В прошлый раз мы говорили о методах NLP в PySpark. Сегодня рассмотрим методы нормализации и стандартизации данных модуля ML библиотеки PySpark. Читайте в нашей статье: применение Normalizer, StandardScaler, MinMaxScaler и MaxAbsScaler для нормализация и стандартизации данных. Нормализация и стандартизация — методы шкалирования данных Нормализация (normalization) и стандартизация (standardization) являются методами...
Продолжая разговор про инженерию больших данных, сегодня рассмотрим, как построить ETL-pipeline на открытых технологиях Big Data. Читайте далее про получение, агрегацию, фильтрацию, маршрутизацию и обработку потоковых данных с помощью Apache NiFi, Kafka и Spark, преобразование JSON, а также обогащение и сохранение данных в Hive, HDFS и Amazon S3. Пример потокового...
Однажды мы уже рассказывали про StreamSets Data Collector, сравнивая его с Apache NiFi. Сегодня рассмотрим, как устроен этот исполнительный движок для запуска конвейеров обработки больших данных, каким образом он связан с Apache Spark и чем полезен инженеру Big Data при организации ETL-процессов на локальных и облачных озерах данных (Data Lake,...
Продолжая разговор про практическое применение Apache Kafka на примере организации рекомендательной системы Twitter, сегодня мы рассмотрим, как с помощью Kafka Streams был разработан конвейер сбора и агрегации данных для машинного обучения (Machine Learning). Читайте в нашей статье про особенности объединения больших данных через LeftJoin и InnerJoin в Apache Kafka Streams. Архитектура приложения...
Недавно мы рассказывали про преимущества event-streaming архитектуры с помощью Apache Kafka на примере The New York Times. В продолжение этой темы Apache Kafka, сегодня поговорим про использование этой Big Data платформы в Twitter для построения конвейера потоковой регистрации событий в рекомендательной системе на базе алгоритмов машинного обучения (Machine Learning). Как...
В прошлый раз мы говорили о решении задачи классификации в рамках Machine Learning с помощью PySpark MLlib. Сегодня рассмотрим задачу регрессии. Читайте далее: что такое линейная регрессия, L1 и L2 регуляризация, алгоритм подбора значений гиперпараметров Grid Search, а также применение кросс-валидации в PySpark. Датасет с домами на продажу Обучать модель...

