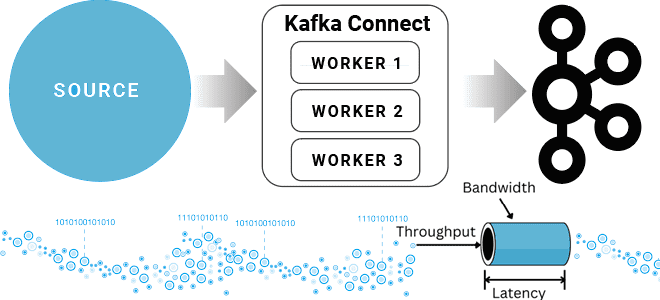
Компоненты платформы Kafka Connect и их настройки для повышения скорости и объема данных, считываемых из внешних источников и публикуемых в топике Kafka. Разбираем на примере JDBC-коннектора для реляционной базы данных. Проблемы и возможности коннекторов Kafka Connect Kafka Connect — это инструмент интеграции данных с открытым исходным кодом, который упрощает процесс...
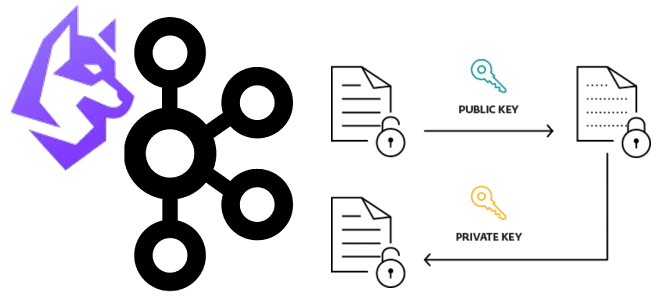
Недавно мы рассматривали пример шифрования полезной нагрузки с чувствительными данными на стороне продюсера и их расшифровку на потребителе Apache Kafka. Такой примитивный способ подходит для интеграции нескольких приложений, но в больших масштабах становится очень неудобным. Читайте, как Conduktor Gateway для Apache Kafka поможет выйти из этой ситуации, обеспечив защиту конфиденциальных...
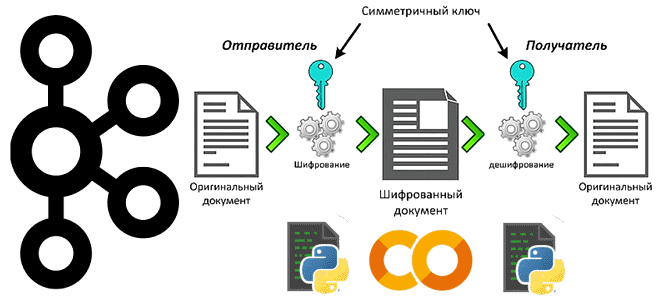
Простой пример шифрования полезной нагрузки с чувствительными данными на стороне продюсера и их расшифровка на потребителе Apache Kafka: пишем и запускаем Python-код в Google Colab. Публикация данных в Kafka: шифрование на стороне продюсера Apache Kafka часто используется для обмена данными между несколькими системами внутри предприятия. Однако, даже при работе во...

