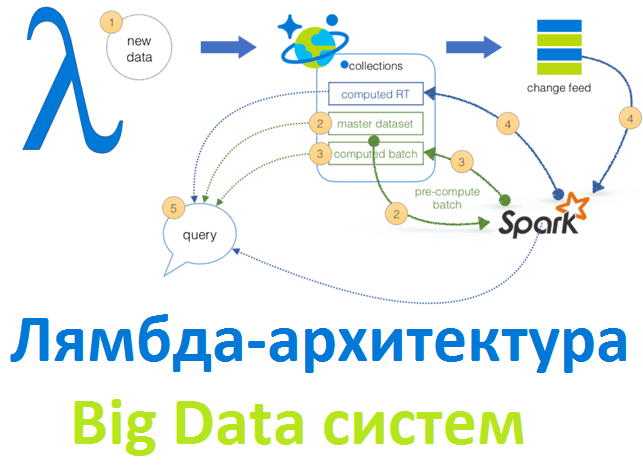
Рассматривая основы больших данных, сегодня мы расскажем лямбда-архитектуру, одну из двух главных подходов к построению Big Data систем. Читайте в нашей статье, зачем нужна эта концепция и как она работает, а также при чем тут машинное обучение, интернет вещей, Apache Spark и Hadoop. Что такое Лямбда-архитектура и зачем она нужна...

Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования. Чем хорош Apache AirFlow:...
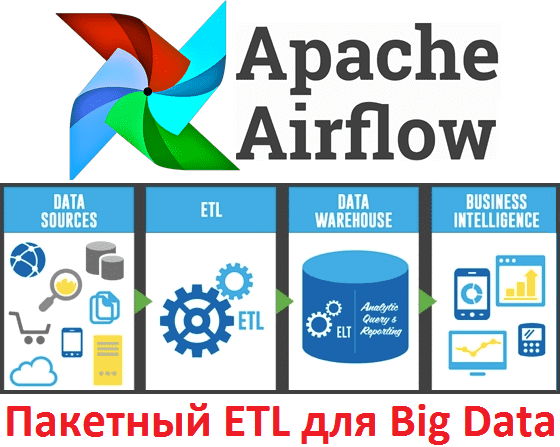
В этой статье мы поговорим про Apache AirFlow - эффективный инструмент для пакетных ETL-задач при работе с большими данными (Big Data): что это такое, как работает и чем полезен для инженера данных (Data Engineer). Также рассмотрим несколько практических примеров реального использования этой библиотеки для разработки, планирования и мониторинга batch-процессов. Что...
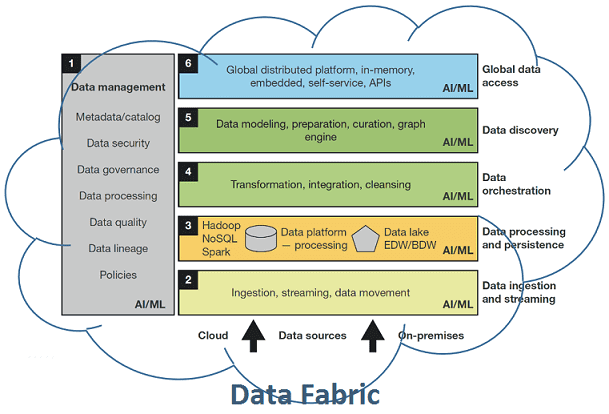
Сегодня мы рассмотрим, что такое Data Fabric, почему этот тренд в аналитике больших данных (Big Data) считается одним из самых перспективных в 2020 году, зачем нужна фабрика данных и как она устроена. Читайте в нашей статье, чем Data Fabric отличается от Data Factory, причем тут цифровизация, DataOps и конвейеры по...

Выбирая курсы по Spark, Hadoop, Kafka и другим технологиям больших данных, легко запутаться во многочисленных предложениях от различных учебных центров и платформах онлайн-обучения. Сегодня мы расскажем, что должна включать программа курса по Big Data, чтобы результат обучения оправдал ваши ожидания и даже превзошел их. 4 главных свойства эффективного курса по...

