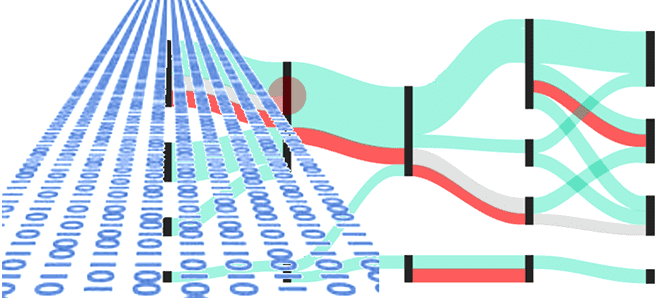
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....
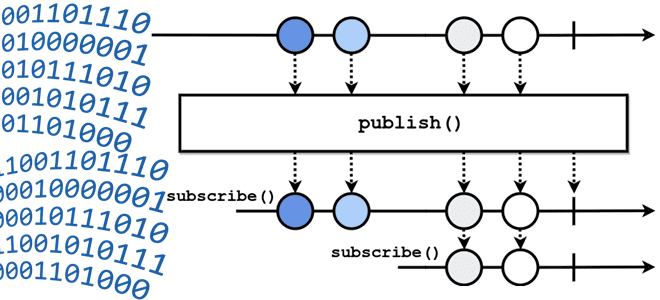
Что означает термин backpressure и зачем создавать обратное давление в streaming-системах: разбираемся с методами управления пропускной способностью потоковой передачи событий на примере Apache Kafka, Flink, Spark и NiFi. Что такое обратное давление: backpressure в конвейерах потоковой обработки данных Понять, как работает сложная концепция, проще всего на простых примерах. Это общее...
Завершая цикл статей про мультирегиональную репликацию кластеров Apache Kafka, сегодня поговорим про стратегии развертывания топологий, предлагаемых компанией Confluent. Принципы архитектуры, сравнение, сценарии, критерии выбора. Критерии выбора топологии репликации кластера Apache Kafka Для повышения надежности и производительность потоковой обработки данных с использованием Apache Kafka кластера этой платформы рекомендуется располагать в разных...
Сегодня я покажу на практическом примере, как реализовать потоковый захват изменения данных из таблицы PostgreSQL и их репликацию в Apache Kafka с помощью Debezium. Создаем и настраиваем свой коннектор на платформе Upstash. Постановка задачи Паттерн захвата измененных данных (CDC, Change Data Capture) является одним из самых распространенных в инженерии данных....
Продолжая разговор про межрегиональную репликацию Apache Kafka, сегодня рассмотрим 4 способа ее реализации: мультирегиональный кластер, MirrorMaker 2, Cluster Linking в Confluent Server и Confluent Replicator. Чем георепликация Kafka с MirrorMaker 2 отличается от решений Confluent и что выбирать для различных сценариев. Мультирегиональный кластер Confluent Геораспределенная репликация реплицирует данные по кластерам...
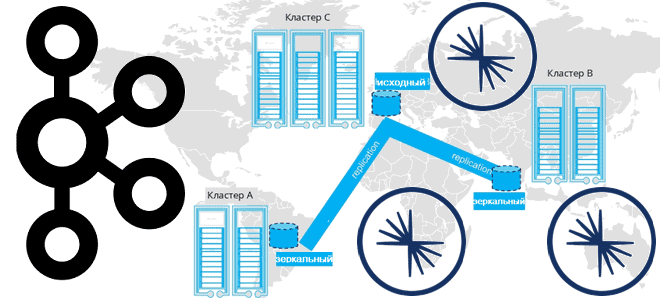
Недавно мы писали про мультирегиональную репликацию Apache Kafka. Сегодня рассмотрим, как выполнить геораспределенную репликацию с помощью Cluster Linking в Confluent Server и Kafka Connect с Confluent Replicator. Cluster Linking для Apache Kafka Связанные кластеры представляют собой 2 или более кластера в разных географических регионах. В отличие от топологии растянутого кластера,...
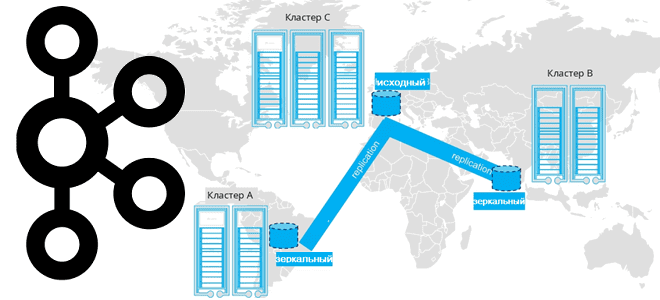
Какую топологию может иметь кластер Apache Kafka при межрегиональной репликации по нескольким ЦОД и как это реализовать. Чем брокеры-наблюдатели отличаются от подписчиков в Confluent Server и при чем здесь конфигурация подтверждений acks в приложении-продюсере. Принципы репликации данных в Apache Kafka Будучи средством интеграции информационных систем в режиме реального времени, Apache...

