
В этой статье для обучения ИТ-архитекторов и дата-инженеров сравним 2 подхода к аналитике больших данных, чтобы решить, когда потоковые вычисления, например, средствами ksqlDB в рамках Apache Kafka лучше аналитических баз данных реального времени, таких как Rockset, и наоборот. 2 способа выполнения аналитики больших данных в реальном времени Современный бизнес и...

Сегодня заглянем под капот Apache Kafka и рассмотрим, как на программном уровне работает упаковка сообщений от приложения-продюсера в пакеты перед их отправкой в топик платформы. Что такое RecordAccumulator, какие конфигурации с ним связаны и почему такое пакетирование обеспечивает эффективность потоковой обработки данных. Как устроено пакетирование потоковой обработки в Apache Kafka...
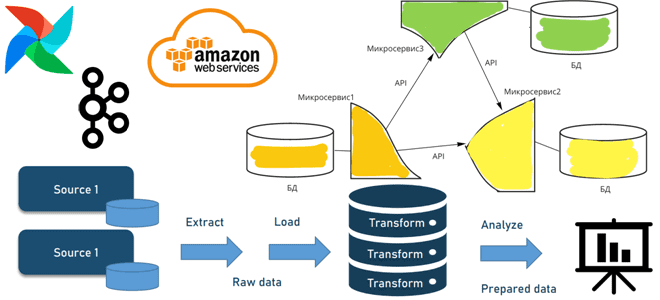
Когда и зачем переходить от пакетной парадигмы обработки к потоковой, как это сделать с помощью микросервисной архитектуры, какие проблемы могут при этом возникнуть и что за решения позволят их избежать. А в качестве примеров инструментальных средств рассмотрим сервисы AWS, Apache AirFlow и Kafka. От пакетов к потокам через микросервисы: архитектура...

Визуализация конвейеров обработки данных особенно важна в потоковой парадигме, поэтому мы часто рассматриваем полезные средства мониторинга для Apache Kafka. Сегодня разберем, что такое Streams Explorer от Bakdata и как это пригодится для дата-инженера. Проекты Bakdata для развертывания и мониторинга приложений Kafka Streams При работе с крупномасштабными потоковыми данными крайне важно...
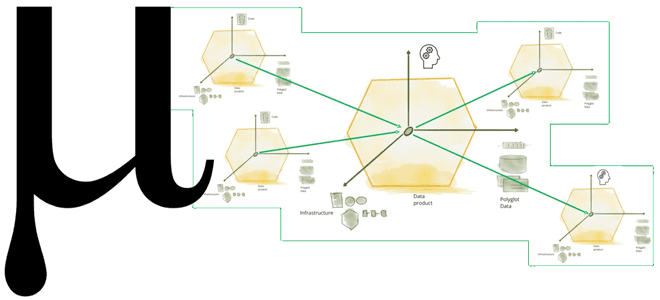
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь...

В этой статье для обучения дата-инженеров и администраторов кластера Apache Kafka разберем, какие ошибки создают медленные потребители и как решить их, просто изменив значений конфигураций по умолчанию. А также познакомимся с Lighthouse - еще одним полезным инструментом мониторинга системных метрик, который позволит обнаружить эти и другие проблемы. Проблема медленных потребителей...

Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka. Источники данных в Apache Flink Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки...
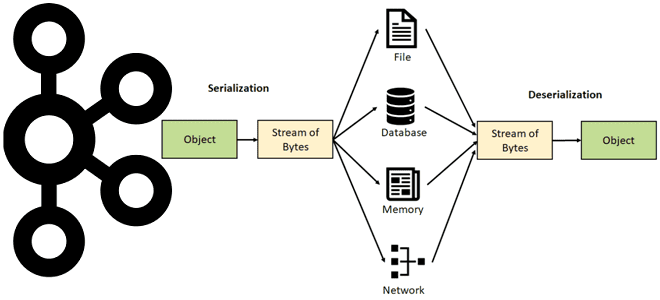
Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения. Сериализация и десериализация данных в Apache Kafka Выполняя роль интеграционной платформы, Apache...
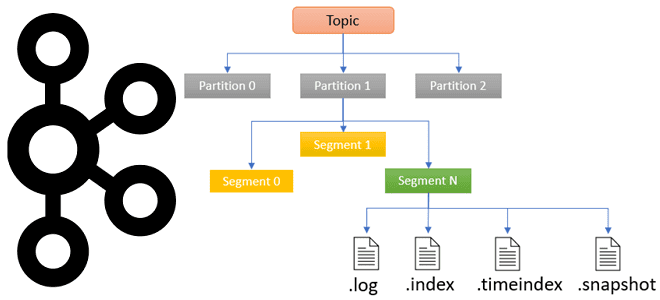
Чтобы сделать наши практические курсы по Apache Kafka еще более полезными, сегодня рассмотрим, в каких файлах хранятся сообщения, смещения и состояния продюсера, а также функции работы с ними для потоковой передачи событий. Средства обработки и хранения данных в Apache Kafka Прежде, чем погружаться в тонкости хранения данных в Apache Kafka,...

