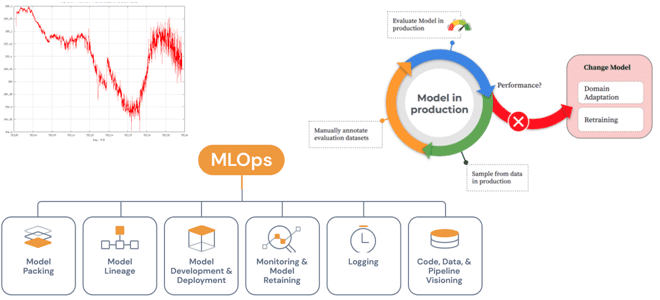
Специально для обучения ML-разработчиков сегодня разберем проблемы развертывания моделей Machine Learning в производстве и способы их решения с помощью MLOps-инструментов. А также поговорим про дрейф данных и его обнаружение методами математической статистики. Жизненный цикл ML-моделей и MLOps Каждый проект машинного обучения начинается с данных, подготовка которых занимает большую часть жизненного...
Мы уже рассказывали про важность переносимости ML-моделей, что является одним из аспектов MLOps-концепции. Сегодня разберем, почему популярный формат Pickle не лучший выбор для сохранения модели Machine Learning и что использовать вместо него. Пара достоинств и 7 главных недостатков формата Pickle Согласно концепции MLOps, направленной на сокращение разрыва между различными специалистами,...
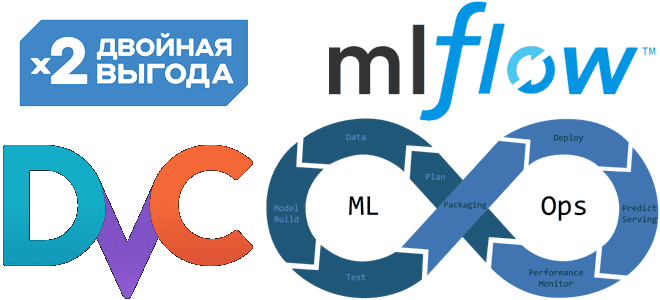
Продолжая разбираться с популярными MLOps-инструментами, сегодня рассмотрим, как MLflow реализует управление версиями модели и данных, а также чем это отличается от DVC. Преимущества и недостатки популярных MLOps-инструментов с возможностями их совместного использования. Плюсы и минусы MLflow для MLOps-инженера Концепция MLOps, направленная на сокращение разрыва между различными специалистами, участвующими в процессах...

Недавно мы писали, от каких факторов зависит выбор подходящего MLOps-инструмента. В продолжение этой темы сегодня специально для ML-инженеров разберем сходства и различия двух самых популярных MLOps-решений: что общего у MLflow и Kubeflow, чем они отличаются и в каких случаях выбирать тот или иной инструмент. Краткий обзор 2-х самых популярных MLOps-решений...
Чтобы сделать наши курсы для специалистов по Machine Learning еще более интересными, сегодня рассмотрим 5 лучших практик по использованию популярного MLOps-инструмента. Как Data Scientist может работать с MLflow и сделать свои конвейеры машинного обучения еще более эффективными. Компоненты Mlflow для разработки и развертывания ML-систем Сегодня MLOps считается одним из самых...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое Nebula Graph и как использовать мощные возможности обработки графов этой NoSQL-СУБД в сочетании с Apache Spark, одним из самых популярных механизмов анализа данных. Что такое Nebula Graph и как это работает Nebula Graph — это...
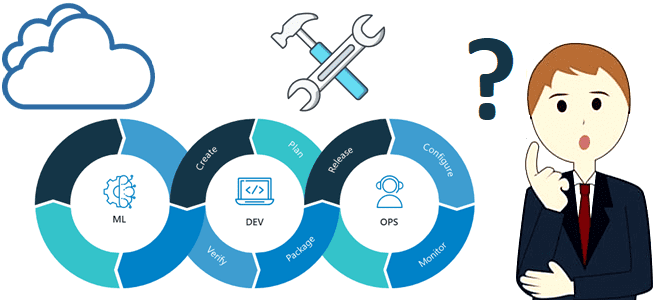
В этой статье для специалистов по Machine Learning рассмотрим, от каких факторов зависит выбор MLOps-средств и как сделать его наиболее верным способом. Когда развертывание продукта с открытым исходным кодом или индивидуального решения на собственной инфраструктуре лучше готового инструмента в облаке и почему часто бывает наоборот. 3 главных фактора выбора MLOps-решений...