Какие инфраструктурные компоненты самые дорогие в эксплуатации популярной платформы потоковой передачи сообщений и как снизить затраты на сетевые ресурсы и хранилища данных при использовании Apache Kafka. TCO для Apache Kafka: что учитывать в расчете затрат Поскольку Apache Kafka используется для интеграции информационных систем в режиме реального времени, она становится критически...
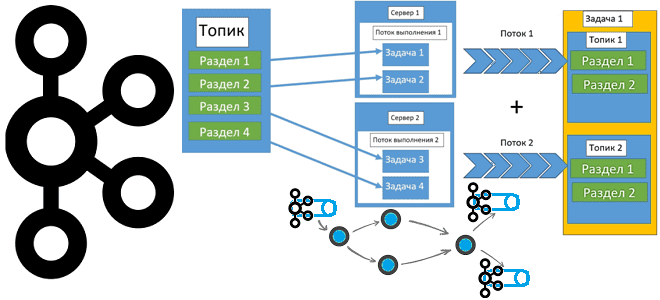
Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов, и как это все-таки сделать без изменения конфигурации топика. Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов Kafka Streams – это клиентская Java-библиотека для разработки потоковых приложений, которые работают с данными, хранящимися...
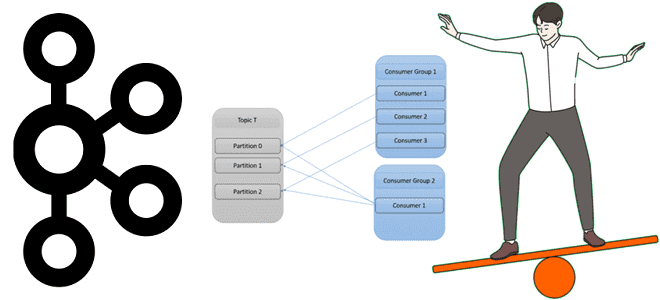
Чем group.instance.id отличается от group.id, зачем нужен member.id, каковы преимущества статического членства в группе потребителей перед динамическим и какие механизмы Kafka обеспечивают ребалансировку клиентских приложений. Еще раз про группы потребителей Apache Kafka Напомним, группы потребителей в Apache Kafka нужны для логического объединения нескольких потребителей с целью повышения надежности потоковой системы....

Что лучше: один или несколько кластеров Apache Kafka, когда и зачем разворачивать новый кластер вместо масштабирования существующего, какие задачи администрирования поручить локальным DevOps-инженерам, а что решать централизовано. Один или несколько кластеров Apache Kafka? Продолжая разговор про эффективное управление корпоративным кластером Apache Kafka, сегодня рассмотрим, когда и зачем нужно разворачивать новый...
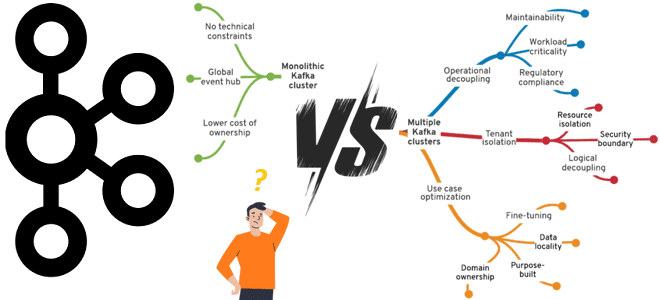
Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений. Стратегии управления корпоративным кластером Apache Kafka Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо...
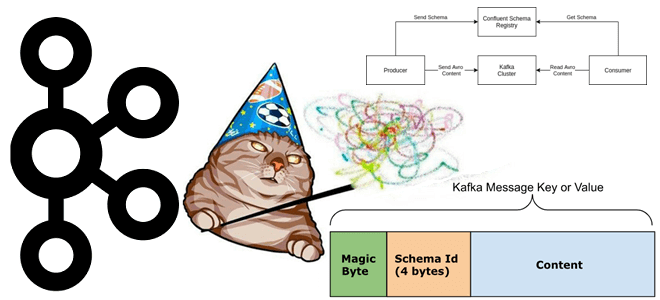
Что такое неизвестный магический байт, почему возникает эта ошибка и как предупредить такое исключение сериализации при работе с Kafka Streams, клиентами Apache Kafka и реестром схем. Что такое магический байт в сообщении Чтобы корректно обработать на стороне потребителя сообщение, считанное из Kafka, необходимо знать его формат, поскольку данные, публикуемые приложением-продюсером...
Какие меры принять администратору кластера Apache Kafka, чтобы повысить надежность потоковой экосистемы, использующей эту распределенную платформу как средство интеграции различных приложений. Сбои в потоковой экосистеме и способы их устранения Хотя Apache Kafka считается высоконадежной системой благодаря множеству встроенных механизмов отказоустойчивости, таким как репликация и перевыборы лидера. Впрочем, это не исключает...
