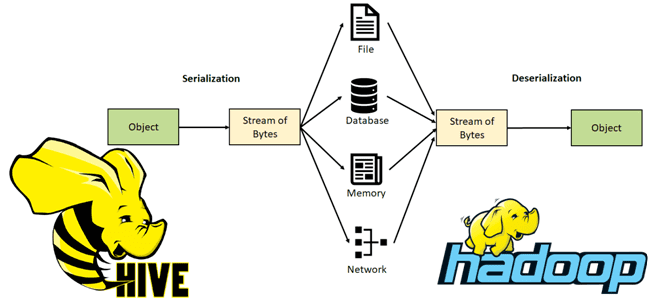
Чтобы добавить еще больше практики в наши курсы для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим тонкости сериализации данных в Apache Hive. Читайте далее, как этот популярный SQL-on-Hadoop инструмент обрабатывает данные из HDFS, что такое SerDe и как написать собственный сериализатор/десериализатор. Сериализация и десериализация данных в Apache Hive В настоящее...
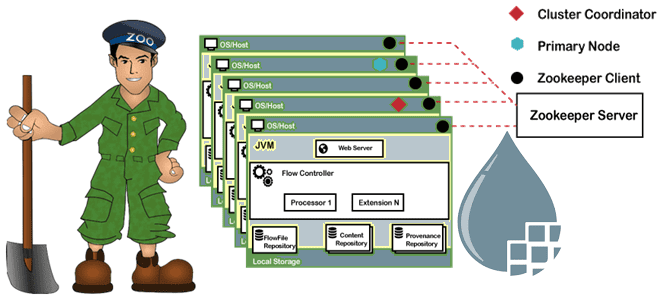
Сегодня рассмотрим важную для обучения администраторов кластера Apache NiFi тему по установке и настройке этого потокового ETL-фреймворка с использованием встроенного сервиса координации и синхронизации метаданных в распределенных системах Zookeeper. А также рассмотрим, как процесс выбора лидера в кластере Zookeeper позволяет серверам избежать аномальных всплесков трафика от клиентов и роста нагрузки....

В этой статье для обучения дата-инженеров и аналитиков данных заглянем под капот Apache Hive, чтобы разобраться с механизмов LLAP. Как этот движок повышает производительность популярного SQL-on-Hadoop инструмента, поддерживая длительные процессы на одних и тех же ресурсах для кэширования и аналитической обработки больших данных. Что такое LLAP в Apache Hive и...
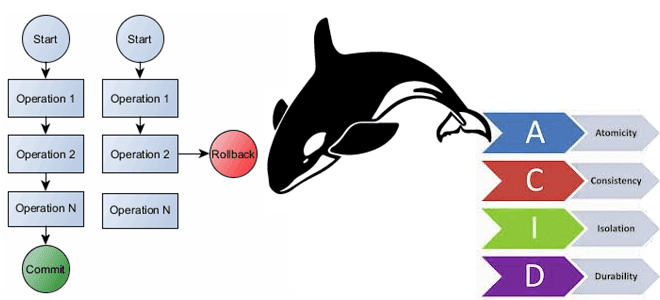
В этой статье для обучения архитекторов, дата-инженеров и аналитиков данных рассмотрим, как поддерживаются транзакции в Apache HBase и почему к ACID-свойствам также добавляется характеристика видимости обновлений. Насколько атомарны и консистентны мутации данных внутри строки HBase, почему сканирование не полностью согласовано и как разрешить устаревшие чтения или путешествия во времени в...

Сегодня рассмотрим несколько полезных приемов по работе с Apache Hive, которые пригодятся инженеру данных и специалисту по Data Science в проектах аналитики больших данных. Как разделить и сегментировать таблицы, зачем изменять значение конфигурации памяти этапов MapReduce, чем полезна автоматическая обработка асимметрии данных и еще пара лайфхаков для ускорения выполнения SQL-запросов...

