
В продолжение темы про предупреждение и раскрытие преступлений с помощью ИТ, сегодня мы расскажем, что такое антифрод-системы, зачем они нужны и где используются. А также рассмотрим, какова роль технологий Big Data и Machine Learning в таких средствах обнаружения мошенничества. Читайте в нашей статье, почему как большие данные и машинное обучение...

В этой статье мы продолжим рассматривать примеры использования технологий Big Data и Machine Learning в задачах профилактики и расследовании преступлений. Сегодня читайте, как машинное обучение и большие данные позволяют предупредить массовые убийства и выявить закладки наркотиков с помощью методов графовой аналитики и автоматической оценки сообщений в соцсетях. Machine Learning против...

Цифровизация и искусственный интеллект повышают эффективность не только коммерческого бизнеса, промышленных производств и государственных услуг. В этой статье мы расскажем, как технологии больших данных (Big Data) и машинное обучение (Machine Learning) борются с незаконным оборотом наркотиков. Читайте в сегодняшнем материале 3 примера практического использования науки о данных (Data Science) в...

Сегодня мы расскажем про интерактивные карты преступности в России и за рубежом, а также рассмотрим, как технологии больших данных (Big Data) и машинного обучения (Machine Learning) помогают обнаружить и предупредить городские преступления. Читайте в этой статье, что такое Crime Mapping, где уже запущены биометрические системы идентификации подозреваемых и как дроны...

Ранее мы рассказывали, что общего между бережливым производством и DevOps. Сегодня рассмотрим, как 7 принципов Lean отражены в разработке программного обеспечения. Также читайте в нашей статье об актуальности методологии ITIL для проектов цифровизации и внедрения технологий больших данных (Big Data). 7 принципов Lean в ИТ Мы уже упоминали, что впервые...
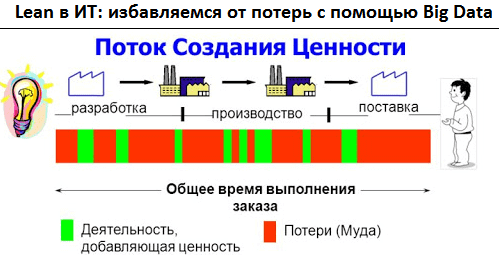
Продолжая разговор про бережливое производство в ИТ, сегодня мы рассмотрим виды потерь и источники их возникновения, а также поговорим, как принципы Lean помогают бизнесу избавиться от муда, мури и мура средствами больших данных (Big Data). 8 видов потерь в Lean с примерами из ИТ Прежде всего, поясним значение понятий муда,...
Сегодня мы рассмотрим, что такое расширенная аналитика и дополненное управление данными, как они связаны с цифровизацией бизнеса и почему исследовательское бюро Gartner включило эти технологии в ТОП-10 самых перспективных трендов 2020 года. Читайте в нашей статье, как машинное обучение (Machine Learning) помогает аналитикам и руководителям находить во множестве больших данных...
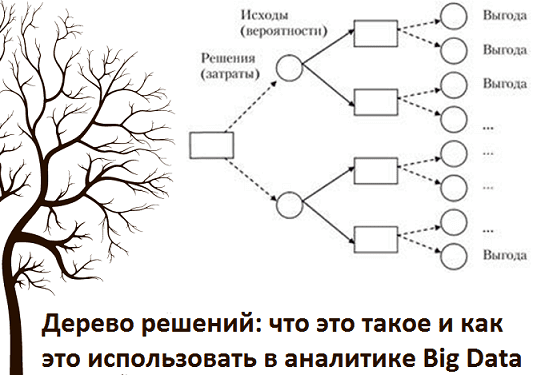
Продолжая насыщать курс Аналитика больших данных для руководителей важными понятиями системного анализа, сегодня мы рассмотрим, что такое дерево решений (Decision Tree). А также расскажем, как этот метод Data Mining и предиктивной аналитики используется в машинном обучении, экономике, менеджменте, бизнес-анализе и аналитике больших данных. Как растут деревья решений: базовые основы Начнем...

11 марта 2020 года ВОЗ объявила о пандемии нового коронавируса (Covid-19), который в декабре 2019 был впервые обнаружен в китайском мегаполисе Ухань. С тех пор вирус стремительно распространяется по всей планете, вызывая острые респираторные заболевания. Сегодня мы расскажем, почему, несмотря на повсеместные карантины и обвал мировых рынков, все не все...

В честь Международного женского дня, 8 марта, мы собрали для вас 15 интересных кейсов о том, как большие данные (Big Data) и машинное обучение (Machine Learning, ML) используются в индустрии моды и красоты. Читайте в нашей сегодняшней статье как Zara, H&M, Burberry и другие fashion-гиганты внедряют умные примерочные, виртуальных стилистов,...