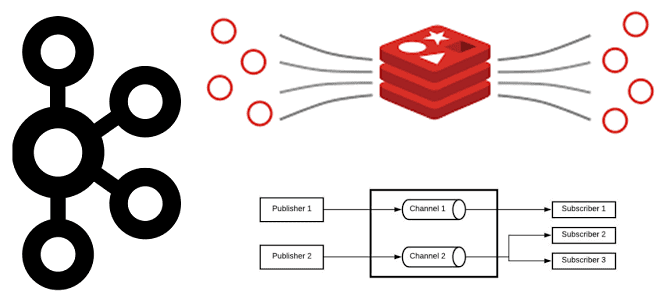
Как key-value СУБД Redis может работать с потоковыми данными и чем Pub/Sub и Streams отличаются от Apache Kafka. Сравнение и рекомендации по использованию. Потоковое сохранение данных Redis Будучи очень быстрым key-value хранилищем, NoSQL-СУБД Redis часто используется в качестве слоя кэширования для разгрузки основной базы данных. В отличие от многих других...
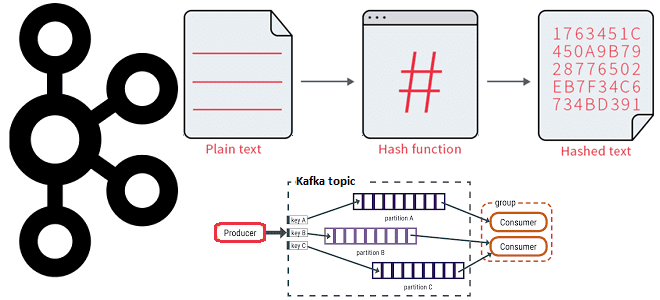
Как работает распределение сообщений по разделам топика Kafka с явно заданным ключом партиционирования и на что влияет язык разработки приложения-продюсера при использовании этой стратегии. 3 стратегии распределения сообщений по разделам в Apache Kafka В Apache Kafka единицей параллелизма выступает раздел топика. Используя несколько разделов, можно распределять нагрузку на брокеров в...
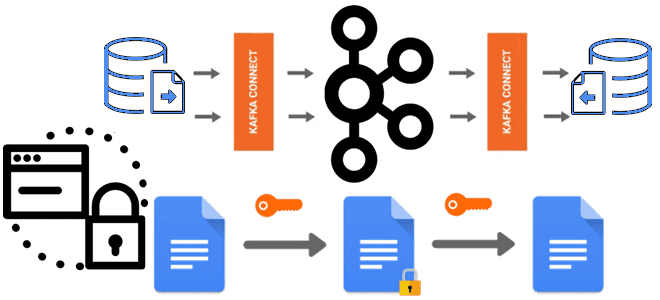
О важности шифрования чувствительных данных, публикуемых в Apache Kafka, мы недавно писали здесь и здесь. В продолжение этой темы сегодня познакомимся с Kryptonite – open-source библиотекой для сквозного шифрования на уровне полей для Apache Kafka Connect. Шифрование данных вне брокеров Apache Kafka: зачем это нужно Apache Kafka поддерживает несколько функций...

Продолжая недавний разговор про настройку конвейеров из Flink-приложений, сегодня рассмотрим, почему важна локальность данных, как избежать узких мест в приемниках потоковых данных и чем хорош HybridSource для объединения гетерогенных источников. Обеспечьте локальность данных Хотя распределенные системы обладают большим потенциалом по сравнению с локальными, позволяя обрабатывать больше данных, вычисления не происходят...

10 октября 2023 года вышел очередной релиз самой популярной распределенной платформы потоковой передачи событий. Знакомимся с главными новинками Apache Kafka 3.6.0: промышленная поддержка KRaft вместо ZooKeeper, оптимизация транзакций, повышение производительности памяти и другие фичи свежего релиза для разработчика, дата-инженера и администратора. ТОП-10 новинок выпуска 3.6 Apache Kafka 3.6.0 включает 6...
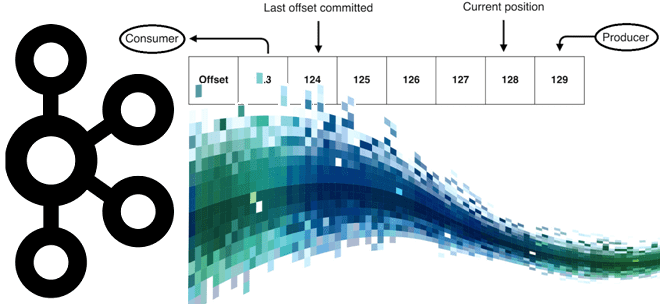
Чем политика сброса смещения earliest отличается от latest в конфигурации auto.offset.reset, зачем устанавливать свойству enable.auto.commit значение false и чем потребитель Java отличается от клиентов на основе librdkafka (C/C++, Python, Go и C#). Конфигурации Apache Kafka для управления смещением Потребитель Apache Kafka — это клиентское приложение, которое подписывается на весь топик...