
Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...
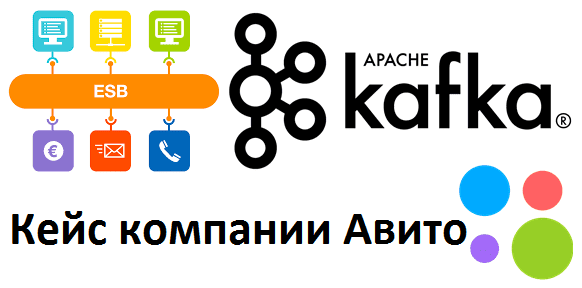
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru. Что такое ESB и чем это отличается от брокера сообщений...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

Вчера мы рассказывали про самые известные утечки Big Data с открытых серверов Elasticsearch (ES). Сегодня рассмотрим, как предупредить подобные инциденты и надежно защитить свои большие данные. Читайте в нашей статье про основные security-функции ELK-стека: какую безопасность они обеспечивают и в чем здесь подвох. Несколько cybersecurity-решений для ES под разными лицензиями...
Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах...
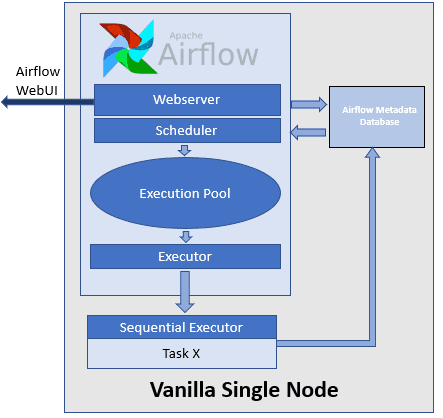
Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их...
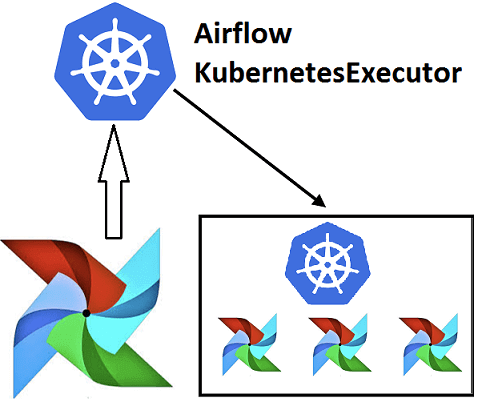
Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня...

Вчера мы рассказали, почему запускать Airflow на Kubernetes – это эффективно и выгодно для всех участников batch-процессов с большими данными (Big Data): разработчиков Data Flow, Data Scientist’ов, аналитиков и инженеров. Сегодня рассмотрим, что такое Airflow Kubernetes Operator и чем он отличается от подобной разработки компании Google. Как работает AirFlow Kubernetes...

Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически....
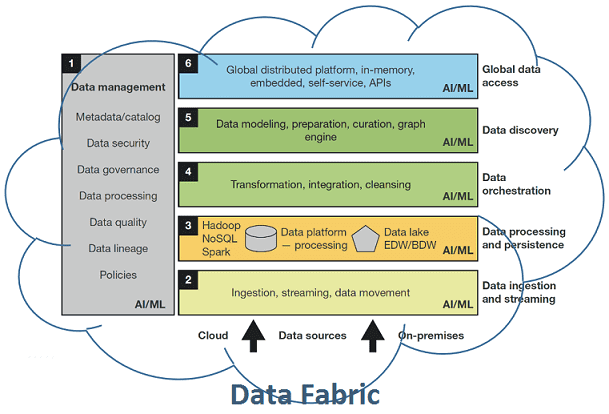
Сегодня мы рассмотрим, что такое Data Fabric, почему этот тренд в аналитике больших данных (Big Data) считается одним из самых перспективных в 2020 году, зачем нужна фабрика данных и как она устроена. Читайте в нашей статье, чем Data Fabric отличается от Data Factory, причем тут цифровизация, DataOps и конвейеры по...

Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России - ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big...
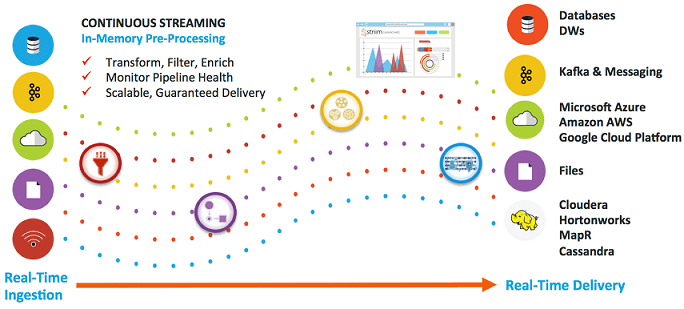
Рассмотрев пакетные ETL-инструменты больших данных, сегодня мы поговорим про потоковые средства загрузки и маршрутизации информации из различных источников: Apache NiFi, Fluentd и StreamSets Data Collector. Читайте в нашей статье про их сходства, различия, достоинства и недостатки. Также мы собрали для вас реальные примеры их практического использования в Big Data системах...