В линейке продуктов Databricks не только облачная платформа аналитики больших данных на базе Apache Spark. В портфолио компании также присутствует популярный MLOps-инструмент под названием MLflow, последний релиз которого (1.27.0) вышел 1 июля 2022 года. Однако, разработчики уже анонсировали в мажорный выпуск новой версии MLOps-фреймворка с открытым исходным кодом. Читайте далее,...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем, как Airbnb использует графовые нейросети для улучшения машинного обучения. А также рассмотрим, как устроены GCN-нейросети и что определяет выбор между потоковым и пакетным ML-конвейером. Анализ графов для обогащения ML-моделей Многие проблемы машинного обучения могут быть...
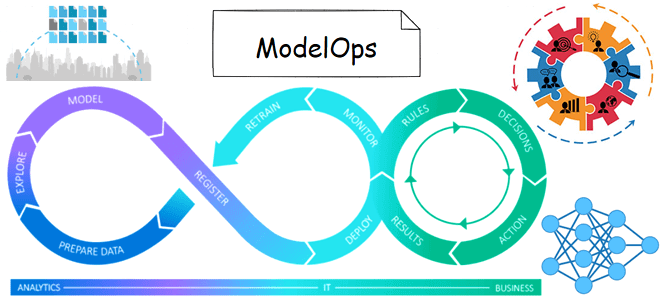
Пока инженеры данных и специалисты по Data Science привыкали к MLOps, начав понимать важность и необходимость этой концепции непрерывной разработки и эксплуатации систем машинного обучения, в Data Science появился новый термин с модным –Ops окончанием. Разбираемся, что такое ModelOps, чем это отличается от MLOps и как применить его на практике....
Чтобы добавить в наши курсы для дата-инженеров и специалистов по Machine Learning еще больше практических примеров, сегодня рассмотрим, как построить ETL-конвейер для преобразования речи в текст с использованием Apache Kafka, Airflow и Spark. А также познакомимся с популярными фреймворками и готовыми сервисами распознавания речи. ETL-конвейер распознавания речи: используемые технологии Предположим,...
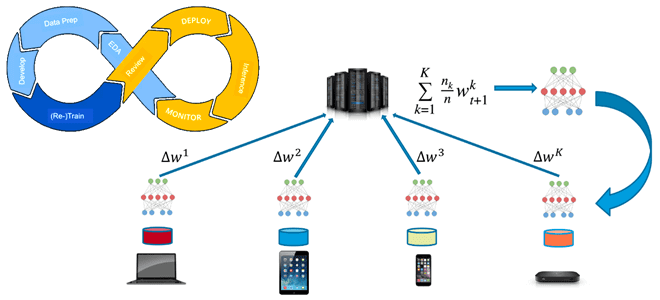
Сегодня в области Data Science именно машинное обучение является такой одновременно научной и прикладной сферой, где постоянно возникают новые прорывные идеи и технологии их реализации. Одной из самых популярных ML-тем сегодня считается федеративное машинное обучение. Что это такое и при чем здесь хайповый MLOps, читайте далее. Что такое федеративное машинное...

Сегодня разберемся, когда для Data Science-проектов вместо Apache Spark, самого популярного вычислительного движка аналитики больших данных, стоить выбрать Dask – легковесную Python-библиотеку для параллельных вычислений. И, наоборот, в каких случаях инженер данных и Data Scientist получают преимущества, выбирая Spark. Что такое Dask и зачем он нужен Data Scientist’у Прежде чем...
