
Недавно мы разбирали, что такое Apache Pulsar: архитектуру, принципы работы, сходства и различия с Kafka и RabbitMQ. В продолжение этого разговора, сегодня рассмотрим основные мифы и их опровержения в горячем споре о технологиях Big Data. Читайте далее про холивар Apache Kafka vs Pulsar vs RabbitMQ: что лучше выбрать для построения...

Продвигая наши обновленные курсы по Kafka, сегодня рассмотрим, почему в последнее время эту Big Data платформу потоковой обработки событий стали активно сравнивать с Apache Pulsar. Читайте далее, как устроен этот молодой, но интересный фреймворк потоковой обработки больших данных, чем он отличается от Kafka и RabbitMQ, что между ними общего и...

Вчера мы говорили про сложности развертывания множества stateful-приложений Apache Kafka Streams в кластере Kubernetes и роль контроллера StatefulSet, который поддерживает состояние реплицированных задач за пределами жизненного цикла отдельных подов. В продолжение этой темы, сегодня рассмотрим механизм проб, которые позволяют определить состояние распределенного приложения, развернутого на платформе контейнерной виртуализации. В качестве...
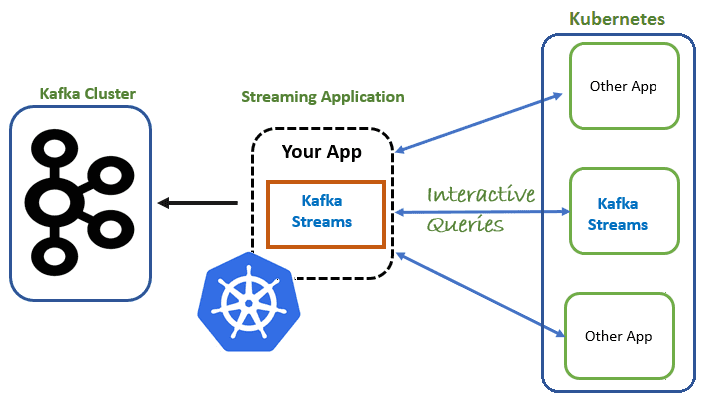
Сегодня рассмотрим особенности запуска приложений Apache Kafka Streams для потоковой обработки больших данных с отслеживанием состояния в кластере Kubernetes. Читайте далее, в чем проблема управления stateful-приложениями Kafka Streams в Kubernetes и как ее решает контроллер StatefulSet. Что обеспечивает хранение состояний в Apache Kafka Streams Напомним, Kafka Streams – это легковесная...

В этой статье поговорим про интеграцию данных с помощью CDC-подхода и репликацию SQL-таблиц из корпоративной СУБД в несколько разных удаленных хранилищ в реальном времени с применением Apache Kafka и Debezium, развернутых в Kafka Connect и Confluent Cloud. Постановка задачи: CDC с Big Data в реальном времени Рассмотрим кейс, который часто...

Чтобы сделать ваше самостоятельное обучение Apache Kafka и прочим технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам открытый интерактивный тест по этой платформе потоковой обработки событий. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...

Совместное использование Apache Kafka и Spark очень часто встречается в потоковой аналитике больших данных, например, в прогнозировании пользовательского поведения, о чем мы рассказывали вчера. Однако, временные метки (timestamp) в приложении Spark Structured Streaming могут отличаться от времени события в топике Kafka. Читайте далее, почему это случается и какие подходы к...
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...

Вчера мы говорили про реализацию exactly once семантики доставки сообщений в Apache Spark Structured Streaming. Сегодня рассмотрим, что не так с размером компактных файлов для хранения контрольных точек потоковой передачи, какие параметры конфигурации Spark SQL отвечают за такое логирование и как ускорить микро-пакетную обработку больших данных и чтение результатов выполнения...

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...
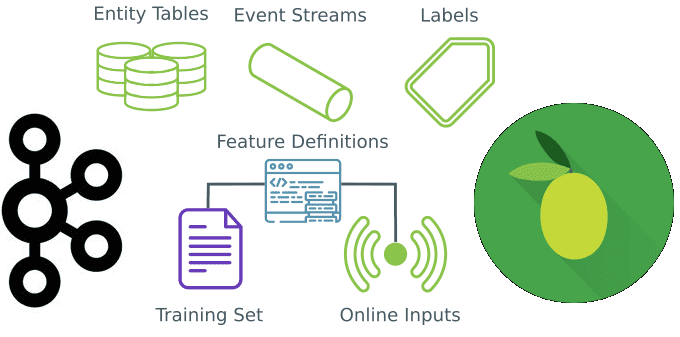
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...