Сегодня рассмотрим, как дата-инженеры маркетплейса Whatnot масштабировали потоковую обработку данных с помощью Apache Kafka, изменив свои ETL-процессы и реализовав на этой распределенной платформе шину событий для анализа пользовательского поведения c ksqlDB и Rockset. Постановка задачи: события пользовательского поведения в Whatnot Whatnot – это маркетплейс, пользователи которого могут покупать и продавать...
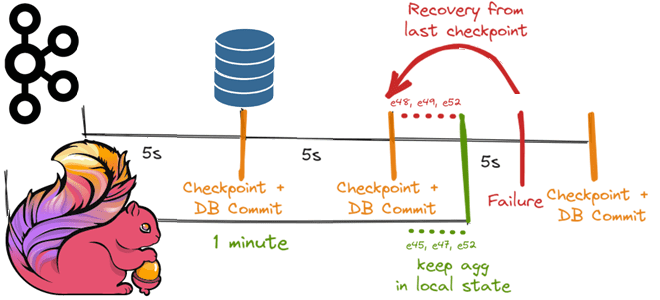
Как Apache Flink реализует строго однократную доставку событий в потовой обработке данных с помощью контрольных точек для записи данных в реляционную базу, используя функцию TwoPhasedCommitSink(), основанную на механизме согласованных snapshot’ов 35-летней давности и Kafka Transaction API. Трудности строго однократной доставки в потоковой обработке данных Распределенная обработка потоков с отслеживанием состояния...

Как турецкая e-commerce компания Trendyol повысила эффективность пакетных вычислений, используя распределенную платформу потоковой обработки событий Apache Kafka вместе с серверной утилитой сбора и фильтрации данных из разных источников Logstash. Пакетная обработка данных и конвейер на Logstash Хотя сегодня все больше организаций переходят на потоковую обработку событий в реальном времени, пакетная...

Чтобы добавить в наши курсы для администраторов кластера Apache Kafka и разработчиков распределенных приложений еще больше полезных обучающих материалов, сегодня рассмотрим новый инструмент мониторинга системных метрик этой платформы потоковой передачи событий. Что такое проект Iris и чем он отличается от других популярных средств мониторинга состояния Apache Kafka, о которых мы...
Мы уже писали о Python-клиентах Apache Kafka, которые позволяют разрабатывать приложения потоковой передачи события, используя популярный Python вместо сложных языков Java и Scala. Сегодня познакомимся с еще одной Python-библиотекой, которая представляет асинхронный клиент для Kafka. Что такое aiokafka и чем это отличается от kafka-python: краткий обзор для обучения инженеров данных...

В связи с активным переходом от локальной ИТ-инфраструктуры в облачные полностью управляемые сервисы многие ИТ-архитекторы и дата-инженеры задумываются о замене собственного кластера Apache Kafka ее Cloud-альтернативами. Читайте, что общего у Apache Kafka с AWS Kinesis, чем они отличаются и какую платформу выбрать для потоковой передачи событий. Потоковая обработка событий с...
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...

Сегодня рассмотрим пример построения гибридной архитектуры LakeHouse c Apache Kafka и Snowflake, которая гарантирует высокую масштабируемость и обеспечивает безопасность данных от несанкционированного доступа с помощью маскирования. От пакетного озера данных на AWS S3 к потоковому LakeHouse Будучи высоконадежной распределенной платформой потоковой передачи событий, Apache Kafka часто используется для обработки потока...

Специально для обучения дата-инженеров и администраторов кластера Apache Kafka, сегодня разберем, как обеспечить безопасность клиента этой распределенной платформы потоковой передачи событий по REST API с помощью возможностей открытого ПО. Что такое PEM-файлы и при чем здесь SSL-сертификаты, а также другие криптографические средства защиты данных: кейс инженеров Expedia Group. Инструменты обеспечения...

Как найти компромисс между задержкой, пропускной способностью, долговечностью и доступностью в Apache Kafka: проблемы CAP-теоремы и поиски оптимальной стороны PACELC-ромба. Архитектурные ограничения распределенных систем и лучшие практики для настройки конфигурационных параметров для администратора кластера Apache Kafka и дата-инженера потоковых приложений аналитики больших данных. CAP-теорема и распределенные системы На производительность Apache...

Сегодня рассмотрим опыт международной компании Emumba, которая специализируется на инженерии и аналитике больших данных. Читайте далее, как выгодно масштабировать конвейер потоковой передачи данных от миллионов устройств интернета вещей, используя Apache Kafka, KStream и Druid в облачной инфраструктуре AWS. Архитектура PoC для потоковой передачи событий от миллионов IoT-устройств Миллионы устройств интернета...