практике. Еще раз о том, что такое Apache Kafka и...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...
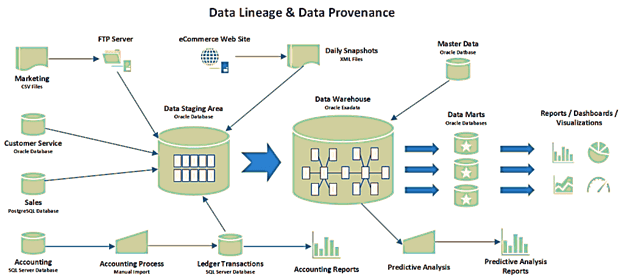
В этой статье мы продолжим разговор про основы управления данными и рассмотрим, что такое data provenance и data lineage, чем похожи и чем отличаются эти понятия. Также разберем, почему эти термины особенно важны для Big Data, какие инструменты помогают работать с ними, а также при чем здесь GDPR. Что такое...
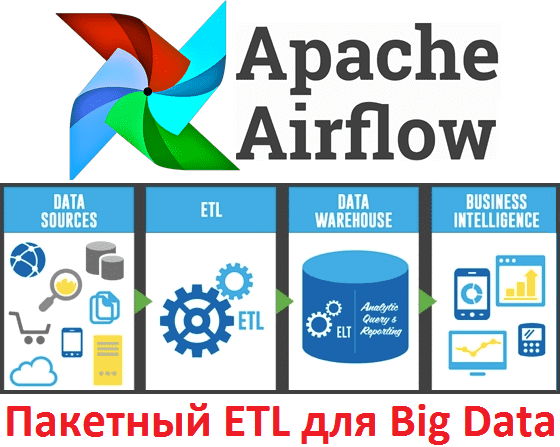
В этой статье мы поговорим про Apache AirFlow - эффективный инструмент для пакетных ETL-задач при работе с большими данными (Big Data): что это такое, как работает и чем полезен для инженера данных (Data Engineer). Также рассмотрим несколько практических примеров реального использования этой библиотеки для разработки, планирования и мониторинга batch-процессов. Что...

Завершая разговор про ETL-инструменты Big Data и цикл статей об Apache NiFi (ANF), сегодня мы сравним его со StreamSets Data Collector (SDC): чем похожи и чем отличаются эти системы маршрутизации данных. Также рассмотрим, в каких случаях следует выбирать ту или иную платформу и почему. Что общего между Apache NiFi и...