Насколько быстро работает Apache Kafka в облачной платформе Upstash: пишем простой пример для пары продюсер-потребитель на Python и измеряем задержку. Миллисекундное отставание при публикации и минутная задержка обработки данных на потребителе. Задержка публикации сообщений в Kafka Чтобы измерить задержку асинхронного обмена данными в системе с EDA-архитектурой из продюсера и потребителя...
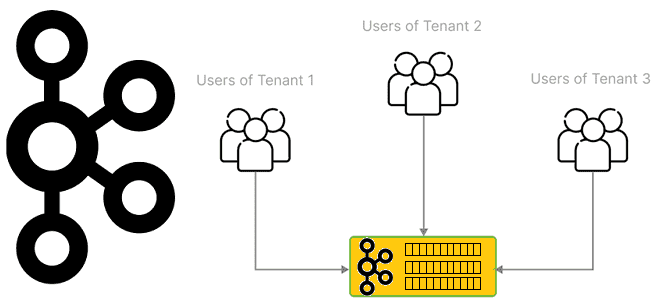
Что такое мультитенантность и как администратору Apache Kafka настроить изоляцию арендаторов в мультиарендном кластере: конфигурации, квоты и лайфхаки. Что такое мультиарендность и как реализовать эту модель для кластера Kafka Мультитенантность (мультитенантность, multitenancy) переводится с английского как множественная аренда и в контексте архитектуры ПО означает разделение одного экземпляра приложения между несколькими...
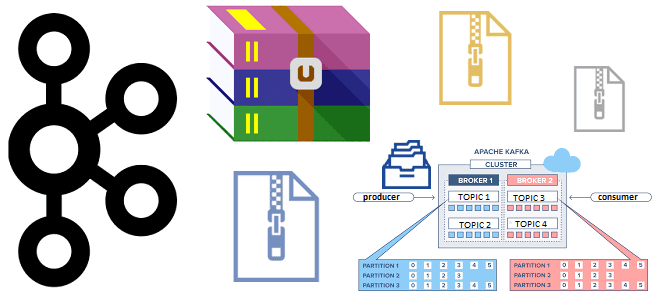
Зачем сжимать сообщения при их публикации в Apache Kafka, как устроен механизм сжатия и какие конфигурации задавать для его эффективного использования. Сжатие сообщений в Kafka: причины использования и принципы работы Единицей параллелизма в Apache Kafka является раздел топика, куда приложение-продюсер отправляет сообщение, чтобы его мог считать потребитель, назначенный на этот...
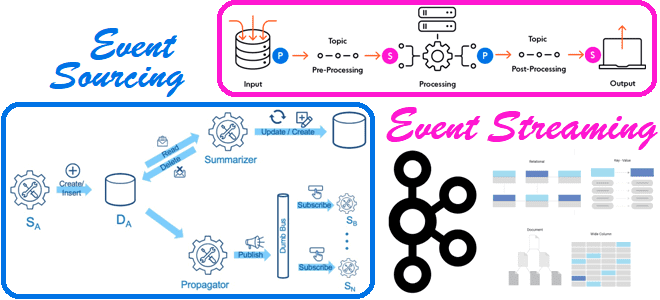
В чем разница между потоковой передачей событий и источником событий и при чем здесь Apache Kafka: разбираемся с паттернами проектирования событийно-ориентированной архитектуры. 2 паттерна проектирования EDA-архитектуры Напомним, что сегодня для построения сложных систем, зачастую состоящих из множества взаимодействующих компонентов, и реактивно реагирующих на события внешнего мира, активно используется идея архитектуры,...
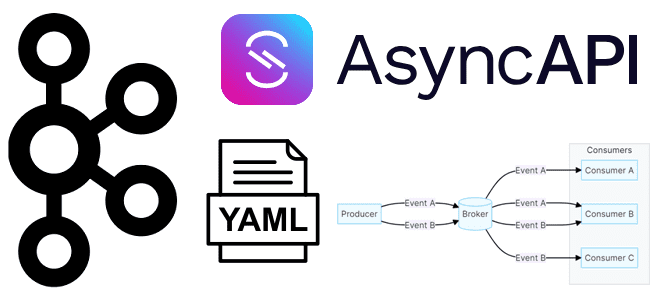
Что такое AsyncAPI, зачем документировать спецификацию для EDA-архитектур и как это сделать. Создаем свою спецификацию для Apache Kafka с помощью веб-инструмента AsynсAPI Studio. Что такое AsyncAPI Подобно тому, как Swagger (OpenAPI ) стал стандартом де-факто для описания синхронного REST API, включая HTTP-методы запросов и ответы приложения на них со структурами...

Может ли Apache Kafka поддерживать не только хореографический стиль взаимодействия между разными сервисами, кто и как организует оркестрацию рабочих процессов с помощью этой распределенной платформой потоковой передачи и почему она не заменит BPM-движки. Оркестрация событий с Apache Kafka При использовании Apache Kafka в архитектуре, управляемой событиями (EDA, Event Driven Architecture),...

Что такое квоты в Apache Kafka и как этот механизм позволяет управлять ресурсами брокера, предупреждая DDOS-атаки от слишком активных потребителей и продюсеров. Разбираемся с типами клиентских квот, их конфигурациями и принципами работы. Квоты клиента и пользователя в Apache Kafka Чтобы управлять ресурсами брокера, кластер Kafka может применять квоты на запросы...
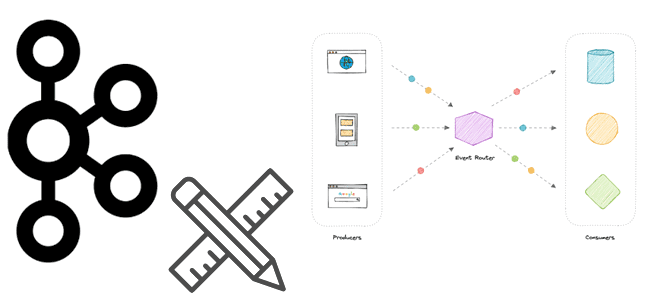
Будучи распределенной платформой передачи событий, Apache Kafka часто используется для построения архитектуры, управляемой событиями (EDA, Event Driven Architecture). Разбираемся, что такое событие и как его спроектировать, чтобы воплотить идеи EDA с Kafka. Проектирование событий для Apache Kafka В общем смысле событие – это свершившийся факт. В EDA-архитектуре события используются различными...
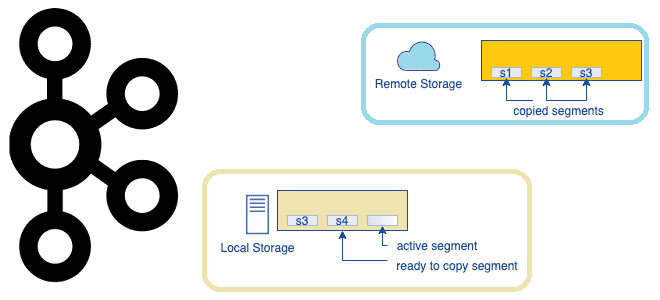
Что представляет собой очередное предложение по улучшению проекта Apache Kafka, которое расширяет возможности этой распределенной платформы потоковой передачи событий, превращая ее в средство долговременного хранения данных. Надежность vs скорость: вечный компромисс в Apache Kafka Изначально Apache Kafka позиционировалась как middleware, т.е. сервисный слой для асинхронной интеграции нескольких информационных систем. Этот...

