
В этой статье мы разберем одно из ключевых понятий цифровизации: что такое предиктивная аналитика и чем она отличается от дескриптивной. Также рассмотрим на практических примерах, какие виды аналитики больших данных (Big Data) еще бывают и где они используются. Читайте в нашем сегодняшнем материале, как машинное обучение (Machine Learning) и другая...

Сегодня рассмотрим, чем корпоративное обучение большим данным (Big Data) отличается от индивидуального. Читайте в нашей статье, почему образовательные курсы по Apache Kafka, Hadoop, Spark и другим технологиям Big Data сплотят ваших сотрудников лучше любого тимбилдинга и как повысить эффективность такого обучающего тренинга. Почему корпоративное обучение Big Data эффективнее индивидуальных курсов:...

Цифровизация не всегда приносит только положительные результаты: увеличение прибыли, сокращение расходов и прочие бонусы оптимизации бизнеса. Большие данные – это большая ответственность, с которой справится не каждый. В этой статье мы собрали 5 самых ярких событий ИТ-мира за последнюю пару лет, связанных с большими данными (Big Data) и машинным обучением...

Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...

Сравнив между собой наиболее популярные методы биометрии, сегодня мы подробнее рассмотрим, насколько они устойчивы к фальсификациям. Читайте в этой статье, как хакеры обманывают сканер отпечатков пальцев, путают Big Data системы уличной видеоаналитики и выдают себя за другое лицо с помощью модной технологии машинного обучения (Machine Learning) под названием Deep Fake....
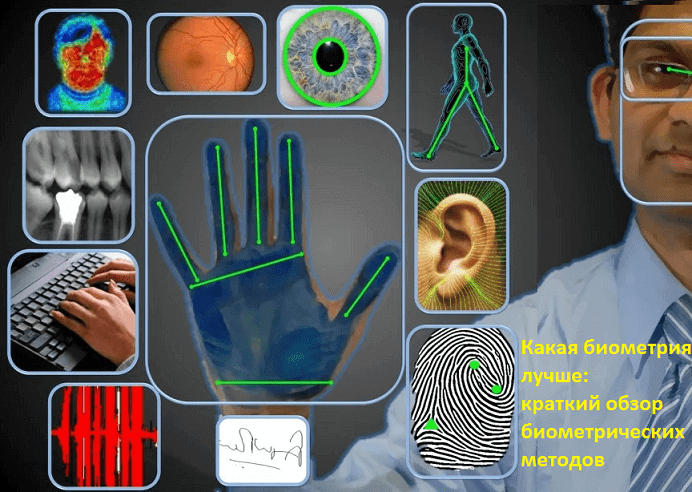
Продолжая рассматривать уязвимости биометрических систем, сегодня мы поговорим про отличия разных методов биометрии. Проанализируем быстроту их работы и устойчивость к фальсификации, а также используемые технологии Big Data и Machine Learning. Кроме того, сравним ставшие привычными способы идентификации личности по фотографии лица, снимкам глаз, отпечаткам пальцев и ладоней с более «экзотическими»...

В прошлой статье мы рассказывали о самых крупных утечках данных из биометрических Big Data систем в России и за рубежом. Сегодня рассмотрим характерные уязвимости биометрии: естественные ограничения методов идентификации личности с помощью машинного обучения (Machine Learning, ML) и целенаправленные атаки. 2 главные уязвимости биометрических Big Data систем на базе Machine...

Мы уже рассказывали, как машинное обучение применяется для прогнозирования будущих событий в финансовом секторе, нефтегазовой промышленности, логистике, HR-менеджменте, девелопменте, страховании, муниципальном управлении, маркетинге, ритейле и других отраслях экономики. Сегодня рассмотрим еще несколько практических примеров такого приложения Machine Learning и в этом контексте разберем одно из ключевых понятий Data Science по...