В продолжение вчерашнего материала про потоковую аналитику больших данных с Apache Kafka и Spark, сегодня рассмотрим особенности совместного использования этих технологий Big Data. В этой статье мы собрали для вас 5 лучших практик эффективного применения Apache Kafka и Spark Streaming для разработки распределенных приложений аналитики больших данных в режиме реального...

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...
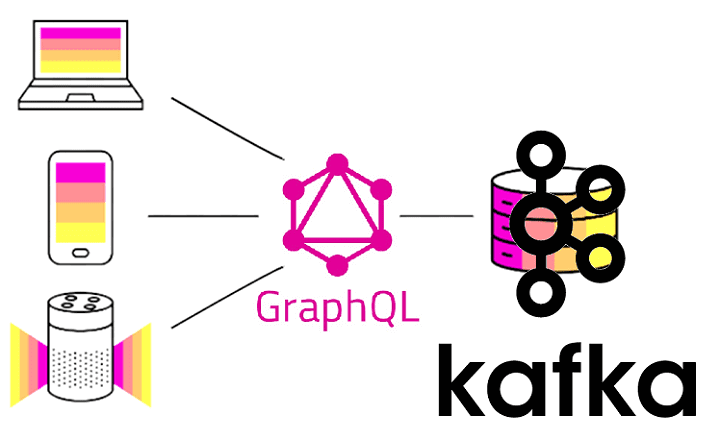
В рамках продвижения нашего нового курса Apache Kafka для разработчиков недавно мы рассматривали RESTful API к этой Big Data платформе потоковой обработки событий на примере Confluent REST Proxy. Сегодня разберем альтернативу REST-интерфейсам в виде GraphQL и применимости этой технологии к разработке распределенных Kafka-приложений. Что такое GraphQL и чем он лучше...
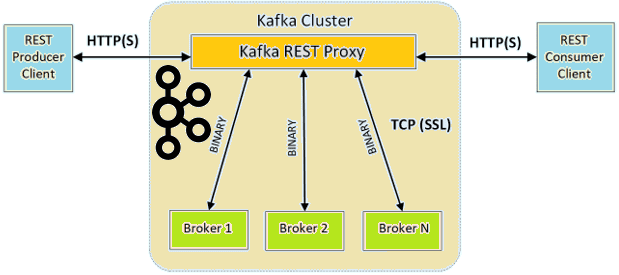
Продолжая разбираться с Confluent REST Proxy для Apache Kafka, сегодня рассмотрим основные достоинства и недостатки этого RESTful API. Читайте далее, что Confluent REST Proxy позволяет делать с Apache Kafka и что ограничивает его взаимодействие с самой популярной Big Data платформой потоковой обработки событий. 6 главных преимуществ RESTful API к...
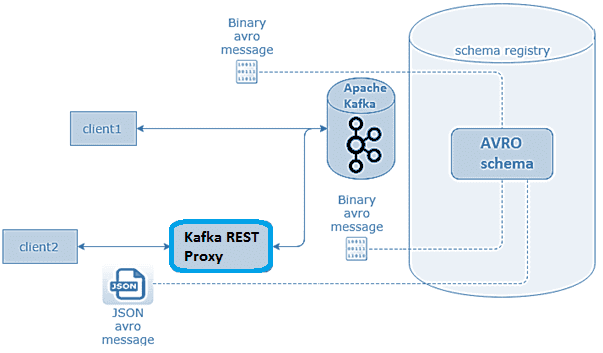
В этой статье разберем, что такое Confluent REST Proxy для Apache Kafka, как работает этот RESTful API, каким образом он связан с облачным сервисом этой популярной Big Data платформой потоковой обработки событий, а также при чем здесь Schema Registry. Основы Confluent REST Proxy для Apache Kafka Широко известная в области...
Сегодня поговорим про обучение Apache Kafka и рассмотрим сценарии применения HTTP и RESTful протоколов в этой Big Data платформе потоковой обработки событий. Читайте далее, чем парадигма request-response отличается от event streaming processing, как связаны REST и HTTP, каковые преимущества RESTful API и где это используется на практике для обработки и...

Развивая наш новый курс по Apache Kafka для разработчиков, сегодня мы рассмотрим 3 способа о взаимодействии с этой популярной Big Data платформой потоковой обработки событий с помощью языка Python, который считается самым распространенным инструментом в Data Science. Читайте далее, что такое librdkafka, чем PyKafka отличается от Kafka-Python и почему решение...