В январе 2023 года компания Arenadata, российский разработчик отечественных Big Data решений, выпустила средство мониторинга и управления коннекторами Apache Kafka для своего продукта Arenadata Streaming (ADS). Знакомимся с возможностями и ограничениями ADSCC. Arenadata Streaming Command Center для управления коннекторами Kafka Одной из главных фишек продуктов Arenadata, является ADCM (Arenadata Cluster...

Недавно мы писали про уязвимости Apache Kafka, обнаруженные и исправленные в 2023 и 2022 гг. Сегодня рассмотрим, как одна из них устранена в отладочном релизе 3.5.1, опубликованного 21 июля 2023 года. А также познакомимся с другими улучшениями и исправлениями ошибок этого выпуска. Обновления Apache Kafka 3.5.1 Релиз Apache Kafka 3.5.1...
Как кодек сжатия snappy может вызвать ошибку нехватки памяти на брокерах, что может нарушить пользовательская JAAS-конфигурация клиента с протоколом безопасности на основе SASL и еще 4 уязвимости Apache Kafka в 2023 и 2022 гг. Уязвимости Apache Kafka 2023 года В 2023 году обнаружена уязвимость CVE-2023-34455, связанная с тем, что клиенты,...

15 июня 2023 года опубликован очередной выпуск самой популярной распределенной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.5.0, особенно важными для разработчиков, дата-инженеров и администраторов кластера. Обновления брокеров, контроллеров, продюсеров и потребителей Релиз Apache Kafka 3.5.0 богат на новинки: в нем 50 улучшений и почти 80 исправленных ошибок....
Самый простой способ организовать обработку и логирование ошибок в приложении-потребителе, чтобы продолжать считывание из Apache Kafka, даже если продюсер изменил структуру полезной нагрузки сообщения. Публикация данных в Kafka Напомним, Apache Kafka, в отличие от RabbitMQ, не позволяет организовать очередь недоставленных сообщений (DLQ, Dead Letter Queue) средствами самой платформы, о чем мы...
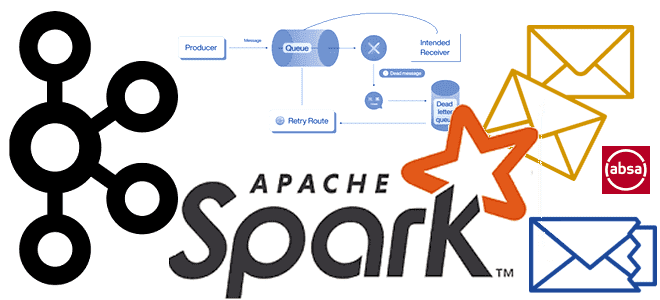
Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS. DLQ для Apache Kafka в Spark-приложении Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается....
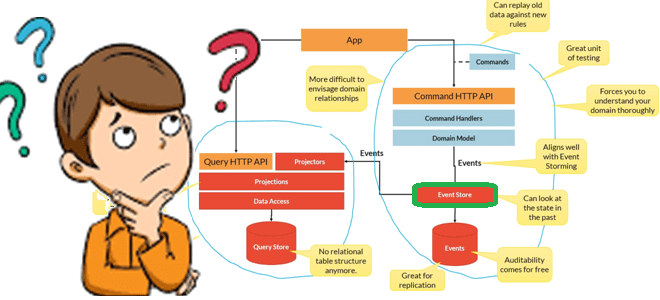
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...

Недавно мы писали про группы общего доступа в Apache Kafka, которые планируется реализовать в KIP-932. Сегодня рассмотрим, как именно это предполагается сделать. Принципы работы группы общего доступа Предложение по улучшению Kafka (KIP, Kafka Improvement Proposal) предполагает внесение значительных изменений. Все начинается с публикации предложения, которое рассматривается сообществом, комментируется и пересматривается до...