
Мы уже упоминали, что Apache Kafka не слишком хорошо обрабатывает сообщения чрезмерно большого размера. Сегодня рассмотрим, как эта проблема решается в конвейерах потоковой обработки IoT-инфраструктуры Tesla. Читайте далее про модификацию синтаксического анализатора данных от множества устройств интернета вещей с поиском компромисса между скоростью и надежностью с помощью коннектора Alpakka к...

Продолжая разбирать кейс компании Tesla по организации централизованного управления устройствами интернета вещей (Internet of Things, IoT), сегодня разберем, как выполняется обработка сообщений в топиках Apache Kafka с помощью Confluent Schema Registry и Kafka Streams. Читайте далее, как определить потоковый процессор для парсинга данных в CSV и JSON-форматах с использованием схемы...

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...

Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache...

Apache Storm обычно сравнивают со другими популярными фреймворками потоковой аналитики больших данных: Spark и Flink. Однако для несложной обработки событий дата-инженер может заменить эти платформы более легким инструментом маршрутизации потоковых данных в виде Apache NiFi. Сегодня сравним Apache NiFi co Storm и разберем практический пример, когда предпочтительнее именно его для...

В этой статье для дата-инженеров и администраторов Apache Kafka рассмотрим, зачем Confluent выпустил премиум коннектор Splunk S2S Source и как на базе этих платформ построить эффективную систему потоковой аналитики больших данных. Также читайте далее, что такое универсальный сервер рассылки Splunk и какие конфигурации коннектора позволяют автоматически создавать топик Kafka для сбора...
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...
6 июня 2021 года компания Confluent, которая продвигает коммерческую версию платформы Apache Kafka, выпустила новый релиз ksqlDB. Сегодня рассмотрим самые важные исправления ошибок и новые функции ksqlDB 0.19.0, уделив особое внимание SQL-запросам соединения таблиц через JOIN по внешнему ключу. ТОП-10 исправленных ошибок в новом релизе ksqlDB Напомним, ksqlDB – это...

Продолжая разбирать тонкости сериализации данных в Apache Kafka на практических примерах, сегодня рассмотрим кейс индийской ИТ-компании Naukri Engineering о повторной обработке сообщений и особенностях форматов. Читайте далее, чем хороши заголовки Kafka и почему их не так просто использовать, а также зачем писать свой сериализатор с десериализатором для достижения 100%-ного SLA....
Сегодня рассмотрим проблему обработки больших сообщений в Apache Kafka Streams и способы ее решения с помощью средства сериализации и десериализации (SerDe) от немецкой ИТ-компании Bakdata. Узнайте, почему максимального лимита конфигурации max.message.bytes не хватает, зачем и как приложение Kafka Streams материализует данные, а также каким образом kafka-s3-backed-serde читает и записывает большие...
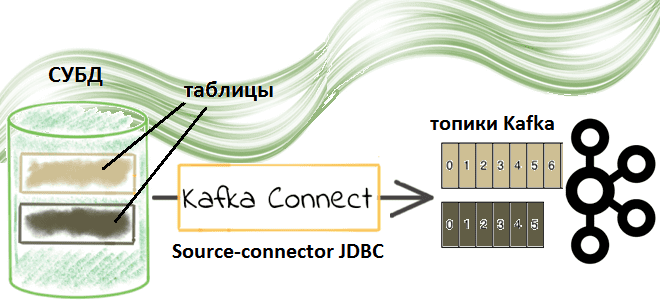
Недавно мы рассматривали пример потоковой передачи данных между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Сегодня заглянем под капот такой интеграции и разберем подробнее, что именно представляет собой JDBC-коннектор источника Kafka от Confluent. Компоненты Kafka Confluent для потоковой интеграции данных: коннекторы и реестр схем...

Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...

Сегодня в рамках обучения разработчиков распределенных приложений и дата-инженеров рассмотрим практический пример потоковой интеграции данных из 2-х разных источников с Apache Kafka. Читайте далее, как мгновенно передать данные между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Apache Kafka как средство потоковой интеграции данных Интеграция...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...
Сегодня рассмотрим 2 важных понятия архитектуры распределенных систем для хранения и аналитики больших данных на примере платформы потоковой обработки событий Apache Kafka.Читайте далее, что такое согласованность и полнота, а также в чем преимущества строго однократной доставки сообщений на основе транзакционной записи и фиксации смещений в журналах, и как все это...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Вчера мы рассказывали, почему некоторые OOM-ошибки stateful-приложений Kafka Streams могут быть вызваны некорректной работой RocksDB – встроенного key-value NoSQL-хранилище состояний. Сегодня рассмотрим, какие проблемы с дисковыми операциями характерны для этой СУБД, как они отражаются на Kafka-приложениях потоковой аналитики больших данных и каким образом можно это исправить. Быстрые диски, RocksDB и...

Сегодня заглянем под капот stateful-приложений Kafka Streams и рассмотрим, что такое RocksDB, как устроено это key-value NoSQL-хранилище и почему его необходимо настраивать для быстрой и безотказной работы приложений потоковой аналитики больших данных. Читайте далее, какие проблемы приложений Kafka Streams связаны с RocksDB и как ограничить повышенное потребление оперативной памяти. Что...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...