PySpark позволяет работать не только с большими данными (Big data), но и создавать модели машинного обучения (Machine Learning). Сегодня мы расскажем вам о модуле ML и покажем, как обучить модель Machine Learning для решения задачи классификации. Читайте у нас: подготовка данных, применение логистической регрессии, а также использование метрик качеств в...
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...
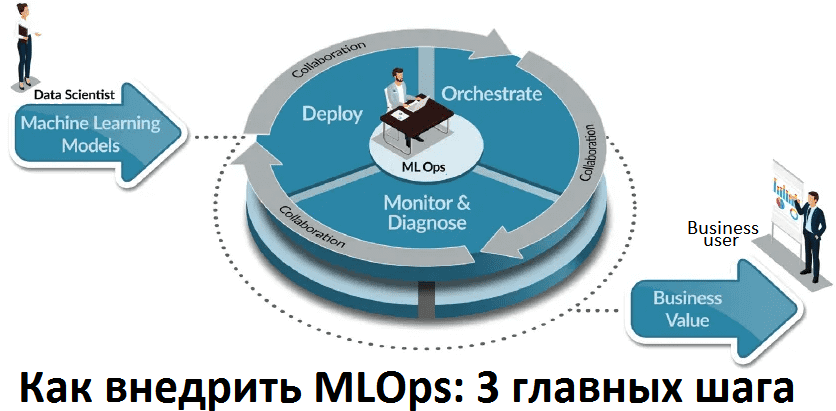
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...
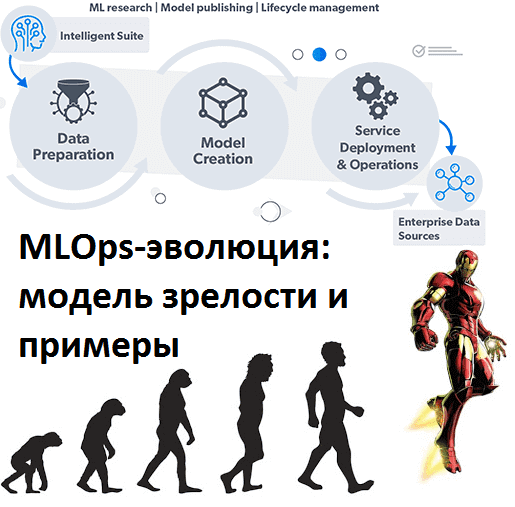
Цифровизация и запуск проектов Big Data предполагают некоторый уровень управленческой зрелости бизнеса, который обычно оценивается по модели CMMI. MLOps также требует предварительной готовности предприятия к базовым ценностям этой концепции. Читайте в нашей статье, что такое Machine Learning Operations Maturity Model – модель зрелости операций разработки и эксплуатации машинного обучения, из...
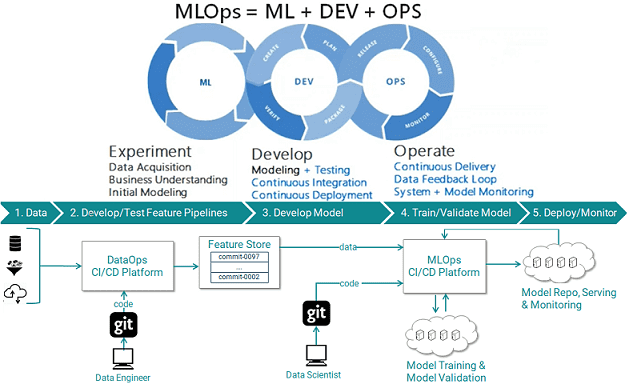
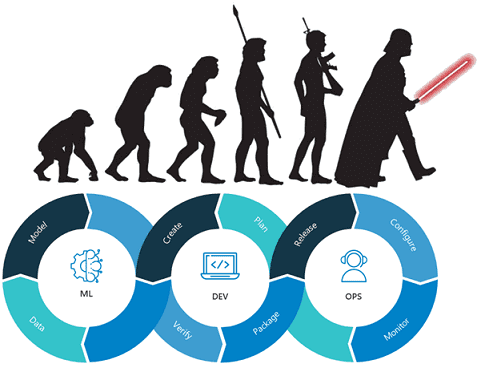
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...
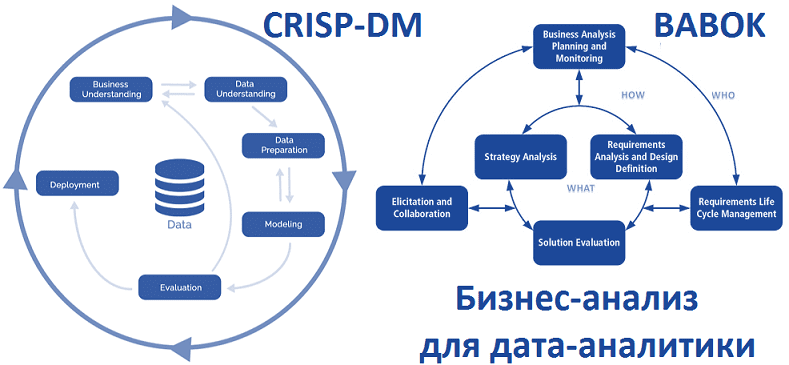
Мы уже рассказывали, что цифровизация и другие масштабные проекты внедрения технологий Big Data должны обязательно сопровождаться процедурами бизнес-анализа, начиная от выявления требований на старте до оценки эффективности уже эксплуатируемого решения. Сегодня рассмотрим, как задачи бизнес-анализа из руководства BABOK®Guide коррелируют с этапами методологии исследования данных CRISP-DM, которая считается стандартом де-факто в...

Аналитика больших данных (Big Data) сегодня нужна всем компаниям, но далеко не каждое предприятия готово инвестировать в сложную ИТ-инфраструктуру и дорогих специалистов. Избежать этих затрат, получив все преимущества практического использования технологий Data Science, поможет парадигма «данные как сервис». В продолжение темы по цифровизации, сегодня поговорим про концепцию Data as a...

Вчера мы говорили о том, какие организационные барьеры мешают реализации запланированных проектов национальной программы «Цифровая экономика РФ». Сегодня рассмотрим основные этические риски, которые сдерживают развитие цифровой трансформации в России и разберем некоторые возможности их обхода. Чем страшна цифровизация: 7 ключевых проблем с точки зрения этики 16 января 2020 года Центр...

В этой статье рассмотрим, как технологии Industry 4.0 помогают российскому нефтехимическому холдингу СИБУР повысить операционную эффективность производства и обеспечить безопасность труда. Сегодня мы собрали для вас 5 примеров практического использования различных методов и инструментов Big Data, Machine Learning, Industrial Internet of Things (IIoT), а также XR (AR+VR). Зачем нефтехимикам технологии...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...
Продолжая разбирать production-кейсы реального использования этих технологий Big Data, сегодня поговорим подробнее, каковы плюсы совместного применения Kudu, Spark Streaming, Kafka и Cloudera Impala на примере аналитической платформы для мониторинга событий информационной безопасности банка «Открытие». Также читайте в нашей статье про возможности этих технологий в контексте машинного обучения (Machine Learning), в...
Продолжая разговор про расширенную аналитику больших данных с помощью инструментов Big Data и методов Data Science, сегодня рассмотрим, что такое самообслуживаемое машинное обучение, а также разберем, чем self-service Machine Learning отличается от AutoML. Что такое самообслуживаемое машинное обучение В июне 2020 года аналитическое агентство Gartner опубликовало очередной список самых перспективных...

Аналитика больших данных для руководителей и других конечных бизнес-пользователей – это не только графические дэшборды BI-систем. Сегодня рассмотрим, что такое самообслуживаемая аналитика Big Data, какова ее польза для бизнеса и чего не стоит ждать от self-service BI. Что такое self-service BI: определение, назначение и примеры Еще в 2018 году исследовательское...