В апреле 2022 года вышел очередной минорный релиз Apache Hive, который работает с Hadoop версии 3. Рассмотрим основные улучшения и исправленные ошибки этого обновления, которые пригодятся дата-инженеру и разработчику распределенных приложений аналитики больших данных. Исправленные ошибки В апрельском выпуске популярного NoSQL-хранилища Apache Hive, которое реализует возможность обращения к данным в...

Для обучения дата-инженеров и аналитиков данных, сегодня рассмотрим приемы оптимизации SQL-запросов в Apache Hive, выполняемых движком Tez. Каким образом Tez рассчитывает оптимальное количество редукторов, зачем включать индексацию фильтров, как статистика таблицы помогает улучшить план выполнения запросов и что за конфигурации нужно менять. 3 движка выполнения запросов в Apache Hive Напомним,...
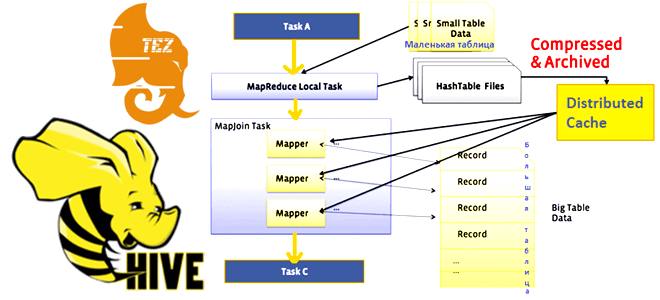
В этой статье для обучения дата-инженеров, аналитиков данных и разработчиков распределенных приложений рассмотрим один из методов оптимизации SQL-запросов в Apache Hive. Что такое оператор MapJoin, в каких условиях и как он работает, чем выгоден для HiveQL-запросов и почему при его выполнении с движком Tez может возникнуть нехватка памяти. Что такое...
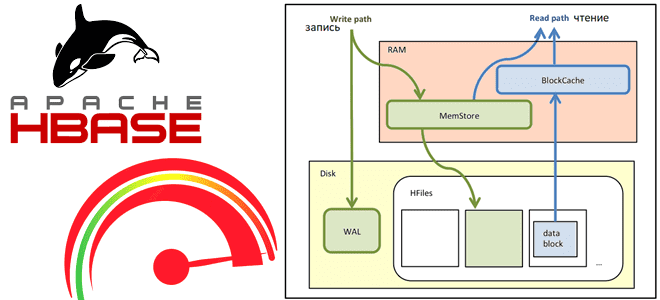
Сегодня рассмотрим, как выполняются операции чтения и записи в Apache HBase, а также с помощью каких приемов можно их ускорить. Как рассчитать оптимальное количество регионов в таблице, зачем отключать версионирование, почему размер ключа строки должен быть небольшим и еще 7 полезных лайфхаков для администратора HBase-кластера. Оптимизация записи данных в Apache...

Что такое архитектура данных, какие модели чаще всего используются в современных Big Data системах, почему традиционные BI-системы не справляются со всем разнообразием текущих бизнес-сценариев, чем Лямбда отличается от Каппа, а Data Fabric от Data Mesh и зачем внедрять MLOps-инструменты в аналитическую платформу. Немного истории: почему архитектуры данных до сих пор...