Обычно курсы по Spark подробно рассказывают, чем хорош этот Big Data фреймворк для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных. Но, чтобы обучение Apache Spark было максимально полезным, стоит знать и о недостатках этого многофункционального инструмента обработки больших данных. Сегодня мы рассмотрим некоторые проблемы, которые возникают при практическом...
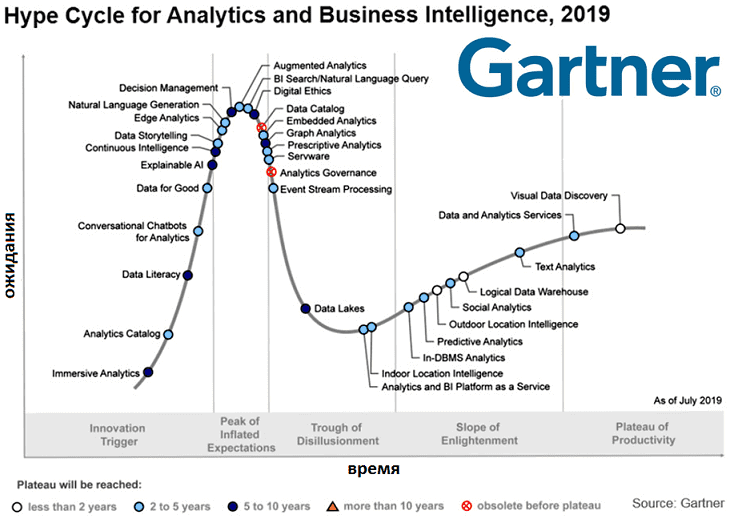
Сегодня мы поговорим, что такое Hype Cycle от самого известного аналитического агентства Gartner и как будут развиваться наиболее популярные сегодня ИТ-тренды в области больших данных (Big Data), управления данными (Data Management), машинного обучения (Machine Learning) и искусственного интеллекта (Artificial Intelligence). Что такое цикл зрелости технологий – Hype Cycle от Gartner...

Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...

Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России - ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big...

Сегодня рассмотрим, чем корпоративное обучение большим данным (Big Data) отличается от индивидуального. Читайте в нашей статье, почему образовательные курсы по Apache Kafka, Hadoop, Spark и другим технологиям Big Data сплотят ваших сотрудников лучше любого тимбилдинга и как повысить эффективность такого обучающего тренинга. Почему корпоративное обучение Big Data эффективнее индивидуальных курсов:...
Рассматривая практическое обучение Kafka, сегодня мы поговорим, зачем нужен Zookeeper и можно ли использовать Кафка без этой централизованной службы синхронизации распределенных сервисов. Читайте в нашей статье о роли Zoo в системах обработки больших данных (Big Data) и о том, может ли Apache Kafka эффективно работать без Zookeeper, а также как...

Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...

Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств. Что общего между Apache Cassandra и HBase: 5 главных сходств Прежде всего отметим, чем...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...

Сегодня мы рассмотрим еще один инструмент стека SQL-on-Hadoop: Apache Phoenix, позволяющий выполнять SQL-запросы к нереляционной СУБД HBase. Читайте в нашей статье, что представляет собой этот исполнительный механизм, как он работает и чем отличается от других Big Data решений подобного класса (Cloudera Impala, Apache Hive и Drill). Также мы собрали для...

Cloudera Impala – далеко не единственное SQL-решение для быстрой обработки больших данных (Big Data), хранящихся в среде Hadoop. C Impala часто сравнивают Apache Hive, однако они существенно отличаются в плане прикладного использования, как мы уже показали здесь. Гораздо ближе к Impala с точки зрения вычислительной модели и сценариев использования (use...
Завершая сравнение SQL-инструментов для больших данных (Big Data), хранящихся в среде Hadoop, сегодня мы рассмотрим аргументы в пользу Apache Hive и Cloudera Impala – когда стоит выбирать ту или иную систему и почему. Также в этой статье мы собрали для вас несколько практических примеров реального использования Импала и Хайв в...

Продолжая тему SQL-on-Hadoop, сегодня мы рассмотрим вопросы обеспечения информационной безопасности в Apache Hive и Cloudera Impala. Читайте в нашем материале, что такое RBAC, в чем специфика cybersecurity больших данных в экосистеме Hadoop и какие средства помогут защитить Big Data при работе с Hive и Impala. Что такое RBAC для SQL-on-Hadoop...