
Сегодня рассмотрим, как развернуть модель машинного обучения в конвейере Apache Kafka, используя потоковый API технологии удаленного вызова процедур от Google под названием gRPC и сервер ML-моделей TensorFlow Serving. Краткий ликбез по gRPC Напомним, gRPC – это технология интеграции систем, включая клиентский и серверный компоненты, основанная на удаленном вызове процедур в...

Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...
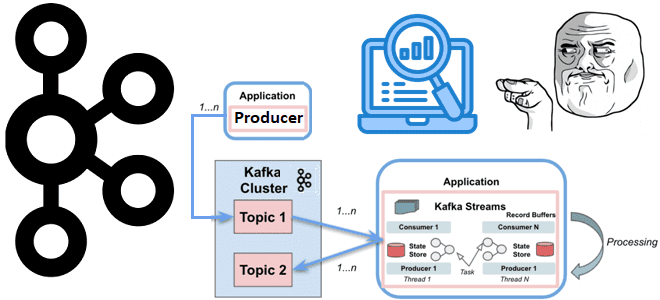
Как использовать один и тот же топик Kafka для источника и назначения данных, обеспечивая высокую пропускную способность и низкую задержку приложений Kafka Streams. А также рассмотрим, какие встроенные метрики приложений есть у Kafka Streams, как добавить свои собственные и с помощью каких инструментов их отслеживать в реальном времени. Топики и...
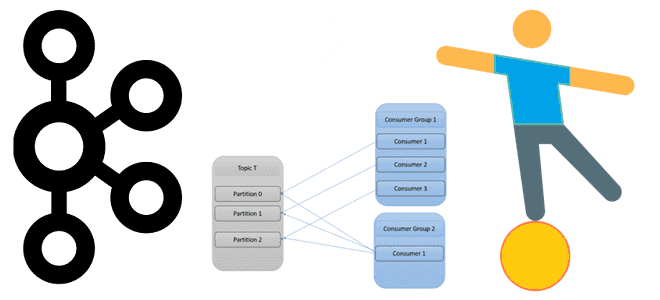
Для параллельной обработки сообщений из своих топиков Kafka использует механизм группы приложений-потребителей, о чем мы писали здесь. Читайте далее, что происходит при изменении состава группы потребителей, чем опасна частая перебалансировка и как ее избежать. Что такое перебалансировка потребителей и почему она случается? Выполняя роль интеграционного звена между приложениями-продюсерами и приложениями-потребителями...
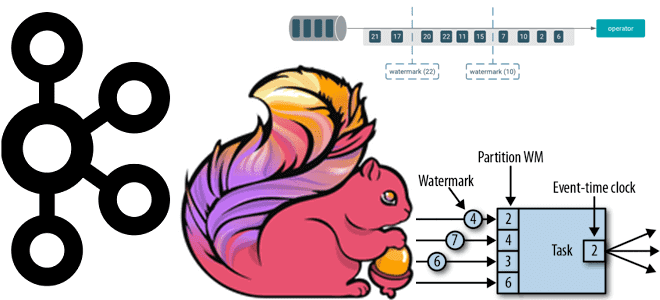
Почему вместо автоматической фиксации топиков Kafka приложению-потребителю Apache Flink лучше использовать контрольные точки, как создаются и обрабатываются водяные знаки и при чем тут оконные операторы потоковой обработки данных. Смещение в топиках Kafka для потоковых приложений Apache Flink Благодаря мощному API пакетной и потоковой обработки, Apache Flink часто используется для разработки...
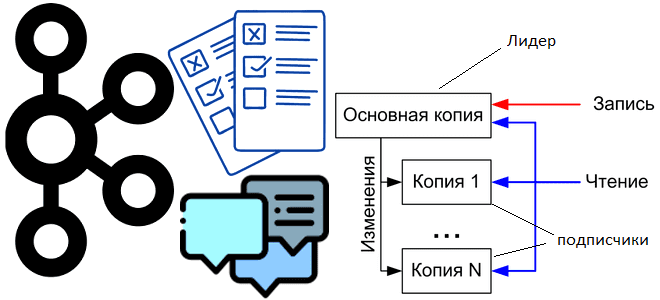
Сегодня рассмотрим, как внутренние механизмы Apache Kafka обеспечивают отказоустойчивость это потоковой платформы передачи событий, а также разберем, почему до сих пор приходится выбирать между доступностью и надежностью. Выборы нового лидера при сбое прежнего и ожидание подтверждений об успешной репликации. Поиск компромисса между надежностью и доступностью в Apache Kafka Для обеспечения...

Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами. Архитектура и принципы работы графовой MPP-СУБД TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной...
Недавно мы писали об изменении статуса и улучшении протокола KRaft в Apache Kafka 3.3. Сегодня погрузимся в эту тему чуть глубже и рассмотрим, как отказ от Zookeeper влияет на количество разделов и возможность одного и того же кластера Kafka с одним набором топиков обслуживать разные типы приложений в различных бизнес-сценариях....

23 января 2023 года вышел очередной релиз самой популярной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.3.2: готовность протокола KRaft, новый API для метрик, разделитель по умолчанию для записей без ключа, исправления и улучшения, важные для дата-инженера и администратора кластера. Apache Kafka 3.3.2: главные новинки и изменения Минорный...

