Сегодня рассмотрим пример построения интеллектуальными конвейера потоковой обработки видео с Apache Kafka и алгоритмами машинного обучения. Читайте далее, зачем для этого нужен протокол RTSP, что такое библиотека Sarama и как интегрировать алгоритмы машинного/глубокого обучения в систему видеоаналитики реального времени. Потоковая видеоаналитика: прием мультимедиа в реальном времени Видеоаналитика – одно из...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Продвигая наши курсы для разработчиков Spark с примерами реальных систем аналитики больших данных, сегодня рассмотрим библиотеку для чтения файлов формата DICOM от индийской компании Abzooba. Читайте далее, как автоматизировать поиск по миллиардам медицинских изображений с помощью машинного обучения и технологий Big Data: Apache Spark, Hadoop, Kafka, Elasticsearch и Kibana. Что...

Вчера мы опровергали мифы о превосходстве молодого Apache Pulsar над зрелой Kafka, наглядно показав, что именно второй Big Data фреймворк больше подходит для построения по-настоящему масштабных и высоконадежных распределенных масштабируемых систем потоковой аналитики больших данных. Тем не менее, благодаря своим архитектурным особенностям Pulsar постепенно завоевывает собственную нишу и становится все...

Отвечая на вопрос, что такое большие данные для чайников, сегодня мы рассмотрим 3 практических примера использования технологий Big Data в малом и среднем бизнесе. Никакой Rocket Science, только понятные кейсы, которые актуальны для любой современной компании, даже если она состоит из пары человек: аналитика больших данных и машинное обучение для...
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
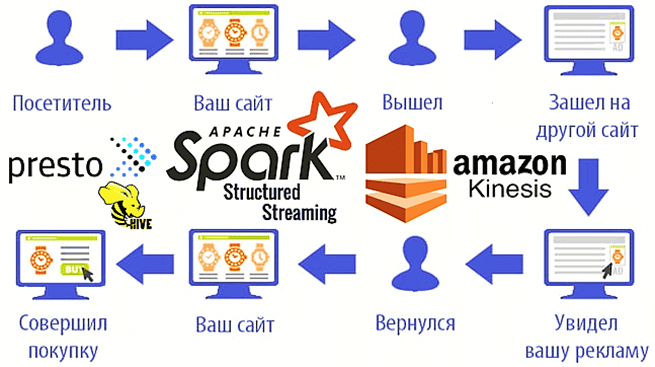
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

Обучение Apache Spark, Kafka, Hadoop и прочим технологиям Big Data – это не только курсы, теоретические статьи и практические задания, но и проверка полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по основам Спарк для начинающих. Проверьте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...
Сегодня поговорим про особенности построения конвейеров машинного обучения в Apache Spark. Читайте далее, как Spark MLLib реализует идеи MLOps, что такое трансформеры и оценщики, из чего еще состоит Machine Learning pipeline, как он работает с кодом на Scala, Java, Python и R, а также каковы условия практического использования методов fit(),...
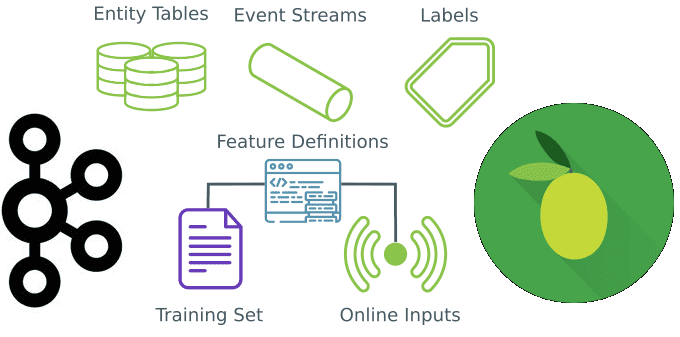
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...

Обработка данных является одной из самых первоочередных задач анализа Big Data. Сегодня мы расскажем о самых полезных преобразованиях PySpark, которые можно выполнить над столбцами. Читайте далее, как привести значения к 0 или 1, как преобразовать из строк в числа и обратно, а также как обработать недостающие значения(Nan) с примерами в...

Продолжаем говорить о NLP в PySpark. После того как тексты обработаны: удалены стоп-слова и проведена лемматизация — их следует векторизовать для последующей передачи алгоритмам Machine Learning. Сегодня мы расскажем о 3-x методах векторизации текстов в PySpark. Читайте в этой статье: применение CountVectorizer для подсчета встречаемости слов, уточнение важности слов с...
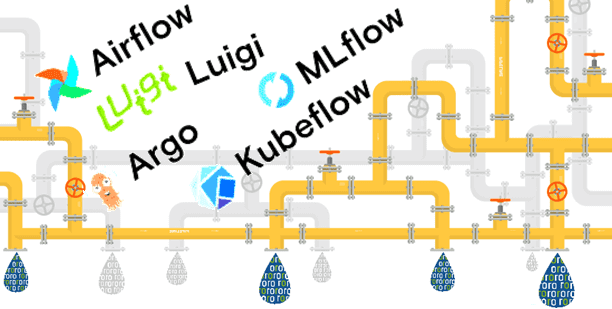
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

В этой статье мы рассмотрим комплексный конвейер (pipeline) обработки больших данных с помощью алгоритмов машинного обучения (Machine Learning) для системы речевого анализа Callinter от китайской компании Fano Labs. Apache Kafka играет ключевую роль в этом аналитическом конвейере, ежедневно обеспечивая бесперебойную стабильность и высокую производительность интеллектуальной обработки нескольких тысяч часов звонков....
В прошлый раз мы говорили о методах NLP в PySpark. Сегодня рассмотрим методы нормализации и стандартизации данных модуля ML библиотеки PySpark. Читайте в нашей статье: применение Normalizer, StandardScaler, MinMaxScaler и MaxAbsScaler для нормализация и стандартизации данных. Нормализация и стандартизация — методы шкалирования данных Нормализация (normalization) и стандартизация (standardization) являются методами...