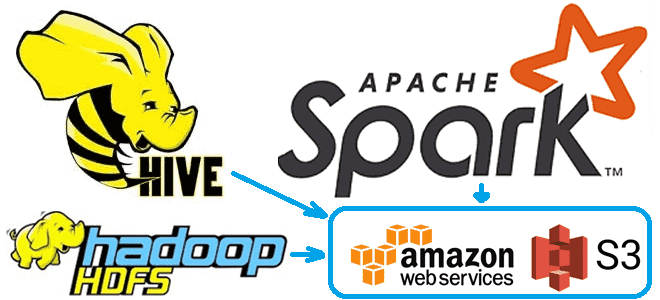
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive. Еще раз о разнице...
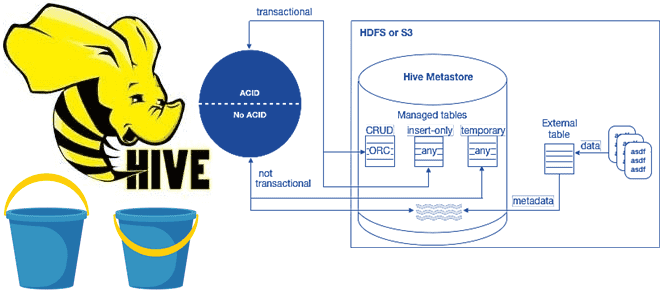
В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов. Еще раз про...

Недавно мы писали, что в новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, сделаны попытки объединения потоковой и пакетной парадигм обработки данных. Сегодня рассмотрим, как подобное стремление к унификации реализуется на практике дата-инженерами фотохостинга Pinterest, которые используют Apache Flink как универсальный инструмент аналитики больших данных в...

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....

В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...

Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано. Зачем...
В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и...
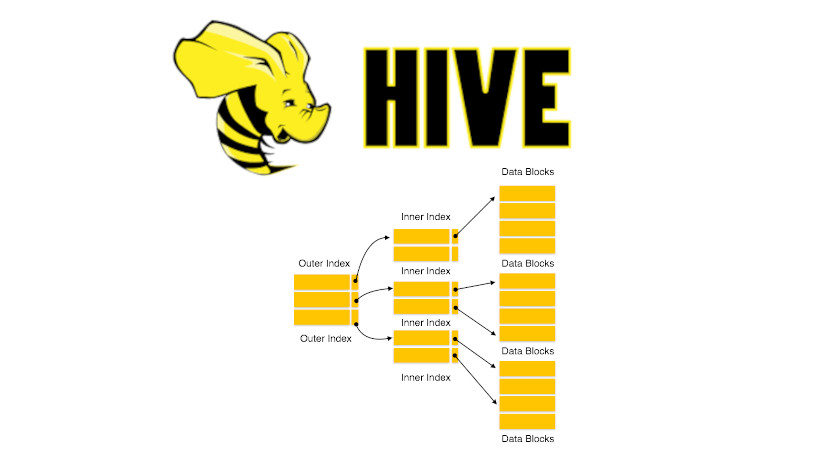
В прошлый раз мы говорили про драйвер JDBC и его использование в Hive. Сегодня поговорим про особенности создания и работы индекса в распределенной Big Data платформе Apache Hive. Читайте далее про особенности работы с индексами в распределенной среде Big Data СУБД Hive. Какую роль играет использование индекса при обработке Big...
Появившись более 10 лет назад, Apache Hive до сих пор является самым популярным инструментом стека SQL-on-Hadoop и активно используется для аналитики больших данных. Однако, технологии Big Data постоянно развиваются: Spark все чаще заменяет Hadoop MapReduce, а вместо HDFS все чаще используются объектные облачные хранилища: AWS S3, Delta Lake, Apache Ozone...
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...

В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

Сегодня в рамках обучения дата-аналитиков и разработчиков Spark-приложений, рассмотрим еще несколько особенностей этого фреймворка. Почему count() работает по-разному для RDD и DataFrame, как отличается уровень хранения при применении метода cache() для этих структур, когда использовать SortWithinPartitions() вместо sort(), а также парочка тонкостей обработки Parquet-таблиц в Spark SQL и кэширование метаданных...

Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...

Чтобы самостоятельное обучение по Hive стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с драйвером-коннектором JDBC в этой распределенной СУБД, включая его особенности работы и взаимодействия с Java-приложениями. Тест по основам работы драйвера JDBC для новичков Для тех, кто начинает самостоятельное обучение по Apache Hive, мы...

В прошлый раз мы говорили про особенности работы с основными join-операциями в Hive. Сегодня поговорим про использование JDBC-драйвера при работе в распределенной Big Data платформе Apache Hive. Читайте далее про особенности использования этого драйвера при работе в распределенной среде Hive. Использование драйвера JDBC в распределенной СУБД Apache Hive Драйвер JDBC...

В июле 2021 года «Аренадата Софтвер», российская ИТ-компания разработчик отечественных решений для хранения и аналитики больших данных, представила минорный релиз корпоративного дистрибутива на базе Apache Hadoop — Arenadata Hadoop 2.1.4. Главными фишками этого выпуска стало наличие 3-й версии Apache Spark и External PostgreSQL для Hive MetaStore. Сегодня рассмотрим, что именно...

Вчера мы упоминали, что использование Spark или Tez в качестве движка исполнения SQL-запросов в Apache Hive вместо классического Hadoop MapReduce намного ускоряет аналитику больших данных. Сегодня рассмотрим подробнее, чем отличаются эти механизмы и какой из них выбирать в разных случаях использования. Что такое Apache Tez и как он работает с...

Apache Hive – востребованный инструмент класса SQL-on-Hadoop, который также активно используется в работе с фреймворком Spark. Поэтому сегодня разберем важную тему из обучения дата-инженеров и аналитиков больших данных про оптимизацию SQL-запросов в этом NoSQL-хранилище. Смотрите, чем полезна векторизация HiveQL-операций, какие форматы файлов обрабатываются быстрее, почему денормализация данных в Hive –...

В прошлый раз мы говорили про особенности работы с базовыми CRUD-операциями в Hive. Сегодня поговорим про основные join-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про особенности работы с join-операциями в распределенной СУБД Apache Hive. Join-операции в...

Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...