Для высоконагруженных Big Data систем и платформ интернета вещей (Internet of Things, IoT) с непрерывными информационными потоками Apache Kafka, практически, стала стандартом де факто для обмена сообщениями и управления очередями. Аналогичную популярность среди DevOps-инструментов завоевал Kubernetes (K8s) как наиболее мощное средство для автоматизации развертывания и управления контейнеризованными приложениями. В этой...

Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений. Как работает Apache Kafka Apache Kafka позволяет в режиме онлайн обеспечить сбор и...

Проанализировав самые критичные уязвимости Kubernetes за последние 2 года и ключевые факторы их возникновения, сегодня мы поговорим, как DevOps-инженеру и администратору обеспечить информационную безопасность в контейнерах Kubernetes для их эффективного применения в Big Data системах. Лучшие практики cybersecurity для Kubernetes Комплексную безопасность кластера Kubernetes и больших данных, которые там хранятся...

Мы уже рассказывали про самые критичные уязвимости Kubernetes за последние 2 года. Продолжая тему информационной безопасности в контейнерах Big Data систем, сегодня мы поговорим, почему популярнейшая DevOps-технология так чувствительна к хакерским атакам. Читайте в нашей статье об основных факторах нарушения cybersecurity в DevOps-инфраструктуре на примере Kubernetes и Docker. Основные векторы...
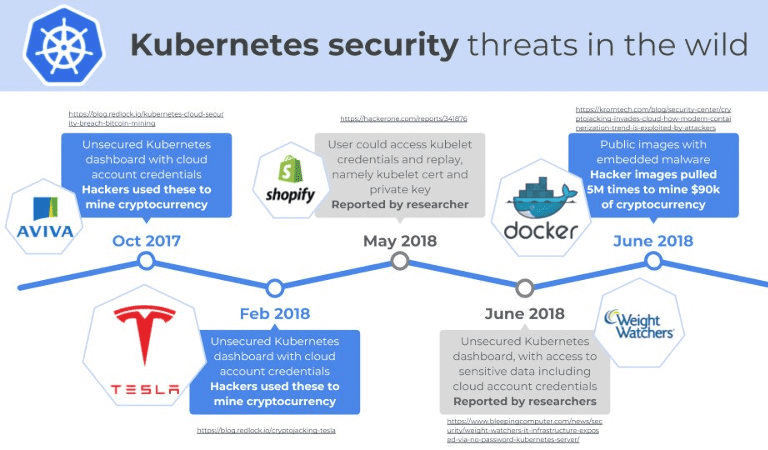
В продолжении темы контейнеризации приложений и применения этой технологии в Big Data системах, сегодня мы поговорим, действительно она абсолютно безопасна. А также насколько популярнейшая DevOps-технология, Kubernetes, «великий кормчий» среди систем оркестрации контейнеров, соответствует своему визуальному образу «неуязвимого» океанического лайнера. Спойлер: на самом деле нет, K8s, как и любые другие технологии...

Мы уже рассказывали про достоинства и недостатки самой популярной DevOps-технологии 2019 года – платформы управления контейнерами Kubernetes для Big Data систем. Сегодня поговорим, зачем вообще нужны контейнеры, чем они отличаются от виртуальных машин, каковы их плюсы и минусы, а также для чего нужна их оркестрация. Что такое контейнеризация приложений и...

Сегодня, когда ИТ-компании распиливают монолиты своих Big Data систем на микросервисы, а DevOps-подход совершает свое победное шествие по локальным и облачным кластерам, Kubernetes стал, пожалуй, самой востребованной технологией 2019 года. Однако, K8s нужен далеко не каждому проекту. В этой статье мы поговорим о достоинствах и недостатках кубернетис, в каких случаях...
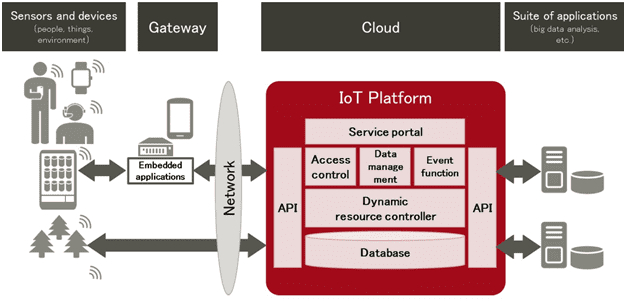
Рассматривая архитектуру и принципы работы IoT-систем, мы уже упоминали, что наиболее интеллектуальная часть работы по анализу данных выполняется в облаке с помощью специальных средств Big Data, объединенных в общую платформу. Сегодня поговорим о функциях IoT-платформ и технологиях, на которых основаны эти облачные решения. Также мы подготовили для вас краткий обзор...