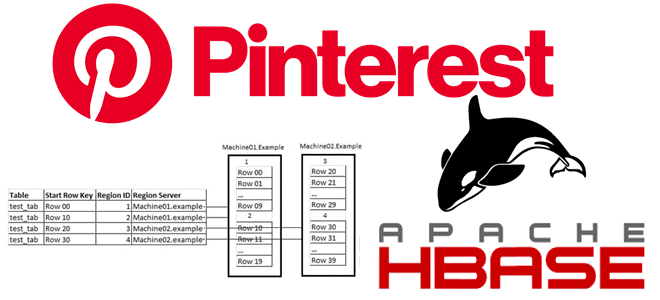
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...

В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...
В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и...
Появившись более 10 лет назад, Apache Hive до сих пор является самым популярным инструментом стека SQL-on-Hadoop и активно используется для аналитики больших данных. Однако, технологии Big Data постоянно развиваются: Spark все чаще заменяет Hadoop MapReduce, а вместо HDFS все чаще используются объектные облачные хранилища: AWS S3, Delta Lake, Apache Ozone...
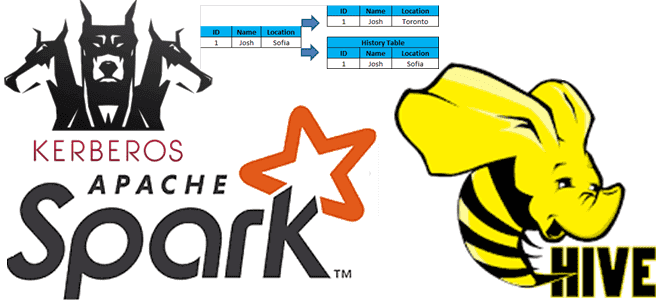
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...

В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...
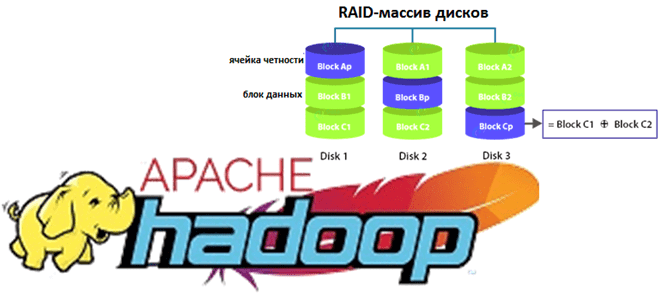
Недавно мы рассказывали про новые функции свежего релиза Apache Hadoop 3.3.1. Сегодня разберем подробнее, что такое Erasure Coding и как эта технология кодирования со стиранием экономит место в распределенной файловой системе HDFS. Также заглянем внутрь EC и рассмотрим, чем алгоритм Рида-Соломона лучше ассоциативной операции XOR для обеспечения отказоустойчивости хранилища больших...

Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...

В июле 2021 года «Аренадата Софтвер», российская ИТ-компания разработчик отечественных решений для хранения и аналитики больших данных, представила минорный релиз корпоративного дистрибутива на базе Apache Hadoop — Arenadata Hadoop 2.1.4. Главными фишками этого выпуска стало наличие 3-й версии Apache Spark и External PostgreSQL для Hive MetaStore. Сегодня рассмотрим, что именно...

Постоянно обновляя наши курсы по Apache Hadoop для администраторов кластеров и инженеров данных, сегодня рассмотрим главные новинки июньского релиза 2021. Читайте далее, как поддержка Erasure Coding сэкономит место в HDFS, зачем обновляться до 8-ой версии Java, чем хорош YARN Timeline Service v.2, как повысить надежность кластера Hadoop еще больше и...

Продолжая обучение основам Apache Hadoop для начинающих администраторов, сегодня рассмотрим архитектуру и принципы работы YARN в кластере. Также разберем, какие отказы могут случиться на каждом из его компонентов и как Resource Manager системы YARN обеспечивает высокую доступность кластера Apache Hadoop. Зачем Apache Hadoop нужен YARN и как он работает Поскольку...

При том, что Apache Hadoop – высоконадежная экосистема хранения и аналитики больших данных, отказы случаются и в ней. Сегодня в рамках обучения начинающих администраторов и разработчиков Hadoop разберем, какие типы сбоев возможны в распределенной файловой системе HDFS и механизмы их предупреждения, а также рассмотрим процедуру вывода узлов из кластера для...

Вчера мы упоминали, что использование Spark или Tez в качестве движка исполнения SQL-запросов в Apache Hive вместо классического Hadoop MapReduce намного ускоряет аналитику больших данных. Сегодня рассмотрим подробнее, чем отличаются эти механизмы и какой из них выбирать в разных случаях использования. Что такое Apache Tez и как он работает с...

Apache Hive – востребованный инструмент класса SQL-on-Hadoop, который также активно используется в работе с фреймворком Spark. Поэтому сегодня разберем важную тему из обучения дата-инженеров и аналитиков больших данных про оптимизацию SQL-запросов в этом NoSQL-хранилище. Смотрите, чем полезна векторизация HiveQL-операций, какие форматы файлов обрабатываются быстрее, почему денормализация данных в Hive –...

В рамках практического обучения дата-инженеров сегодня мы собрали 10 лучших практик проектирования конвейеров обработки данных в рамках Apache AirFlow, которые касаются не только особенностей этого фреймворка. Также рассмотрим, какие принципы разработки ПО особенно полезны для инженерии больших данных с Apache AirFlow. ТОП-10 рекомендаций дата-инженеру для настройки Apache Airflow и не...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...

В поддержку курса Hadoop для инженеров данных сегодня разберем, в чем проблема безопасной отправки заданий и файлов в облачное хранилище Amazon S3 и как ее решить. Читайте далее, почему AWS S3 не дает гарантий согласованности как HDFS, из-за чего S3Guard не обеспечивает транзакционность и как настроить коммиттеры S3A для Spark...

Месяц назад, в начале января 2021 года вышел новый релиз Apache Hadoop 3.2.2. Читайте далее, чего ждать от самой главной технологии Big Data, какие ошибки исправлены, зачем внесены изменения и кому они будут особенно полезны. 7 главных обновлений Apache Hadoop 3.2.2 Этот второй выпуск версии 3.2 содержит 516 исправлений ошибок,...

В этой статье рассмотрим особенности совместного использования Apache Kafka и Spark Streaming для обработки финансовых транзакций в режиме онлайн. Читайте далее про типовые кейсы практического применения конвейера аналитики больших данных на базе Kafka и Spark, а также проблемы или технологические особенности такой Big Data системы и пути обхода этих ограничений....