Политики хранения, сжатия и очистки данных в топиках Apache Kafka: какие конфигурации нужно настроить, чтобы работать с файлами распределенных логов наиболее эффективно. Ликбез для администратора кластера Kafka и дата-инженера. Хранение данных в Apache Kafka Мы уже писали, что топик в Apache Kafka представляет собой не физическое, а логическое хранение данных....

В этой статье рассмотрим настройку инфраструктуры Kubernetes для потоковой платформы комплексных мобильных приложений на основе Apache Kafka. Что поможет добиться оптимальной масштабируемости приложений-потребителей и высокой доступности всей Big Data системы. Проблемы масштабирования платформы Grab из приложений-потребителей Apache Kafka Grab считается ведущей платформой суперприложений в 8 странах Юго-Восточной Азии, которая предоставляет...

Риски и возможности отечественного рынка труда с точки зрения профессиональной сертификации по технологиям больших данных. Как и зачем Школа Больших Данных разрабатывает профессиональную вендор-независимую сертификацию по продуктам и технологиям Big Data для еще лучшей подготовки и оценки ИТ-специалистов на российском рынке, опустевшем после ухода западных вендоров. Как изменился рынок профессиональных...

Зачем корпорации Confluent, которая продвигает Apache Kafka, понадобился Flink-стартап, чего ожидать от очередного слияния поглощения крупным игроком более мелкого предприятия, и какую пользу это принесет экосистеме потоковой передачи событий. Что Immerok и зачем это Confluent Год только начался, а в мире Big Data уже появились интересные новости. 6 января в...
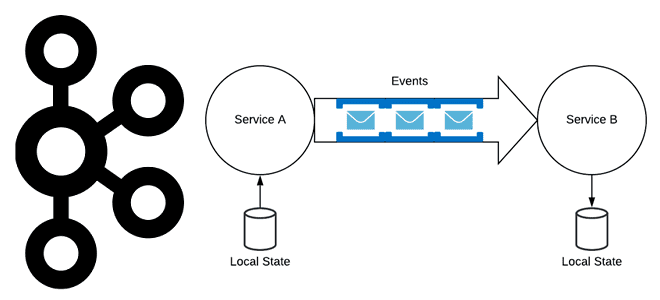
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...
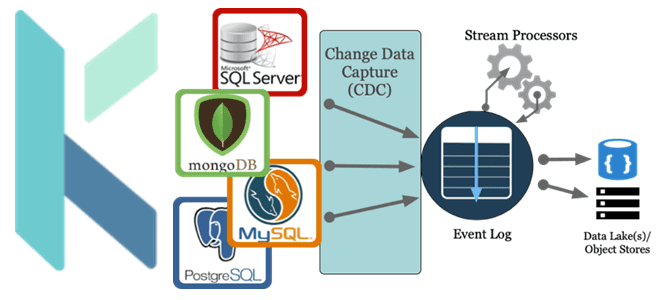
Как реализовать CDC-сценарий, используя платформу оркестрации Kestra вместо Debezium с Kafka Connect для планирования и управления конвейером обработки данных. За счет чего Kestra работает эффективнее Debezium с коннекторами Kafka Connect и при чем здесь Apache AirFlow с NiFi. Что не так с реализацией CDC на Debezium с Kafka Connect Мы...
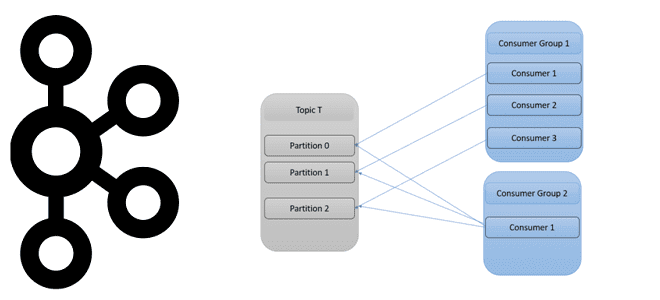
Как количество разделов топика Apache Kafka влияет на потребителей и продюсеров, зачем нужны группы потребителей и как этот механизм реализует идею микросервисной архитектуры Big Data систем. Как работают группы потребителей в Apache Kafka Будучи распределенной платформой потоковой передачи событий, Apache Kafka выполняет роль средства обмена сообщениями между приложениями-продюсерами и приложениями-потребителями...
Как использовать мощь Apache Kafka в ИТ-архитектуре корпоративных приложений и интеграции информационных систем: краткий ликбез по ключевым принципам работы этой платформы потоковой передачи событий и важность дата-контрактов для инженера данных, разработчика и архитектора. 9 лучших практик использования Apache Kafka в архитектуре приложений Чтобы успешно применять Apache Kafka в качестве основной...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня рассмотрим, какие интерфейсы и протоколы для связи клиента с брокером использует эта платформа потоковой передачи событий. А также рассмотрим, что обеспечивает двунаправленную совместимость API. Протоколы и интерфейсы Apache Kafka для общения клиентов с брокерами Apache Kafka использует бинарный протокол...

Недавно мы писали про Apache NiFi 1.18. А 28 ноября опубликован новый выпуск - 1.19.0 и спустя немного времени первый баг-фикс к нему. Разбираемся с новинками свежего релиза самого популярного потокового ETL-маршрутизатора: новые процессоры, исправления ошибок и улучшения, о которых следует знать дата-инженеру и администратору кластера. Главные новости Apache NiFi...