Продолжая тему прикладного использования искусственного интеллекта в различных бизнес-кейсах, сегодня мы расскажем о том, как устроены чат-боты, при чем здесь большие данные (Big Data) и машинное обучение (Machine Learning), системы распознавания речи и понимания естественного языка. Какие бывают чат-боты Все многообразие чат-ботов можно разделить на 2 большие категории [1]: работающие...

Вчера мы рассказывали о рынке чат-ботов, голосовых помощников и виртуальных ассистентов на базе больших данных (Big Data) и машинного обучения (Machine Learning) . Напомним, на 2020 год они признаны аналитическим бюро Gartner одной из самых перспективных и наиболее эффективных технологий искусственного интеллекта. Сегодня поговорим о том, где именно они используются...

В этой статье мы представим для вас краткий обзор рынка чат-ботов и голосовых помощников. А также расскажем, где используются эти решения на базе технологий больших данных (Big Data) и машинного обучения (Machine Learning) и чего ждать от них в будущем. Чат-боты в России и за рубежом: обзор рынка Прежде всего,...
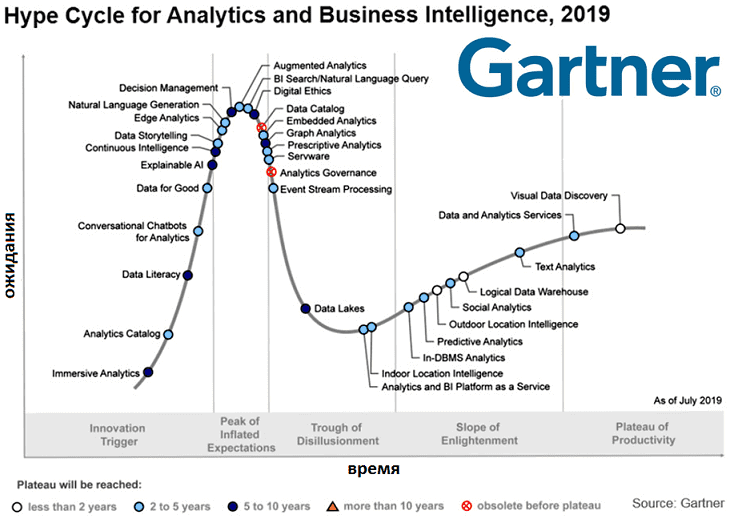
Сегодня мы поговорим, что такое Hype Cycle от самого известного аналитического агентства Gartner и как будут развиваться наиболее популярные сегодня ИТ-тренды в области больших данных (Big Data), управления данными (Data Management), машинного обучения (Machine Learning) и искусственного интеллекта (Artificial Intelligence). Что такое цикл зрелости технологий – Hype Cycle от Gartner...

В продолжение темы, от чего большие данные, машинное обучение и другие методы искусственного интеллекта смогут защитить человечество, сегодня мы поговорим, почему эти технологии не заменят человека везде и полностью. В этой статье мы собрали доводы против абсолютной автоматизации принятия управленческих решений с помощью Big Data и Machine Learning. Когда Big...

К 23 февраля мы собрали для вас 5 кейсов, где выступать в роли защитника будет искусственный интеллект. Смертельные болезни, внешние угрозы, преступники, экологические проблемы и чрезмерные траты ресурсов – читайте в нашей сегодняшней статье, как цифровизация на базе больших данных (Big Data) и машинного обучения (Machine Learning, ML) защитит нас...

Чтобы повысить мотивацию студентов к обучению, преподаватели активно применяют различные подходы к организации образовательного процесса, в т.ч. используемые в HR. Сегодня мы покажем, как, по аналогии с управлением человеческими ресурсами, аналитика больших данных (Big Data) и методы машинного обучения (Machine Learning) помогают увеличить вовлеченность учеников и улучшить качество образования. От...
Вчера мы рассматривали, как аналитика больших данных (Big Data) и машинного обучения (Machine Learning) помогают снизить текучесть кадров и предупредить увольнение ключевых сотрудников. Сегодня поговорим о том, как эти технологии позволяют выявить главные компетенции успешного сотрудника, обнаружить неявную зависимость прибыли компании от вовлеченности персонала, а также получить другие полезные HR-инсайты....

Продолжая разговор про цифровизацию HR-процессов, сегодня мы рассмотрим, как технологии больших данных (Big Data) и машинного обучения (Machine Learning) помогают сократить текучку кадров и удержать ключевых работников. Читайте в нашей новой статье 5 успешных примеров применения аналитики Big Data в HR для принятия эффективных управленческих решений. Big Data и Machine...

Мы уже рассказывали про цифровизацию HR-процессов на примере IBM и еще других компаний, в которых активно применяются технологии больших данных (Big Data) и машинного обучения (Machine Learning) для оптимизации управления людьми. В этой статье мы собрали еще 5 интересных кейсов по использованию аналитики Big Data в рекрутинге. Big Data и...