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...
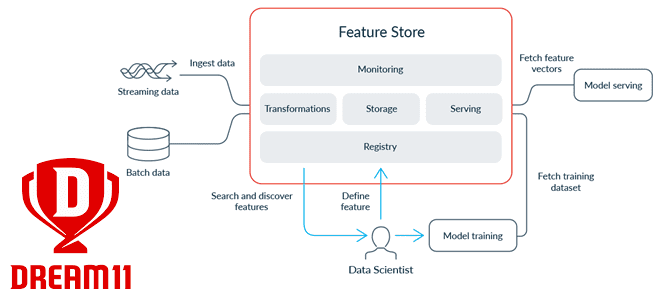
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...
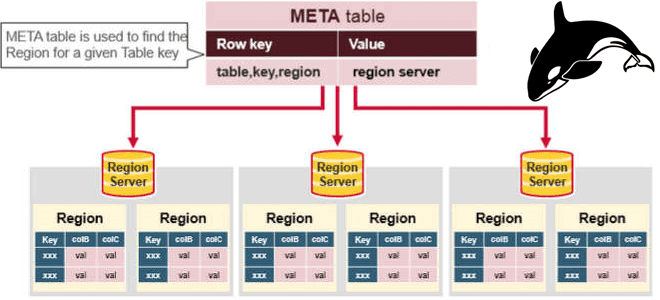
Сегодня затронем тему администрирования кластеров Apache HBase и рассмотрим, приносит ли реальную пользу совместное размещение нескольких региональных серверов (RegionServer) на одном узле кластера. Сравнительный анализ по тестам YCSB-бенчмарка. Регионы и сервера Apache HBase Напомним, Apache HBase является популярной колоночной NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности...
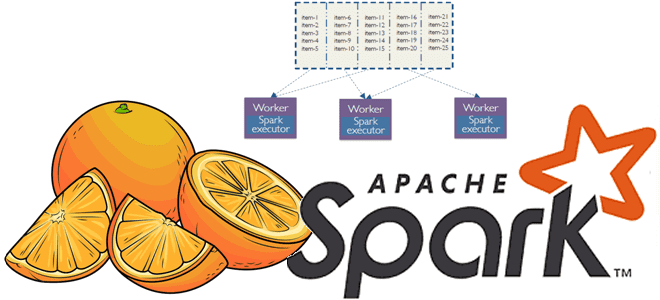
Мы уже рассказывали про функции перераспределения данных по разделам coalesce() и repartition(). Сегодня сравним их работу с еще одним методом управления разделами в Apache Spark и разберем, как все они могут помочь дата-инженеру и разработчику распределенных приложений повысить эффективность этого популярного фреймворка аналитики больших данных. Отобрать и поделить: лучшие практики партиционирования данных...

Как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0: тонкости установки и конфигурирования для обучения администраторов кластера и инженеров с примерами команд и кода распределенных приложений. Запуск Spark-приложения на Hadoop-кластере Прежде всего, для настройки кластера Apache Spark нужен работающий кластер Hadoop. Сама установка и настройка выполняется в 2...

В этой статье для дата-инженеров и администраторов кластера рассмотрим, как считать данные из распределенной файловой системы Apache Hadoop в MPP-СУБД Greenplum. Архитектура и принцип работы PXF-коннектора к HDFS с примерами команд. Интеграция Greenplum и Hadoop через PXF-коннекторы Мы уже писали, что представляет собой интеграционный фреймворк PXF (Platform Extension Framework), который...

Сегодня заглянем под капот Apache Spark и разберем, для чего этому популярному вычислительному движку база метаданных, как ее назначить и что не так с хранилищем данных по умолчанию. Зачем уходить от Apache Derby к Hive и как это сделать: краткий ликбез с примерами для обучения дата-инженеров и разработчиков распределенных приложений....

Продолжая рассматривать примеры для обучения дата-инженеров по построению ETL-конвейеров, сегодня разберем, как перенести данные из облачного объектного хранилища AWS S3 в озеро данных на Hadoop HDFS с помощью готовых процессоров Apache NiFi. Такой кейс актуален для многих предприятий, которым необходимо мигрировать с сервисов Amazon в другие хранилища больших данных. Перенос...

Недавно в Google Dataproc появился бессерверный Apache Spark. Разбираемся, что это такое и зачем нужно дата-инженерам. Как работает serverless Spark в облачной платформе Google и почему выбирать между Dataflow и Dataproc стало еще сложнее. Блеск и нищета Google Dataproc Напомним, Google Dataproc – это облачный Hadoop, который работает аналогично другим...