Продолжая тему Cybersecurity, сегодня мы поговорим про биометрические системы: что это такое, как они работают и чем нарушают требования GDPR и № 152-ФЗ. Также в этом материале мы собрали для вас примеры таких наиболее известных проектов на базе технологий Big Data и Machine Learning. Что такое биометрические персональные данные и...
Рассказав о том, как машинное обучение работает в разных задачах cybersecurity, сегодня мы собрали для вас 5 примеров реального использования Machine Learning в информационной безопасности. Также в этой статье мы рассмотрим, способны ли эти методы искусственного интеллекта заменить существующие инструменты защиты данных и почему. Где и как машинное обучение используется...

Сегодня мы расскажем, как машинное обучение (Machine Learning, ML) используется в информационной безопасности для защиты данных от утечек, несанкционированного доступа, неправомерного использования пользовательских привилегий, вирусных атак и прочих угроз cybersecurity. Читайте в нашей статье, как нейросети и другие ML-модели выявляют мошеннические операции и другие аномалии в Big Data системах и...

Продолжая разговор о том, что такое цифровой двойник и где эта технология Industry 4.0 используется на практике, сегодня мы рассмотрим несколько реальных примеров такой цифровизации в отечественной и зарубежной промышленности. Читайте в нашей статье про практическую синергию технологий Big Data, ML, PLM и IIoT в нефтегазовой, теплоэнергетической и машиностроительной отраслях....

В этой статье мы разберем, что такое цифровой двойник – один из главных трендов развития 4-ой промышленной революции (Industry 4.0) на ближайшие 5 лет. Читайте в сегодняшнем материале, зачем нужен виртуальный макет завода, из чего состоит информационная модель изделия и где используются цифровые двойники. Также рассмотрим, как CALS- и PLM-технологии...

Сегодня мы расскажем, почему и зачем сейчас почти все сайты собирают cookies, что такое GDPR, как банки собираются оценивать кредитоспособность потенциального заемщика по истории его запросов в браузере и насколько это легально. Читайте в нашей статье про персональные данные, синергетический эффект технологий Big Data и финансовый скоринг на основе пользовательского...

На пороге 3-го десятилетия 21 века пришло время подвести итог прошедшим годам и cделать прогнозы на будущее. В этой статье мы поговорим о ключевых событиях минувших лет, помечтаем о том, что ждет Big Data и чего нам принесет эта ИТ-область. Также поделимся с вами своими планами на 2020 год: расскажем...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...
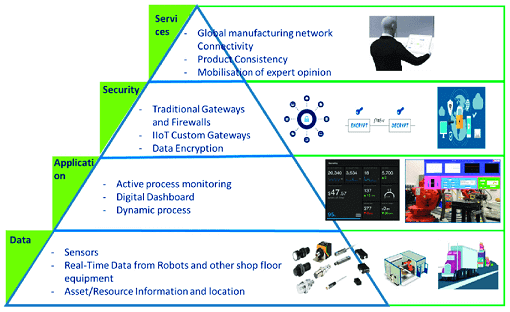
Мы уже рассматривали типовую архитектуру систем Internet of Things (IoT). Сегодня поговорим подробнее про уровневую модель передачи и обработки данных от конечных устройств до облачных IoT-платформ, а также приведем примеры наиболее популярных средств обеспечения каждого из уровней этой сложной архитектуры Industrial Internet of Things, включая инструменты Big Data. Многоуровневый IIoT:...
Продолжая разговор про мировые тренды развития промышленного интернета вещей (Industrial Internet of Things, IIoT), сегодня мы рассмотрим перспективы отечественного IIoT, а также проанализируем текущее развитие Big Data, Machine Learning и других ключевых технологий 4-ой промышленной революции (Industry 4.0, I4.0) в России. Промышленный интернет вещей в России: 3 главные перспективы Прежде...

В этой статье мы расскажем о 4-ой промышленной революции и прорывных технологиях, показанных на крупнейшей промышленной выставке Hannover Messe-2019: что такое коботы, цифровые близнецы и CMMS-системы, а также как все это связано с Big Data и Industrial Internet of Things. 4-я промышленная революция: что это такое и как она связана...