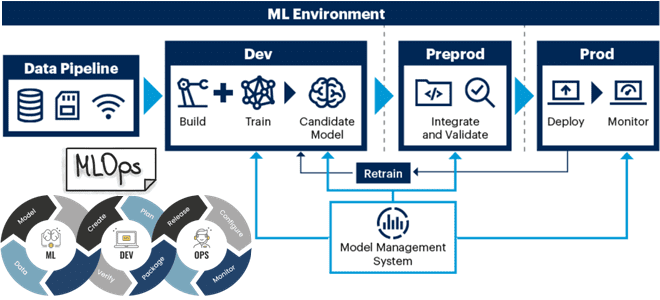
Что и насколько часто меняется в системах машинного обучения, почему необходимо отслеживать эти изменения и как MLOps помогает справиться с управлением ML-моделями, данными, кодом и инфраструктурой развертывания. Почему стек технологий MLOps такой разношерстный и какие инструменты выбирать для практического использования. MLOps для решения дрейфа данных и других проблем ML-систем Машинное...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...
Что не так с датасетами в системах машинного обучения, с какими трудностями сталкиваются аналитики, инженеры данных и специалисты по Data Science при внедрении MLOps, почему важна согласованность различных информационных хранилищ, зачем и как внедрять оперативный мониторинг за качеством данных. Разбираем трудности разработки и поддержки Machine Learning в production. 5 проблем...
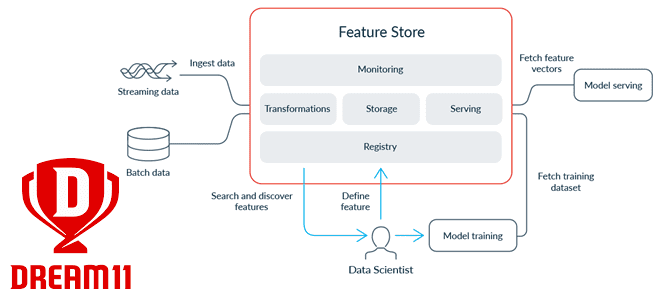
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...
Зачем нужен мониторинг ML-систем в production, чем он отличается от простого отслеживания метрик ПО и при чем здесь MLOps. Как настроить телеметрию ML-приложений в New Relic: 5 простых шагов для специалистов по Machine Learning и дата-инженеров. Зачем нужен мониторинг ML-систем и при чем здесь MLOps В реальных системах машинного обучения...
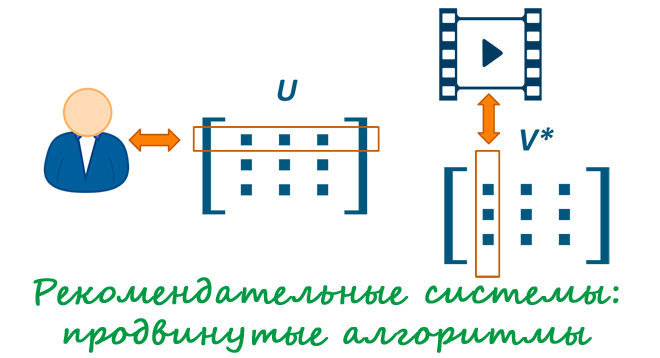
В прошлой статье мы разобрали методы построения рекомендательных систем: коллаборативная фильтрация; фильтрация на контенте; фильтрация на знаниях; гибридный подход. Мы намеренно не упомянули об одном важном подходе построения рекомендаций: об использовании матричных разложений. Описание данного метода заслуживает отдельной статьи! Будем эксплуатировать традиционный для рекомендательных систем кейс рекомендации фильмов пользователям. Напомним,...
Что такое непрерывное машинное обучение, как оно работает и при чем здесь MLOps. Почему сложно вести разработку ML-моделей в стиле CI/CD и как CML помогает обойти эти ограничения. Автоматизация процессов непрерывной интеграции и доставки с помощью open-source CLI-инструмента от Iterative.ai. Трудности CI/CD в Machine Learning и MLOps Поддерживаемые DevOps-концепцией идеи...