
В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
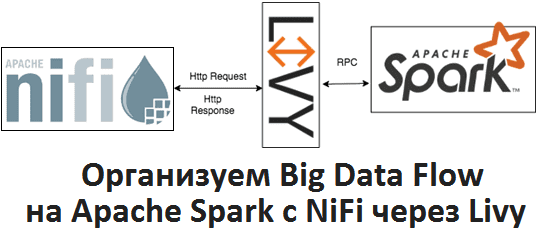
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...

Сегодня мы расскажем о важности прикладного бизнес-анализа в проектах Big Data, включая цифровизацию частного бизнеса и государственных предприятий. Читайте в нашей статье, как области знаний профессионального руководства по бизнес-анализу BABOK®Guide соответствуют типовым этапам внедрения технологий больших данных в корпоративную деятельность, и почему цифровая трансформация любой компании – это, прежде всего,...

Продолжая разговор про обучение Spark на реальных примерах, сегодня мы рассмотрим, как работает этот Big Data фреймворк на Kubernetes, популярной DevOps-платформе автоматизированного управления контейнеризированными приложениями. Читайте в нашей статье, как запустить приложение Apache Spark в кластере Kubernetes (K8s) с помощью submit-скрипта и оператора, а также при чем здесь Docker-образ. Запуск...

Вчера мы рассказывали об основных сценариях запуска Apache Spark на Kubernetes и преимуществах этого варианта развертывания популярного Big Data фреймворка на DevOps-платформе автоматизированного управления контейнеризированными приложениями. Сегодня поговорим про обратную сторону всех этих преимуществ: читайте в нашей статье, каковы основные ограничения и главные недостатки запуска Apache Spark на Kubernetes (K8s)....
Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...

Недавно мы разбирали особенности интеграции Apache Kudu и Spark. В продолжение этой темы, сегодня поговорим про некоторые особенности выполнения SQL-операций с данными при интеграции этих Big Data фреймворков, а также рассмотрим пример записи данных в мульти-мастерный кластер Куду через Impala с помощью API Data Frame на PySpark. Что приносит Kudu...

Сегодня мы рассмотрим практический кейс использования Apache Kudu с Kafka, Storm и Cloudera Impala в крупной китайской корпорации, которая производит смартфоны. На базе этих Big Data технологий компания Xiaomi построила собственную платформу для BI-аналитики больших данных и генерации отчетности в реальном времени. История Kudu-проекта в Xiaomi Корпорация Xiaomi начала использовать...
Вчера мы говорили про интеграцию Apache Kudu со Spark SQL, Kafka и Cloudera Impala для эффективной организации озера данных (Data Lake), обеспечивающего быструю аналитику больших данных в режиме реального времени. В продолжение этой темы, сегодня рассмотрим 5 примеров практического использования kudu в Big Data проектах, уделив особое внимание системам бизнес-аналитики...

В продолжение темы про совместное использование Apache Kudu с другими технологиями Big Data, сегодня рассмотрим, как эта NoSQL-СУБД работает вместе с Kafka, Spark и Cloudera Impala для построения озера данных (Data Lake) для быстрой аналитики больших данных в режиме реального времени. Также читайте в нашей статье про особенности интеграции Apache...

В этой статье продолжим разговор про Apache Kudu и рассмотрим, как эта NoSQL-СУБД используется с Hadoop и Cloudera Impala, чем она полезна в организации озера данных (Data Lake) и почему Куду не заменяет, а успешно дополняет HDFS и HBase для эффективной работы с большими данными (Big Data). Apache Kudu в...

Сегодня поговорим про движки хранения больших данных в экосистеме Apache Hadoop и рассмотрим, что такое Kudu, каковы особенности применения, достоинства и недостатки этой колоночной NoSQL-СУБД. Также читайте в нашей статье, как Kudu связан с Impala, Spark и другими Big Data фреймворками. Что такое Apache Kudu и где это используется Распределенная...

Аналитика больших данных для руководителей и других конечных бизнес-пользователей – это не только графические дэшборды BI-систем. Сегодня рассмотрим, что такое самообслуживаемая аналитика Big Data, какова ее польза для бизнеса и чего не стоит ждать от self-service BI. Что такое self-service BI: определение, назначение и примеры Еще в 2018 году исследовательское...

В продолжение темы про озера данных (Data Lake) и Apache Hadoop, сегодня мы рассмотрим еще 3 примера использования этих технологий Big Data для аналитики больших данных в промышленности. Читайте в нашей статье, как косметический гигант L’Oréal создает новые продукты с помощью платформы Talend Data Fabric, «УРАЛХИМ» прогнозирует объемы продукции и...

В этой статье разберем кейс построения экосистемы управления Big Data с озером данных на примере федеральной фармацевтической сети - российской Ассоциации независимых аптек (АСНА). Читайте в этом материале, зачем фармацевтическому ритейлеру большие данные, с какими трудностями столкнулся этот проект цифровизации и как открытые технологии (Arenadata Hadoop, Apache Spark, NiFi и...

Сегодня поговорим про еще один open-source проект от Apache Software Foundation – Bigtop, который позволяет собрать и протестировать собственный дистрибутив Hadoop или другого Big Data фреймворка, например, Greenplum. Читайте в нашей статье, что такое Apache Bigtop, как работает этот инструмент, какие компоненты он включает и где используется на практике. Что...

Мы уже затрагивали тему корпоративных хранилищ данных (КХД), управления мастер-данными и нормативно-справочной информаций (НСИ) в контексте технологий Big Data. В продолжение этого, сегодня рассмотрим, что такое профилирование данных, зачем это нужно, при чем тут озера данных (Data Lake) и ETL-процессы, а также прочие аспекты инженерии и аналитики больших данных. Что...

Сегодня мы расскажем, почему каждый Big Data специалист должен знать этот язык программирования и как «Школа Больших Данных» поможет вам освоить его на профессиональном уровне. Читайте в нашей статье, кому и зачем нужны корпоративные курсы по Python в области Big Data, Machine Learning и других методов Data Science. Чем хорош...

В этой статье поговорим про интеграцию ELK-стека с экосистемой Apache Hadoop: зачем это нужно и с помощью каких средств можно организовать обмен данными между HDFS и Elasticsearch, а также при чем здесь Apache Spark, Hive и Storm. Еще рассмотрим несколько практических примеров, где реализована такая интеграция Big Data систем для...